[color=rgba(255,255,255,var(--tw-text-opacity))]DeepSeek 为 Nvidia 股票创造买入机会[size=1.125]
2025 年 1 月 31 日 
贝丝·金迪格首席技术分析师
 [color=rgba(255, 255, 255, var(--tw-text-opacity))][size=1.25][color=rgba(255, 255, 255, var(--tw-text-opacity))][size=1.25][color=rgba(255, 255, 255, var(--tw-text-opacity))][size=1.25] [color=rgba(255, 255, 255, var(--tw-text-opacity))][size=1.25][color=rgba(255, 255, 255, var(--tw-text-opacity))][size=1.25][color=rgba(255, 255, 255, var(--tw-text-opacity))][size=1.25]
[size=1.125]本周早些时候,DeepSeek 导致人工智能股票大跌,英伟达市值蒸发逾 6000 亿美元,创下有史以来单日最大跌幅。这家来自中国的研发公司表示,该模型的训练成本为 600 万美元,这让市场陷入恐慌,因为与大型科技公司的支出相比,这只是九牛一毛。人们的反应是,转眼间,DeepSeek 从根本上改写了人工智能资本支出的故事。 [size=1.125]在 DeepSeek 挑战 OpenAI 之后,美国和中国在大型语言模型 (LLM) 方面的竞争被称为 AI 的斯普特尼克时刻。投资者对这一类比最重要的收获是,斯普特尼克号刺激了大规模投资。它不是最终目的地,而是数十年太空竞赛的开始。斯普特尼克号卫星的成本为 1500 万至 2000 万美元,如果考虑到成本调整后的通货膨胀率,则为 3300 万美元,但美国将在 60 年内花费约 1 万亿美元来应对。 [size=1.125]美国非常重视保持领先地位,而人工智能将引发一场前所未有的军备竞赛。想想看,政府花了 60 年时间才在太空竞赛上花费了 1 万亿美元(经通胀调整),然而在一项全面的立法中,美国将在 5 年内花费 5000 亿美元用于人工智能基础设施,而仅 2024 年就花费了 700 亿美元。 [size=1.125]请记住,正是市场所谓的“效率”导致英伟达股价因游戏相关失误而下跌 60%,此前有传言称以太坊与权益证明 (PoS) 的合并将成为该股的丧钟。就在此时,强大的 AI GPU Hopper 开始发售,它配备了一个 Transformer Engine,可以实现自学模型,并改变我们所知的世界。 [size=1.125]科技的定义是颠覆、成千上万的产品发布和众多竞争对手。当投资者被每日新闻所震惊时,它可能是一个嘈杂且成本高昂的行业。我的公司在 Nvidia 方面有着令人羡慕的业绩记录——包括在股价暴跌或供应链谣言期间直言不讳。这还包括告诉你我们何时不买入,或者股票何时出现泡沫,比如当 Nvidia 的交易价格为 140 美元时。我们也会不遗余力地告诉你我们何时计划再次买入。目前,你可以在 DeepSeek 上找到数十篇(也许数百篇)文章;然而,你很难找到另一个人帮助投资者如此细致地了解 Nvidia 的股票。 [size=1.125]下面,我将提供证据来证明 DeepSeek并不是一夜之间扼杀 Nvidia 的黑天鹅——事实上,降低 AI 开发成本一直是我们的计划——并且最终将在长期内促进 Nvidia 的销售,因为 AI 将离开数据中心,转移到企业内部和消费者设备上。 [size=1.125]我还谈到了投资者在未来 GPU 巨无霸的价格方面应该关注什么。 DeepSeek 的 DualPipe 算法[size=1.125]DeepSeek 的 DualPipe 算法优化了流水线并行性,从根本上降低了 GPU 节点通信和混合专家 (MoE) 利用方面的低效率。MoE 指的是将计算负载分配到“多个专家”(或神经网络)上,以使用所谓的模型和流水线并行性在数千个 GPU 上进行训练。这可以实现更高效的计算训练,但参数仍需要加载到 VRAM 中,因此内存需求仍然很高。 [size=1.125]Tom's Hardware一个月前就此发表了一篇文章,标题通常颇具预见性:“中国 AI 公司称突破性进展使创建尖端 AI 模型所需的计算量减少了 11 倍——DeepSeek 的优化可能凸显美国制裁的限制。”文章指出:“DualPipe 算法最大限度地减少了训练瓶颈,特别是对于 MoE 架构所需的跨节点专家并行性,这种优化使集群能够在预训练期间处理 14.8 万亿个 token,而通信开销几乎为零。” [size=1.125]DualPipe 允许将代币路由给专家,并通过名为 PTX(并行线程执行)的代码并行处理结果聚合,从而帮助降低成本。该软件实质上优化了硬件。该公司还创建了 4 个节点的最大值来限制节点并减少流量,从而实现更高效的通信框架。 [size=1.125]像 DeepSeek 这样的 MoE 模型可以提供许多好处,这就是 DeepSeek 所展示的——能够以更低的成本训练更大的模型,具有更快的预训练、更快的推理速度,并且能够降低第一个令牌的延迟。然而,MoE 也可能需要更高的 VRAM 来同时存储所有专家,并且在微调方面可能面临挑战。 混合点精度和多头潜在注意力降低内存使用量[size=1.125]DeepSeek 的成功还体现在通过多头潜在注意力降低内存使用率,将内存使用率降低到 5% 到 13%。MLA 最终通过处理长文本序列来减少推理过程中的内存需求。正如ML 工程师 Zain ul Abideen所指出的,“MLA 实现了比 MHA 更好的性能,并且显著降低了 KV 缓存,从而提高了推理效率。” [size=1.125]据估计, Hopper GPU 中 HBM3e 的组件成本可能比配备 HBM3 的 GPU 高出 25%,并且预计 HBM4 将由于提供更快数据速率的复杂性而增加更多成本。 [size=1.125]内存是一种昂贵的组件,Hopper 以内存容量有限而闻名,只有 80GB HBM3e 内存,而 Blackwell 的 HBM3e 内存为 192GB(即将发布的版本内存几乎是后者的 2.5 倍)。因此,减少内存使用量是优化 Hopper GPU 的一种方法。 [size=1.125]DeepSeek 的成功还源于其开创性的模型架构方法。该公司推出了一种新颖的 MLA(多头潜在注意力) 方法,将内存使用量降低到更常见的 MHA 架构所消耗内存的 5%-13%。 [size=1.125]Nvidia 的硬件卓越性在配备 Transformer Engine 的 Hopper 一代 GPU 中脱颖而出。两年前,Hopper 的 Transformer Engine带来了 Chat-GPT 的辉煌时刻,因为 OpenAI 模型消除了在数学上寻找元素之间模式的需要,这开启了可以使用哪些数据集以及使用速度的大门。 [size=1.125]H100 还利用变换器引擎实现混合精度,例如 FP8、FP16 或 FP32,具体取决于工作负载。Nvidia 设计了在浮点精度点之间切换的能力,以减少内存使用量。以下是Nvidia 的说法: [size=1.125]“使用精度低于 32 位浮点的数值格式有许多好处。首先,它们需要的内存更少,从而可以训练和部署更大的神经网络。其次,它们需要的内存带宽更少,从而加快了数据传输操作。第三,数学运算在降低精度的情况下运行速度更快,尤其是在具有 Tensor Core 支持的 GPU 上。混合精度训练实现了所有这些好处,同时确保 与全精度训练相比不会丢失任何 特定于任务的准确性。它通过识别需要全精度的步骤并仅对这些步骤使用 32 位浮点,而在其他所有步骤中使用 16 位浮点来实现这一点。” [size=1.125]DeepSeek表示,FP8 使其能够“同时实现加速训练和减少 GPU 内存使用”,因为它验证了 FP8 可用于以极低的成本训练大规模模型。大多数“计算密度最高的操作都是在 FP8 中进行的,而一些关键操作则策略性地保留了其原始数据格式”,例如那些由于敏感度原因需要更高精度的操作。 [size=1.125]虽然低精度训练经常“受到激活、权重和梯度中异常值的限制”,而且测试表明FP8训练容易出现更高的不稳定性以及更频繁的损失峰值,但由于硬件的进步(例如 Hopper 带来强大的 FP8 支持,Blackwell 带来 FP4),它现在正成为一种高效训练的解决方案。 [size=1.125]DeepSeek 还为未来芯片适应低精度训练并大规模复制提供了建议,建议芯片设计应“增加 Tensor Core 中的累积精度以支持全精度累积,或根据训练和推理算法的精度要求选择合适的累积位宽。” [size=1.125]这就是 Blackwell 的设计初衷,它与 Hopper 相比,具有新的 Tensor Cores 精度、FP4 精度、更高的 SM 数量和更多的 CUDA 核心。Blackwell 还集成了 2080 亿个晶体管,可提供高达 20 petaflops 的 FP4,而 H100 的 FP8 仅为 4 petaflops。B200 具有支持 4 位浮点 (FP4) 的第二代 Transformer 引擎,目标是在保持准确性的同时,将内存可支持的模型的性能和大小翻倍。 [size=1.125]为了简单地重现 DeepSeek 的训练效率并开发大规模模型,Hopper GPU 是必需的,因为它支持 FP8,而 Blackwell 则带来 FP4 来为万亿参数模型提供实时推理和增强训练。 [size=1.125]理解 Nvidia 硬件的细微差别是我在 2018 年底首次提出 Nvidia 的 AI GPU 论文和 CUDA 护城河的原因,而在 2019 年,Volta 的 AI 功能促使我在我的 高级股票研究 网站上说:“我相信到 2030 年 Nvidia 将成为世界上最有价值的公司之一。” 这为我们的免费读者带来了超过 4,000% 的潜在收益。 布莱克威尔不是霍珀[size=1.125]这似乎是人工智能软件大获全胜的时刻,然而我们正处于 Hopper 一代的末期,H100(以及限制更多的 H800)GPU 已经上市两年了。在人工智能军备竞赛中,两年是永恒的,而 Hopper 在 Blackwell 出货的那一刻达到优化的顶峰,这并不是一个令人震惊的新发现——相反,这是保持快节奏产品路线图的关键。根据 Nvidia 的 Computex 主题演讲,从 Pascal 到 Blackwell,他们的人工智能系统将实现“人工智能计算能力提高 1,000 倍”,同时将“每个令牌的能量降低 45,000 倍”。 [size=1.125]因此,市场有些困惑,认为软件优化带来的 11 倍计算量增长会让 Nvidia 措手不及。以下是 H100 和 GB200 NVL72 系统在混合专家 (MoE) 实时吞吐量和训练速度方面的差异。  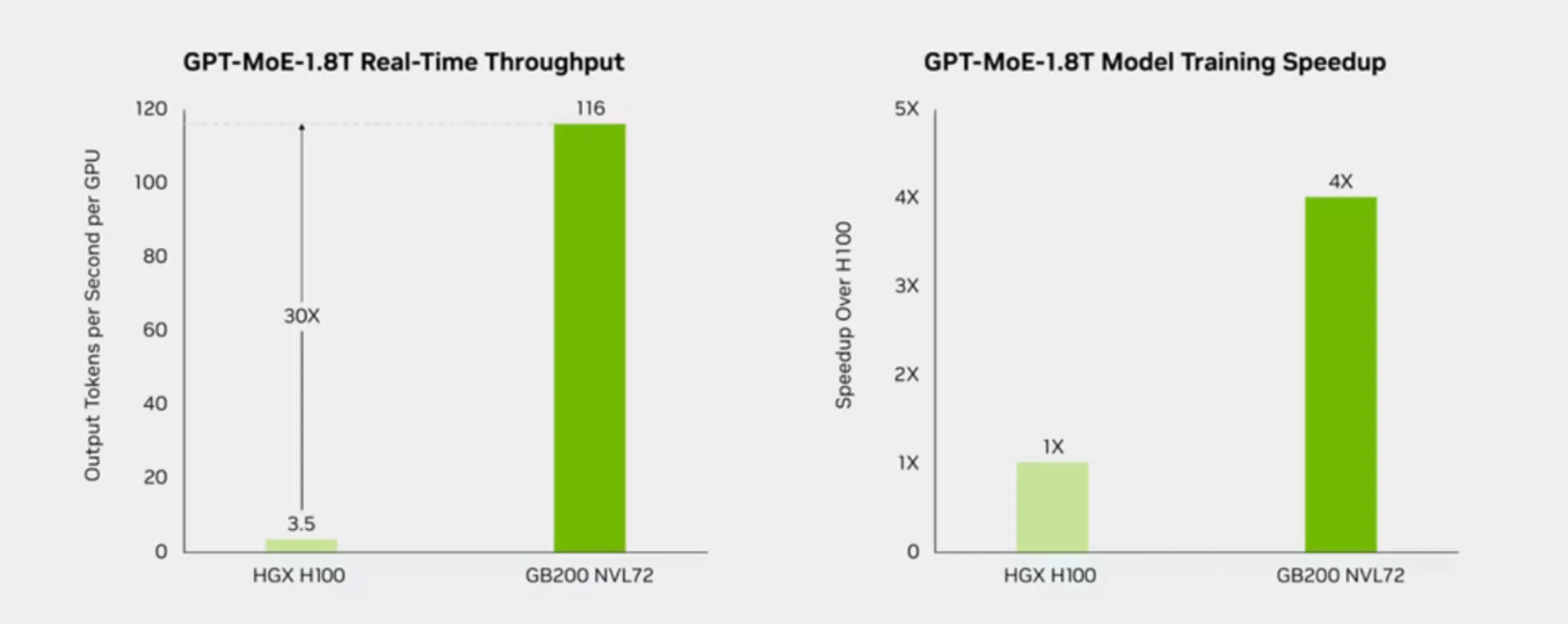
[size=1.125]DeepSeek 承认,他们在部署模型时面临的限制“有望随着更先进硬件的发展而自然解决”。请注意,他们并不是说随着更先进软件的发展而解决。 [size=1.125]大约一年前,我就指出Nvidia 正在用一年的产品发布路线图与 Nvidia 竞争,我曾说过:“产品路线图是投资者应该关注的最重要的事情。目前,人们已经了解了 AI 加速器故事的很大一部分。但人们不了解的是,Nvidia 将其下一代 GPU 的发布周期从两年缩短到一年,这是多么激进的行为。” [size=1.125]此外,通过开源模型,将有更多的开发者可以构建新的AI功能。根据Predibase的分析,在短短几天内,就有500个DeepSeek衍生模型被创建出来。 [size=1.125]Nvidia 很早就意识到了这一最终结果,推出了 Project Digits,这是一台价值 3,000 美元的超级计算机,可以运行 2000 亿参数模型。通过发布功能强大的个人电脑,Nvidia 寻求其 GPU 的普及——就像苹果的 iPhone 一样——而像 OpenAI 这样的公司则面临着开源 LLM 的最大挑战,因为开源 LLM 可以降低输入令牌和输出令牌的成本,比 OpenAI 的 o1 模型便宜 27 倍。 布莱克威尔推动美国迈向通用人工智能(AGI)[size=1.125]软件尚未正式开始将硬件商品化,距离这一刻可能还要 5-10 年,这是因为人工智能的发展还处于非常早期的阶段。Blackwell 和未来几代 GPU 是人工智能发展离通用人工智能 (AGI) 的起点越来越近的必需品。 [size=1.125]有讨论质疑是否有可能通过强化学习实现 AGI:“如果代理试图在复杂的环境中最大化奖励,那么就可以实现通用人工智能,因为环境的复杂性将迫使代理学习复杂的能力,如社交智能、语言等。” [size=1.125]强化学习是一种机器学习方法,其中代理或模型通过与环境的互动(通过奖励或惩罚)来学习做出决策。代理将与环境互动,获得正面或负面的奖励,并根据收到的反馈调整其决策/行动。 [size=1.125]AGI 指的是创造一种能够像人类一样执行智力任务的机器,并且能够理解、学习并将知识应用于广泛的领域。RL 和 AGI 都涉及从与环境的交互中学习,尽管 RL 通常更侧重于特定任务或环境,而 AGI 旨在“包罗万象”。 [size=1.125]如果说中国的软件效率可以与 Sputnik 媲美,那么 AGI 的到来将是我们登上月球的那一刻。AGI 需要更大数量级的模型——至少 1 万亿,最多10 万亿或更多。强化学习无疑是朝着正确方向迈出的一步,但万亿以上的参数模型是不可避免的——这需要 Nvidia 和其他 AI 加速器设计公司来实现。  
[size=1.125]来源:DeepSeek R-1上图:DeepSeek 发布后,Nvidia 的市值一天内蒸发 6000 亿美元,其性能和推理能力的基准测试超过了 OpenAI。 DeepSeek 很便宜......是吗?[size=1.125]DeepSeek 表示,V3 在预训练中对 14.8 万亿个 token 进行了训练,每 1 万亿个 token 在其 2,048 个 H800 集群上需要 180K H800 GPU 小时(3.7 天)。相比之下,Meta 的 4050 亿参数 Llama 3.1 模型在 16,384 个 H100 GPU 集群上训练了 54 天(30.8M GPU 小时),按 2.6 美元/小时的租赁价格估计成本约为 8000 万美元。 [size=1.125]假设 H800 的租赁价格为 2 美元/小时,这占了成本的大部分,为 532.8 万美元(这与 Lambda 的 H100 的长期合同价格大致相同,但比其他初创云提供商的短期成本低约 20%)。 [size=1.125]DeepSeek 预计 600 万美元的成本与 OpenAI 的 GPT-4 和 Alphabet 的 Gemini Ultra 的预计培训成本相比也只是九牛一毛。  
 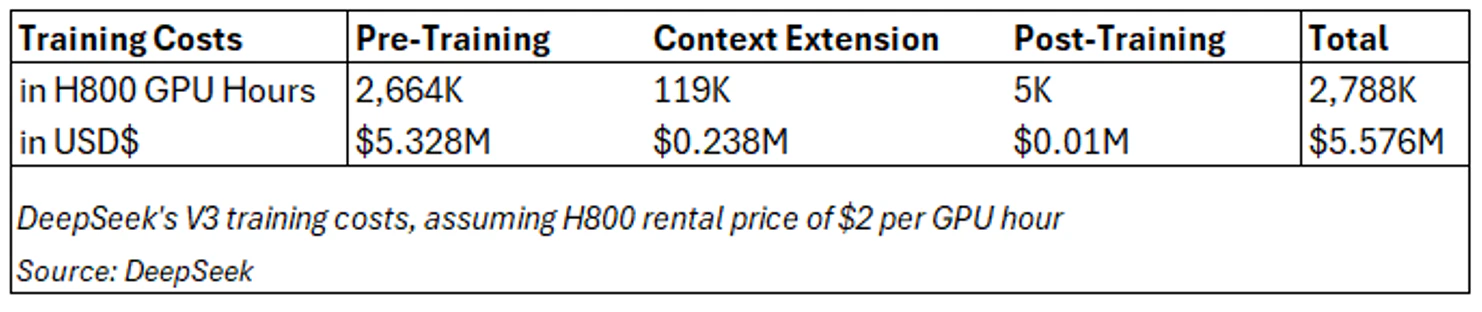
[size=1.125]来源:DeepSeek [size=1.125]虽然培训成本是利用租赁价格估算的(并且有待商榷),但值得注意的是,560 万美元的成本仅不包括“与架构、算法或数据的先前研究和消融实验相关的成本”。 人工智能民主化助力英伟达[size=1.125]Nvidia 的目标不仅仅是向大型科技公司出售 GPU。相反,所有科技公司都在寻求巨大的潜在市场,而人工智能的民主化将帮助 Nvidia 实现人工智能设备在全球范围内的普及。 [size=1.125]与此同时,Blackwell 已售罄。微软本周表示,他们在云端的供应仍然受限,而 Azure 需要更多的供应才能实现增长。Meta 将其 2025 年的计划资本支出翻了一番,并表示愿意在长期内向 AI 基础设施投入“数千亿美元”。 [size=1.125]从中期来看,英伟达将向企业和边缘 AI 分配供应,因为较低的成本将促进企业 AI 和边缘计算的发展。市场开始担心这些大型 AI 投资不会有投资回报,另一方面,当成本降低到可以实现投资回报的程度时,市场现在感到恐慌。 [size=1.125]这一直是 Nvidia 的目标,首席执行官黄仁勋和其他高管在 CES 和 GTC 等高调舞台上宣称,每一代 GPU 的推出都会降低计算成本。在 GTC 2024 上,黄仁勋解释说,Nvidia“算法加速得如此之快,以至于计算的边际成本在过去十年中大幅下降,从而推动了生成式人工智能的出现。”他进一步解释说,降低计算成本和加速计算是 Nvidia“核心谋生方式”,“我们制定的定价始终从 TCO 开始。” [size=1.125]Nvidia 副总裁 Ian Buck在 2024 年 6 月的美国银行 GTC 会议上证实了这一点:“这里的机会是帮助 [客户] 通过固定兆瓦数据中心以最佳成本获得最高性能并针对成本进行优化。”
[size=1.125]订阅 I/O Fund 的免费新闻通讯,受益于 Nvidia 的出色表现,收益最高可达 2600% -点击此处 英伟达的收益报告值得关注什么[size=1.125]关于 Blackwell 供货的传言似乎没有尽头,2025 年 1 月又有一条传言。据台积电管理团队称,“削减订单,不会发生这种情况。实际上 [它] 会继续增加。” [size=1.125]以下几点让我们相信布莱克威尔的收入很快就会出现: [size=1.125]1)Nvidia 首席执行官黄仁勋在 CES 上再次确认Blackwell 已全面投入生产,并补充道“目前每家云服务提供商的系统均已启动并运行。” [size=1.125]2) 首席财务官 Colette Kress 在第三季度财报中表示:“Blackwell 的需求量惊人,我们正在竞相扩大供应量,以满足客户对我们的巨大需求。客户正准备大规模部署 Blackwell。” [size=1.125]3) 首席财务官 Colette Kress 在第三季度表示:“尽管需求大大超过供应,但随着我们对供应的了解不断增加,我们有望超过之前对 Blackwell 数十亿美元的收入预期。” [size=1.125]4) 瑞银 (UBS) 全球技术大会首席财务官 Colette Kress 表示:“就本季度即将上市的 Blackwell 而言,我们认为供应可能也存在限制,这将持续几个季度,直到下一个财年结束。因此,我们不认为会出现放缓。我们继续看到巨大的需求和兴趣,尤其是针对即将推出的新架构。”瑞银分析师 Tim Arcuri 补充道,“实际上,Blackwell 的出货量比三个月前预想的要多。” [size=1.125]5)首席财务官科莱特·克雷斯 (Colette Kress) 在 CES 上表示:“我们每个季度都能增加需求,同时增加收入。……当我们想到眼前的需求时,这绝对是一个增长的一年。” 大型科技公司的资本支出[size=1.125]两周前,我的公司报道了大型科技公司的资本支出(AI 支出)在 2024 年如何大大超出预期,并有望在 2025 年再次达到这一水平。回顾一下,分析师最初估计 2024 年大型科技公司的资本支出约为 2000 亿美元,同比增长约 30%。然而,我们最新的检查表明,大型科技公司有望在 2024 年至少花费 2360 亿美元的资本支出,比分析师的预期高出 18%,同比增长超过 52%。 [size=1.125]根据微软和 Meta 的初步承诺,到 2025 年,大型科技公司的资本支出将达到 3000 亿美元或更多,总计至少 1400 亿美元。这已经比分析师估计的 2800 亿美元高出约 7%,其中微软的 800 亿美元承诺比预期高出 40%,而 Meta 的 600-650 亿美元比预期高出 18% 以上。 [size=1.125]DeepSeek 强调了一个被忽视的主要利好因素——如果现在可以更快、更便宜地训练 AI 模型,那么它很可能会刺激对来自领先提供商的云端 GPU 实例的需求,因为 GPU 的租赁速度比建立新的基础设施要快得多。为了满足不断增长的需求,超大规模企业将需要继续购买甚至加速购买 Nvidia 的 GPU,以防止芯片限制阻碍收入增长。
分析师对 Nvidia 股票的预测保持不变[size=1.125]2024 年 6 月,在《为什么 Nvidia 的股票到 2030 年将达到 10 万亿美元的市值》的分析中,我讨论了由于数据中心收入继续超出预期,季度内分析师修正对于支持 Nvidia 大规模增长的重要性。 [size=1.125]如下图所示,6 月份 Nvidia 25 财年营收预估为 1200 亿美元,较上半年上调 31.5%。以美元计算,这比 913 亿美元增加了近 290 亿美元。6 月份 Nvidia 26 财年营收预估为 1575 亿美元,较 1088 亿美元增长 44.8%,六个月内增长近 500 亿美元。  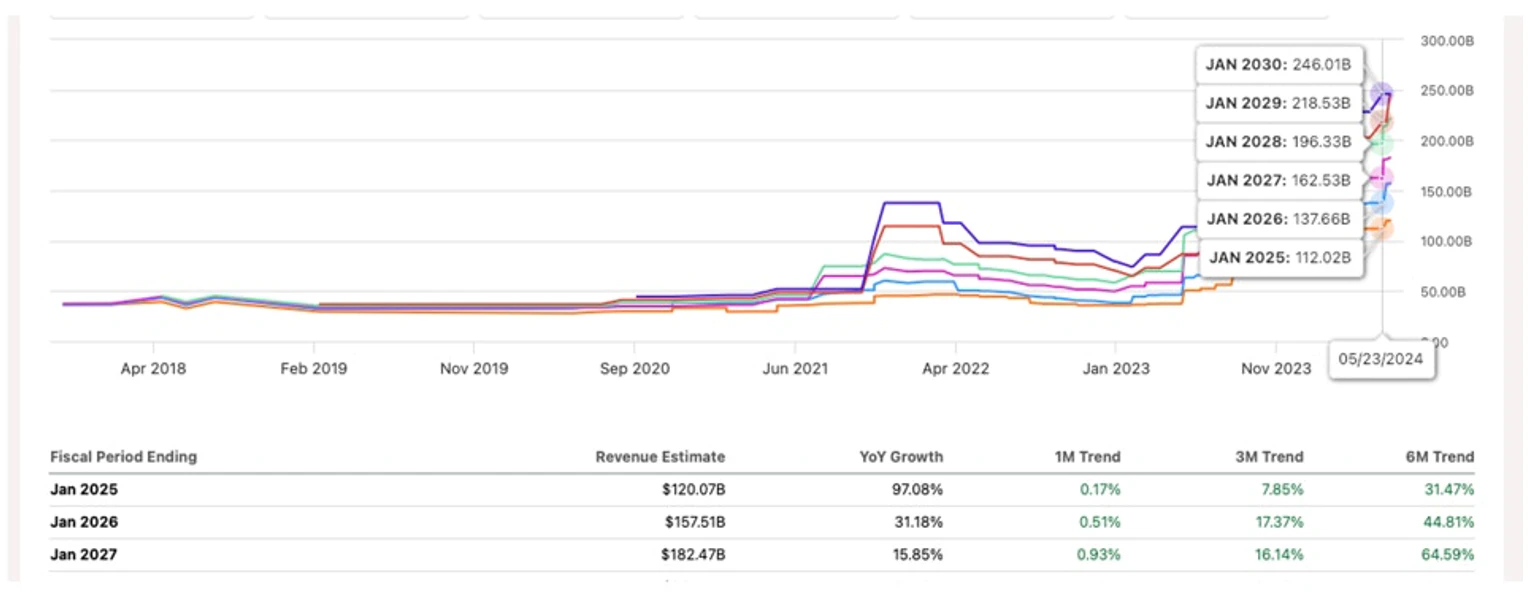
[size=1.125]与今天相比:  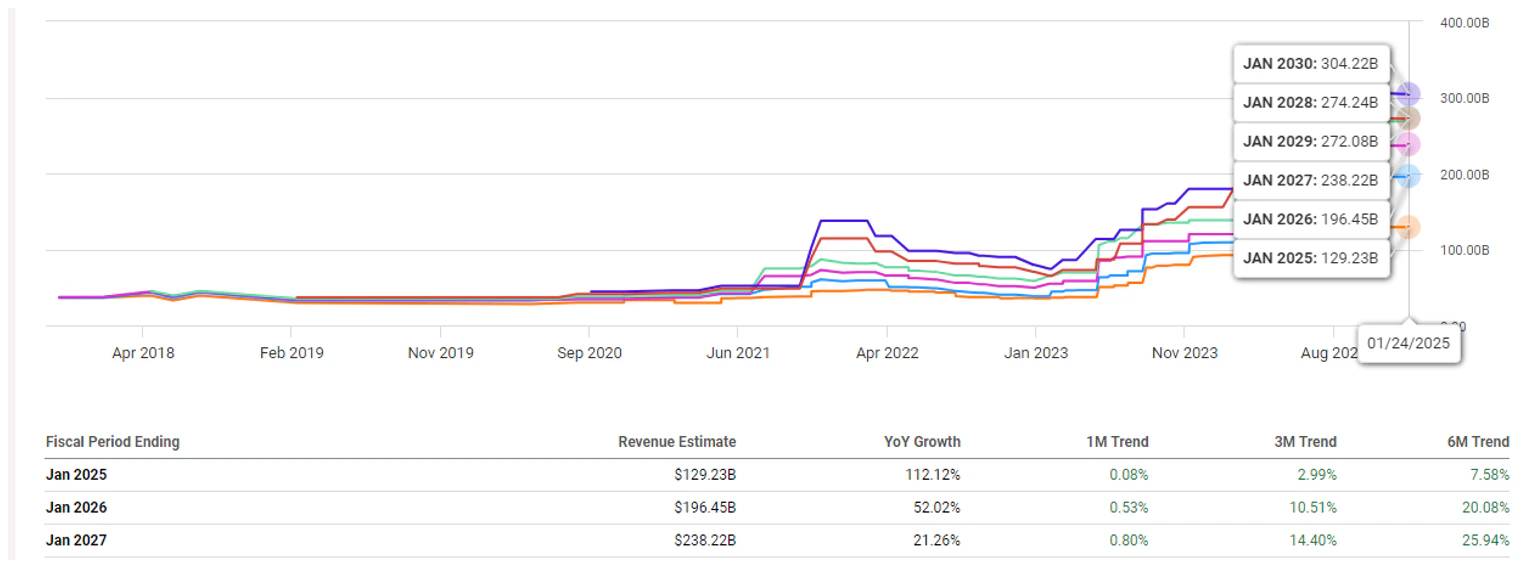
[size=1.125]2025 财年修正值自 7 月以来仅上涨 7.6%(或 90 亿美元),至 1292 亿美元,而 2026 财年收入则上涨 20%,至 1965 亿美元。这意味着过去七个月又增加了 395 亿美元(按目前的运行速度计算,相当于一个季度)。  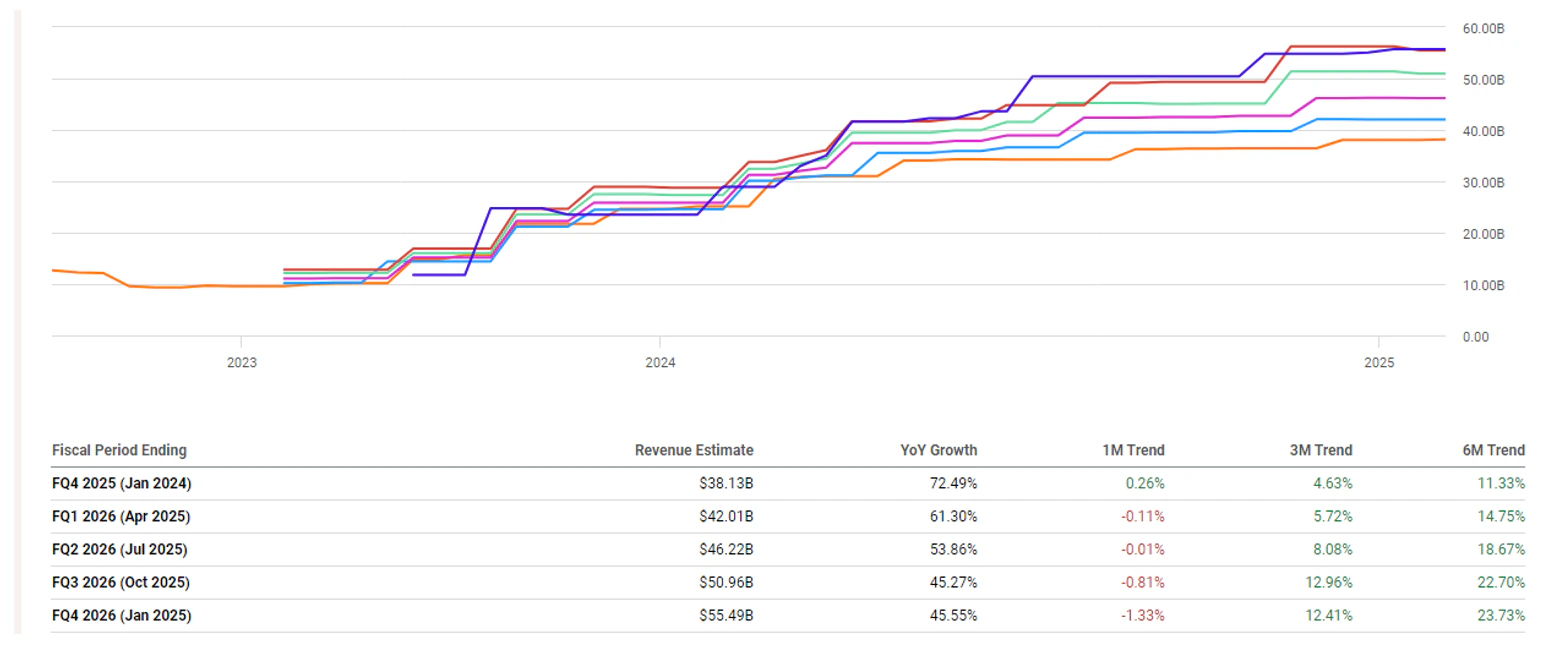
[size=1.125]抛开观点不谈,季度内修订将是你首先看到任何重大问题或对收入的影响的地方。FY26 季度修订在过去一个月略有下降,第四季度下降了 1.3%。到目前为止,DeepSeek V3 的发布没有带来任何影响——事实上,1 月 28 日的估计值略有上升,FY26 第四季度的收入从 554.9 亿美元上升到 555.1 亿美元。 [size=1.125]从更大角度来看,收入仍比六个月前高出 14% 至 24%。按这个规模计算,收入增长了 60 至 100 多亿美元。 Nvidia 股价下一步走势[size=1.125]让我们来谈谈价格目标。 [size=1.125]在“我计划下一步在哪里购买 Nvidia 股票”一文中,我们指出 Nvidia 至少还需要再上涨一次才能完成当前的上升趋势。这将使 2024 年 6 月开始的波动成为更大上升趋势中的修正。 [size=1.125]我们仍然相信 NVDA 的上涨趋势尚未结束。我们坚持上一份报告中概述的两种情景;这两种情景仍然有效。 [size=1.125]“蓝色——第五波的最后部分呈现为结束对角线模式,这在第五波中很常见。这种模式本身就是一个 5 波模式,其特点是双向大幅波动。我们对第四波底部的目标区域是 126 美元 - 116 美元。如果 Nvidia 能够突破 140.75 美元,那么这种情况就很有可能发生。 [size=1.125]红色 – Nvidia 正处于更为复杂的第四波。如果这种情况持续下去,NVDA 将跌破 116 美元的水平,从而可能跌至 101 美元、90 美元或 78 美元的低点。”  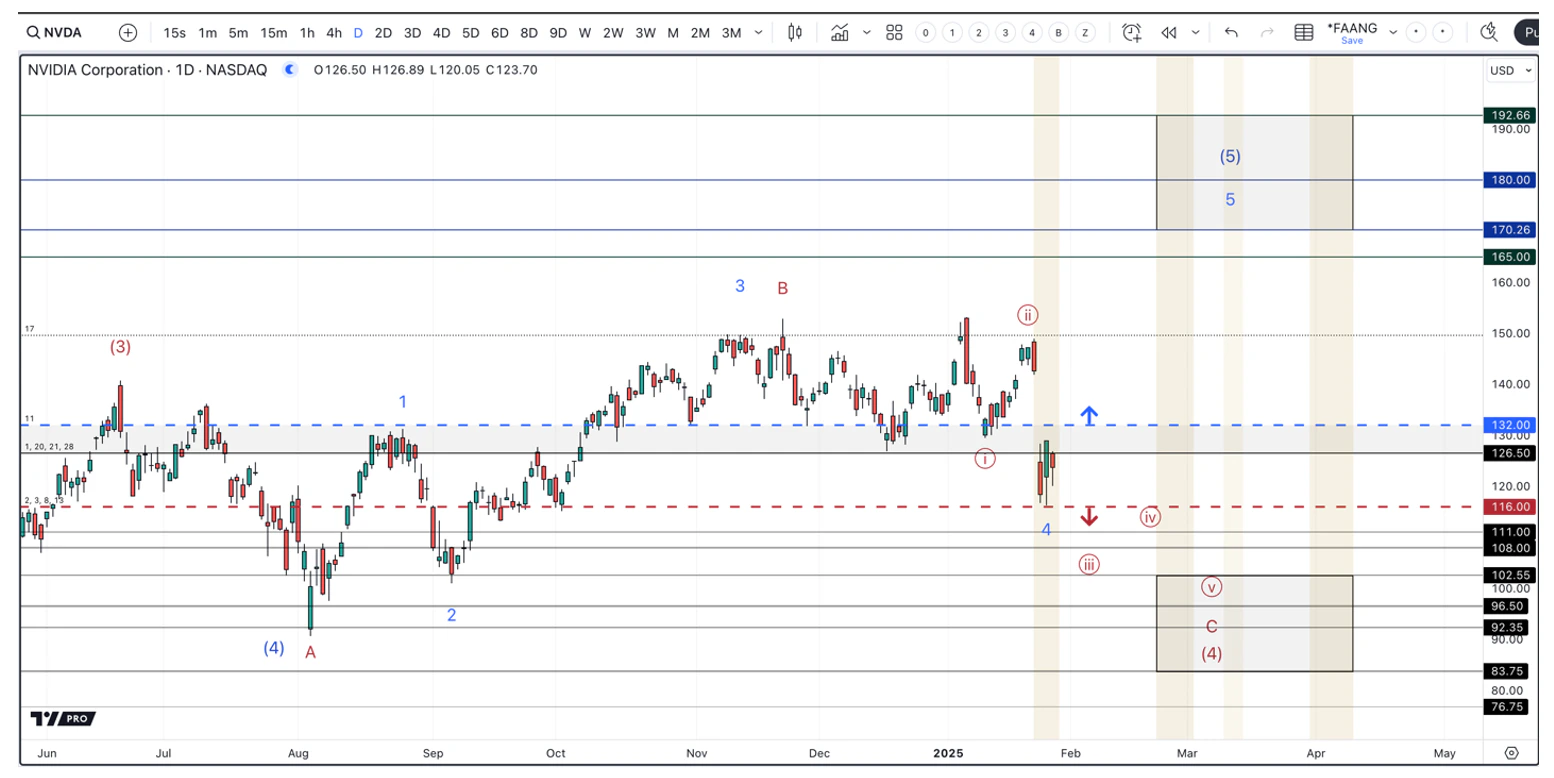
[size=1.125]虽然从我们上次的分析来看,116 美元的支撑位仍然有效,但目前值得关注的阻力位是 132 美元。如果 Nvidia 能够突破 132 美元的阻力位,那么其股价将立即转向蓝色区域。这将推动其在未来几个月内进入 170 美元至 190 美元的区域。 [size=1.125]另一方面,如果 Nvidia 跌破 116 美元的支撑位,则表明更直接的看跌趋势正在结束。这将使我们在未来几个月内在 102 美元至 83 美元的范围内创下有意义的低点。 [size=1.125]我们开始执行当前的买入计划,即在关键水平买入 Nvidia。126 美元 - 116 美元区域是我们的第一个目标。如果突破 116 美元区域,我们将瞄准 102 美元 - 83 美元区域以完成买入。考虑到蓝色计数正在寻找第五波的最终上涨,我们可能不会追逐 132 美元以上的突破。 结论[size=1.125]如果 DeepSeek 的突破真的是开启 AI 训练新范式、并最终通过降低成本实现 AI 民主化的关键,那么它对 Nvidia 来说并不会意味着死刑;事实上,恰恰相反。 [size=1.125]这就是杰文斯悖论——Hopper 和 Blackwell 的技术进步将转化为 AI 训练效率的显著提升和成本的降低,进而推动 AI 服务的普及——从而增加数据中心、企业本地以及边缘设备对 GPU 的需求。 [size=1.125]市场认为,大型科技公司目前在人工智能方面投入过多。然而,I/O 基金认为这种解读是错误的;这并不是说美国投入过多,而是我们将加快支出以保持领先地位。I/O 基金最近入股了五家新的中小型股公司,我们认为这些公司将成为这场人工智能支出战的受益者。我们每周四下午 4:30 在我们的 1 小时网络研讨会上讨论进入、退出以及对大盘的预期。点击此处了解更多信息。
|

 IP卡
IP卡 狗仔卡
狗仔卡 发表于 2025-2-15 09:27:04
发表于 2025-2-15 09:27:04
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡