2020.9.2日,NVIDIA发布会上发布了新一代基于安培架构的30系显卡,瞬间引发了整个科技圈的火热讨论。几乎无敌的3090,碾碎2080Ti的3080,以及能战平2080Ti的3070,不由得感叹这次牙膏挤得实在是太多了。
现在让我们着眼于显卡的另外一个适用领域——深度学习,让我们看看这代显卡对于深度学习的影响有多大。同时,也会列出不同显卡的性能对比、性价比等可视化图表方便大家阅读以及对于不同使用场景所需要的显卡进行推荐。
话不多说直接上干货!
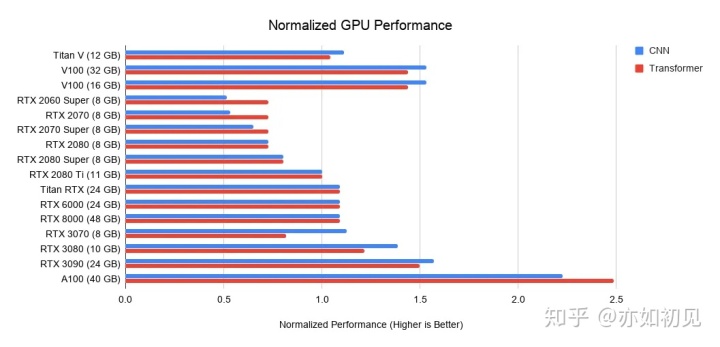
图形处理器深度学习性能下面的基准不仅包括特斯拉 A100 vs 特斯拉 V100的基准,而且建立了一个模型,适合这些数据和四个不同的基准,分别基于 Titan V 、Titan RTX、RTX 2080 Ti和 RTX 2080。
除此之外,通过在这些基准数据的数据点之间插值,对 RTX 2070、 RTX 2060或 Quadro RTX 6000 & 8000卡之类的中间卡进行了缩放。通常,在一个体系结构的GPU中,相对于流多处理器和带宽而言,规模是线性的,本文的体系结构内模型就是基于这一点。
这里只收集了用于混合精度 FP16训练的基准数据,因为没有充分的理由应该使用 FP32训练。
2080Ti作为性能基准与 RTX 2080 Ti 相比,RTX 3090卷积网络的加速比为1.57倍,变压器的加速比为1.5倍,同时发行价格高出15% 。因此,相比于图灵 RTX 20系列安培 RTX 30提供了一个相当实质性的改进。
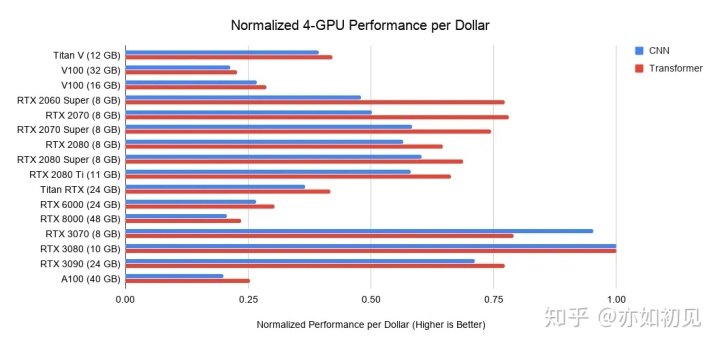
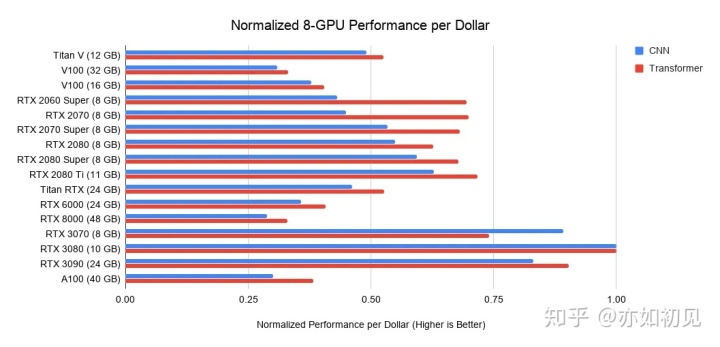
哪一款显卡是性价比最高的?这里有三个PCIe 3.0版本,使用它们作为2/4 GPU 系统的基本成本。采取这些基本成本和加上 GPU 的成本在它之上。对于新的安培 gpu,这里只使用发布价格。再加上上面的性能值,这将为这些GPU系统产生每美元的性能值。对于8-GPU 系统,使用了超微系统ー RTX 服务器的行业标准ー作为基准成本。请注意,这些条形图并不考虑内存需求。你应该首先考虑你的显存需求,然后在图表中寻找最佳选项。下面是一些关于显存的粗略指南:
- 使用预先训练的transformers; 从头开始训练小型transformers> = 11GB
- Training large transformer or convolutional nets in research / production: >= 24 GB 在研究/生产中培训大型transformers或卷积网络: > = 24GB
- 原型化神经网络(变压器网络或卷积网络) > = 10GB
- Kaggle比赛 >= 8 GB
- 应用于计算机视觉 > = 10GB
以3080作为基准
以4张3080为基准
以8张3080作为基准那么我们该如何选择显卡?我们需要一下步骤进行考虑:
- 我想用 GPU 做什么: Kaggle 竞赛,学习深度学习,小项目的程序员(GAN-fun 或大语言模型?)、从事计算机视觉/自然语言处理/其他领域的研究或其他工作?
- 我需要多少显存来完成我想做的事情?
- 使用上面的成本/性能图表来找出哪个 GPU 最适合你,满足显存条件。
- 对于我选择的 GPU,是否还有其他的注意事项?举例来说,如果是 rtx3090,我可以把它放进我的电脑吗?我的电源供应单元(PSU)是否有足够的瓦数来支持我的 GPU?散热会是一个问题吗,或者我能以某种方式有效地冷却 GPU 吗?
什么时候需要 > = 11gb 的内存?
我之前提到过,如果你使用transformers,你至少应该有11gb 的内存,如果你研究transformers,你最好有 > = 24gb 的内存。这是因为大多数以前的模型,预先训练有相当大的内存需求,这些模型训练至少 RTX 2080 Ti显卡,有11gb 的内存。因此,如果小于11gb,就会产生很难或不可能运行某些模型的情况(爆显存)。
其他需要大量内存的领域包括任何医学成像,一些最先进的计算机视觉模型,任何具有非常大的图像(GAN,风格转移)。
一般来说,如果你想建立一个在竞争中具有优势的模型,无论是研究、产业还是 Kaggle 的竞争,额外的内存将为你提供一个可能的优势。
小于11gb 的内存什么时候可以?
3070和 RTX 3080都是很强大的卡片,但是它们缺少一点内存。但是,对于许多任务,您并不需要这么大的内存。
3070是完美的,如果你想学习深度学习。这是因为大多数架构的基本训练技能可以通过缩小一点或使用一点小的输入图像来学习。如果我再次学习深度学习,我可能会使用一个 RTX 3070,如果我有足够的钱,甚至会使用多个 RTX。
RTX 3080目前是最具成本效益的卡,因此是原型设计的理想选择。对于原型设计,您需要最大的内存,这仍然很便宜。对于原型开发,我指的是在任何领域的原型开发: 研究、竞争激烈的 Kaggle、为创业公司提供创意/模型、实验研究代码。对于所有这些应用程序,RTX 3080是最好的 GPU。
假设你领导一个研究实验室/创业公司。我会把我的预算的66-80% 在 RTX 3080机器和20-33% 的“推出” RTX 3090机具有强大的水冷却设置。这个想法是,rtx3080更具成本效益,可以通过一个 slurm 集群设置作为原型机共享。因为原型开发应该以敏捷的方式完成,所以应该使用更小的模型和数据集。3080是完美的这一点。一旦学生/同事有了一个很棒的原型模型,他们就可以在 rtx3090机器上展示原型,并按比例扩大到更大的模型。
购买建议:整体上最优秀的GPU: RTX 3080和 RTX 3090。
避免使用的GPU: 所有的Tesla卡; 所有的Quadro卡; 所有的Founders Edition卡; Titan RTX、 Titan v、 Titan XP。(它们真的太贵了。。。。。)
性价比优秀但价格较贵: RTX 3080。
性价比优秀并且便宜: RTX 3070,RTX 2060Super。
手里资金较少: 可以购买二手卡(2080ti:WDNMD.....)。可以在闲鱼上看看,30系显卡开售了以后,20系显卡应该就会迎来真正的跳水了,不过注意二手交易安全。
囊中羞涩: 有很多初创公司在宣传他们的云计算: 使用免费的云计算积分和转换公司账户,直到你能负担得起一个 GPU。
参与Kaggle: RTX 3070。
有竞争力的计算机视觉,预训练,或机器翻译研究员: 4 x RTX 3090。建立良好的冷却系统,并确认足够的权力去使用。
NLP 研究员: 如果你不从事机器翻译,语言建模,或任何类型的预训练,一个 RTX 3080将是足够的和成本效益。
开始进行深度学习,并且想持续探索这个领域: 从 RTX 3070开始。如果你在6-9个月后仍然十分热衷,卖掉你的 rtx3070,并购买4卡rtx3080。根据你接下来选择的领域(创业、 Kaggle、研究、应用深度学习) ,卖掉你的 gpu,三年后买一些更合适的(下一代 RTX 40s gpu)。
想尝试深度学习,但不一定持续探索这个领域: RTX 2060super是优秀的,但可能需要一个新的电源供应使用。如果你的主板有一个 PCIe x16插槽,并且你有一个大约300w 的电源供应,GTX 1660 是一个很好的选择,因为它不需要任何其他的计算机组件来与你的桌面计算机一起工作。
GPU 集群用于少于128个 GPU 的并行模型: 如果您被允许为您的集群购买 RTX GPU: 66% 8x RTX 3080和33% 8x RTX 3090(只有在保证/确认足够冷却系统的情况下)。如果 RTX 3090 的冷却不够,购买33% RTX 6000 gpu 或8张Tesla A100代替。如果你不被允许购买 RTX gpu,我可能会选择8 x A100 Supermicro 节点或8 x RTX 6000节点。
图形处理器集群用于跨越128个 GPU 的并行模型: 考虑8张Tesla A100设置。如果你使用超过512个 gpu,你应该考虑使用一个符合你规模的 DGX A100 SuperPOD 系统。


 IP卡
IP卡 狗仔卡
狗仔卡 发表于 2021-1-16 20:11:20
发表于 2021-1-16 20:11:20


 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡 楼主
楼主


