[color=rgba(255,255,255,var(--tw-text-opacity))]NVIDIA Blackwell Ultra 助力 AI 和 HPC 创新、效率和能力 [size=1.125]
2025 年 3 月 21 日 [img]https://images.prismic.io/bethtechnology/3998cc99-759f-4d20-8d4c-d4f9a1234670_IO+Fund+Logo+-+www.io-fund.com.png?auto=compress,format?w=256[/img]
投融资基金团队
 [color=rgba(255, 255, 255, var(--tw-text-opacity))][size=1.25][color=rgba(255, 255, 255, var(--tw-text-opacity))][size=1.25][color=rgba(255, 255, 255, var(--tw-text-opacity))][size=1.25] [color=rgba(255, 255, 255, var(--tw-text-opacity))][size=1.25][color=rgba(255, 255, 255, var(--tw-text-opacity))][size=1.25][color=rgba(255, 255, 255, var(--tw-text-opacity))][size=1.25]
[size=1.125]NVIDIA 的突破性硬件技术和 AI 正在释放前所未有的计算能力。在 NVIDIA GTC 2025 上,NVIDIA 在其 2025 GPU 技术大会 (GTC) 上发布了专为“推理时代”设计的Blackwell Ultra GPU。像 GPU 这样的 AI 加速器非常适合 AI 训练和推理,因为它具有并行处理功能,可以同时执行许多计算。前 500 台超级计算机中只有 30% 依赖加速计算;如今,80% 都依赖加速计算。绿色 500 超级计算机的能源效率排名显示出更加明显的趋势。  
[size=1.125]其中包括 NVIDIA Blackwell Ultra GPU 和 GB300 NVL72 服务器主要规格。 [size=1.125]来源:NVIDIA 推理时代的 Blackwell Ultra GPU[size=1.125]AI 推理模型模拟大脑如何思考得出结论,OpenAI 的 o1、Google 的 Gemini 2.0 Flash Thinking 和 DeepSeek 的 R1 A1 模型广为人知。推理模型可以改善对查询的响应,更强大的 GPU 可以提高这些模型的性能。Blackwell Ultra GPU 是 GB200 的下一代演进,具有更强的推理能力,在 1.1 exaFLOPS FP 密集计算中实现了 50% 的 FLOPS。  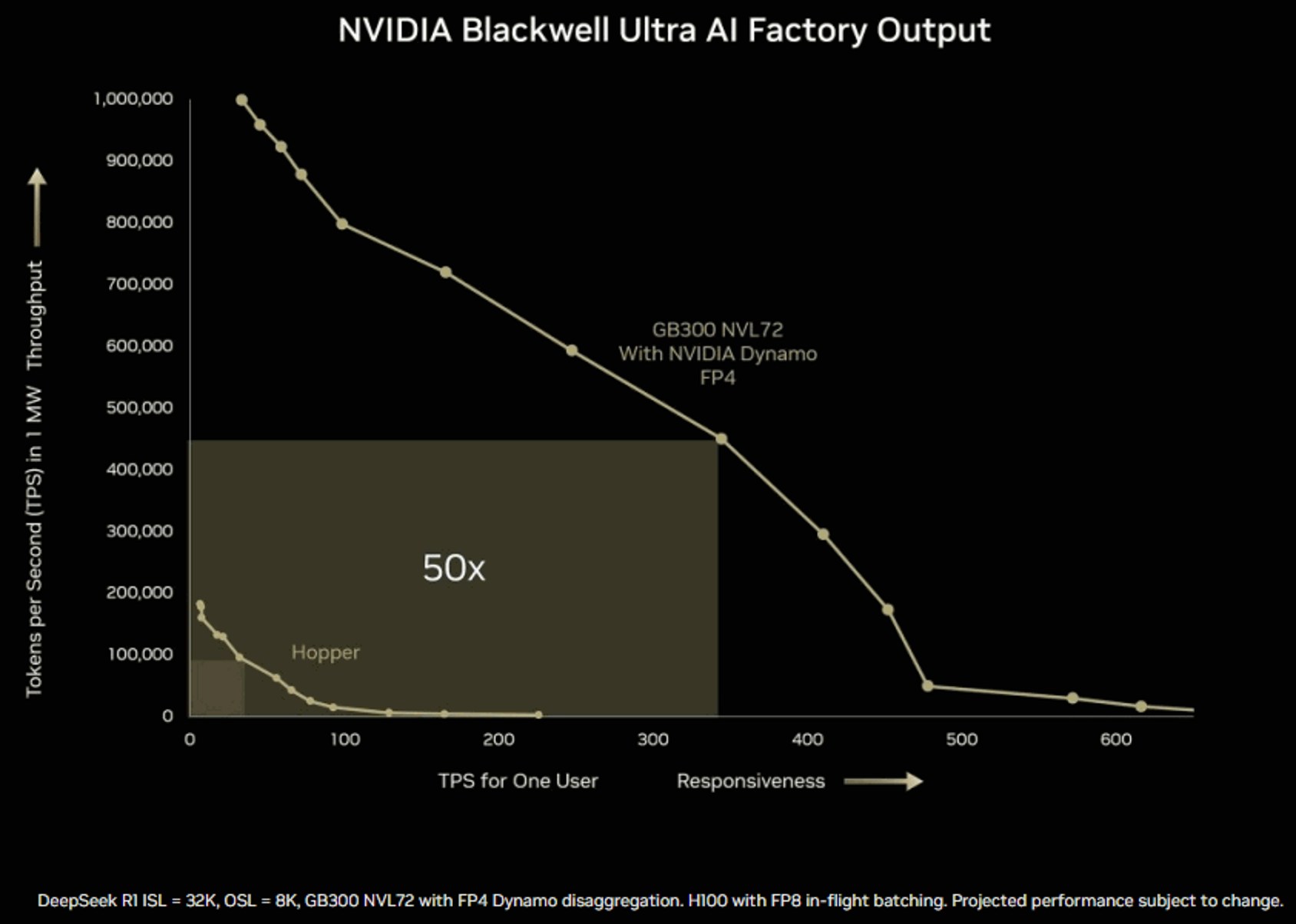
[size=1.125]NVIDIA Blackwell Ultra AI Factory 输出图表显示性能提高了 50 倍。 [size=1.125]来源:NVIDIA [size=1.125]在NVIDIA GTC 2025上, NVIDIA 超大规模和 HPC 计算副总裁 Ian Buck 在 3 月 18 日的演讲中表示:“Blackwell Ultra 将 GB200 的 40 倍数据中心收入机会提高到 50 倍”,并指出其更快的令牌服务和更高的吞吐量,非常适合对 DeepSeek 等模型进行后期训练,这些模型需要处理 100 万亿个令牌。 NVIDIA GB300 NVL72 释放推理能力[size=1.125]NVIDIA 的 GB300 超级芯片将两个 Blackwell Ultra GPU 与一个 Grace CPU 结合在一起。Blackwell Ultra GPU 可用于 NVL72 机架式服务器,该服务器集成了 72 个 Blackwell Ultra GPU 和 36 个 Grace CPU。NVIDIA GB300 NVL72 采用全液冷机架式设计。与 NVIDIA Hopper 平台相比,当与 NVIDIA Quantum-X800 InfiniBand 或 Spectrum-X 以太网搭配使用 ConnectX-8 SuperNICS 时,AI 工厂使用 NVIDIA GB300 NVL72 实现的推理模型推理输出比 NVIDIA Hopper 平台高出 50 倍。 Blackwell Ultra 的硅光子技术可将功耗降低高达 77%[size=1.125]NVIDIA 的 Blackwell Ultra GPU 使用硅光子学共封装光学元件,将光学和硅元件集成到单个基板上。这通过消除对外部激光器和可插拔收发器的需求来降低功耗,从而将功率从 39 瓦显著降低到 9 瓦。Buck 表示,硅光子学“……在端口数量相同的情况下,将功率从 30 瓦降低到仅 9 瓦,这带来了巨大的好处。听起来 39 瓦似乎不多。但如果在 AI 超级计算机中安装 400,000 个 GPU,则有 24 兆瓦的激光器,因此可以优化和提高效率的大量激光。” [size=1.125]加入成千上万信任 I/O Fund 对人工智能、半导体、加密货币和广告技术的专业股票分析的投资者 — 免费注册! 点击此处! [size=1.125]IO Fund 首席分析师 Beth Kindig 在其博客文章“ AI 功耗:迅速成为关键任务”中指出,“在我上个月对 Blackwell 架构的分析中,我指出这些估计太低,我的公司预计到 2025 年底,数据中心市场将达到 2000 亿美元,由 B100、B200 和 GB200 推动,包括以下几点: 台积电的 CoWos 产能对 Blackwell 架构至关重要,预计到 2024 年底将增至每月 40,000 台,与 2023 年底的每月约 15,000 台相比,同比增长超过 150%。应用材料公司已将 HBM​​ 封装收入预测从之前的 4 倍增长上调至今年的 6 倍。”” 下一代 CPU:Vera CPU:Grace 的继任者[size=1.125]NVIDIA 的下一代 CPU 是 Vera,是 Grace 的后续产品。Vera 拥有 88 个内核(通过空间多线程实现 176 个线程),性能提高了 2 倍,内存带宽提高了 5 倍/瓦,并为即将推出的 Rubin GPU 提供了更强大的芯片间链路。“每个内核都与其他内核对话,”Buck 强调道,这与 x86 的前端重点形成了鲜明对比。Vera 的 12 线程内存饱和度超越了传统 CPU,为 AI 和 HPC 后端任务提供 GPU 数据。Vera Rubin 将于 2026 年发射。Vera Rubin NVL 144 将于 2026 年下半年发射。仅供参考,Vera Rubin 是一位发现暗物质的美国天文学家。Rubin 将标志着 Rubin Ultra 从 HBM3/HBM3e 向 HBM4 和 HBM4e 的转变。 下一代 GPU 架构:Rubin Ultra[size=1.125]NVIDIA 将于 2027 年下半年推出 Vera Rubin NVL 576,其性能将是 GB300 NVL72 的 14 倍。Rubin 将拥有 1.2 ExaFLOPS 的 FP8 训练,而 B300 仅为 0.36 ExaFLOPS,从而将计算性能提高 3.3 倍。带宽将从 8 TB/s 提高到 13 TB/s。它将在一个机架中拥有 576 个 Rubin GPU。通过每个封装配备四个芯片,计算密度得到提升。Rubin Ultra NVL576 将拥有 365 TB 的内存。使用 FP4 的推理计算将上升到 15 ExaFLOPS,FP8 训练计算为 5 ExaFLOPS。NVIDIA 以天文学家 Vera Rubin 的名字暗示下一代架构将以理论物理学家 Richard Feynman 的名字命名。 [size=1.125]I/O Fund 最近入股了 5 支新的中小型股,我们认为这些股票将成为这场 AI 支出战的受益者。每周四下午 4:30,我们都会在我们的 1 小时网络研讨会上讨论入场、退出以及对大盘的预期。在限定时间内,使用代码 PRO110OFF 可享受年度专业计划 110 美元的折扣[在此处了解更多信息]。 [size=1.125]免责声明:这不是财务建议。购买任何股票时,请咨询您的财务顾问。
|

 IP卡
IP卡 狗仔卡
狗仔卡 发表于 2025-3-29 06:14:27
发表于 2025-3-29 06:14:27
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡