人工智能随着核心算法、计算能力的迅速提升,以及海量联网数据的支持,在本世纪终于迎来了质的飞跃,人工智能将是未来应用最广泛的技术之一,在市场经济领域带来更多的机遇与机会,在医学领域可以大大加快诊断速度和准确性,在军事领域人工智能武器将成为未来武器的王牌……
(一)了解深度学习算法
深度学习两个主要过程:训练(Training)和推理(Inference)。其中:
训练(Training)是将大量数据加载到机器中并分析数据以建立用于分类,识别,预测等的模式的过程(已建立的模式称为训练后的模型),训练需要高速密集并行计算---“高性能计算”

推理(Inference)是将未知数据输入到通过学习过程创建的训练模型中,然后根据已建立的模式对数据进行实际分类,识别和预测的过程,推理需要快速将推理结果转化为行动—“边缘计算”、实时要求高
深度学习是指多层神经网络上运用各种机器学习算法解决图像、文本、语音等各种问题的算法集合

(二)深度学习主流算法计算特点
2019年,Nvidia(英伟达)公司上市Turing架构的RTX系列的GPU卡,增加了Tensor张量计算单元,大幅提升了深度学习关键的矩阵乘法计算、卷积计算(借助张量Tensors),GPU卡性能的关键指标:Tensor张量核数、显存带宽、FP16/FP32计算精度
目前可选GPU型号(2020年1季度)的主要技术参数
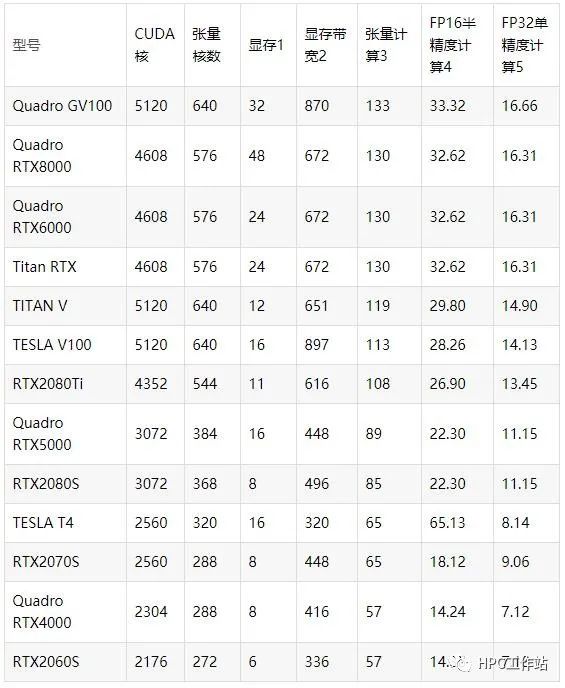
标注1 显存单位GB,标注2 显存带宽单位GB/s,标注3-5 单位Tflops(每秒万亿次)
应用1 CNN(卷积神经网络)计算特点
这类应用主要是计算机视觉应用,计算机获得对图像的高级“理解”。为了评估模型是否真正“理解”了图像,研究人员开发了不同的评估方法来衡量性能
主要算法:卷积神经网络(CNN)
CNN主要模型:AlexNet,VGG,GoogleNet, ResNet, Inception 等
主流深度学习框架:Theano、Caffe、MXNet、TensorFlow、Torch/Pytorch
CNN多GPU并行计算特点:非常理想
利用GPU加速主要是在conv(卷积)过程上,conv过程可以像向量加法一样通过CUDA实现并行化。具体的方法很多,最好的是用FFT(快速傅里叶变换)进行快速卷积,NVIDIA提供了cuFFT库实现FFT,复数乘法则可以用cuBLAS库里的对应的level3的cublasCgemm函数。
GPU加速的基本准则就是“人多力量大”。CNN说到底主要问题就是计算量大,但是却可以比较有效的拆分成并行问题。随便拿一个层的filter来举例子,假设某一层有n个filter,每一个需要对上一层输入过来的map进行卷积操作。那么,这个卷积操作并不需要按照线性的流程去做,每个滤波器互相之间并不影响,可以大家同时做,然后大家生成了n张新的谱之后再继续接下来的操作。既然可以并行,那么同一时间处理单元越多,理论上速度优势就会越大。所以,处理问题就变得很简单粗暴,就像NV那样,暴力增加显卡单元数(当然,显卡的架构、内部数据的传输速率、算法的优化等等也都很重要)。
GPU计算性能出众的根本原因是处理矩阵算法能力的非常强大,CNN中涉及大量的卷积,也就是矩阵乘法等,所以在这方面具有优势,GPU上的TFLOP是ResNet和其他卷积架构性能的最佳指标。Tensor Core可以显着增加FLOP,使用卷积网络,则应首先确定具有高GPU张量计算能力的优先级,然后分配高FLOPs的CUDA数量,然后分配高内存带宽,然后分配具有FP16位精度数据
CNN硬件配置要点:Tensors> FLOP> 显存> 半精度计算(FP16)
GPU可选型号:
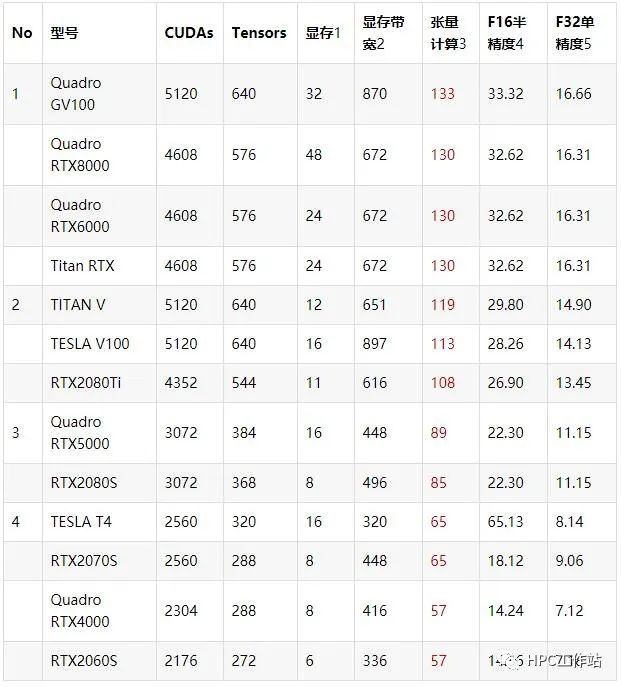
标注1—单位GB,标注2—单位GB/s, 标注3~5 ---单位TFlops
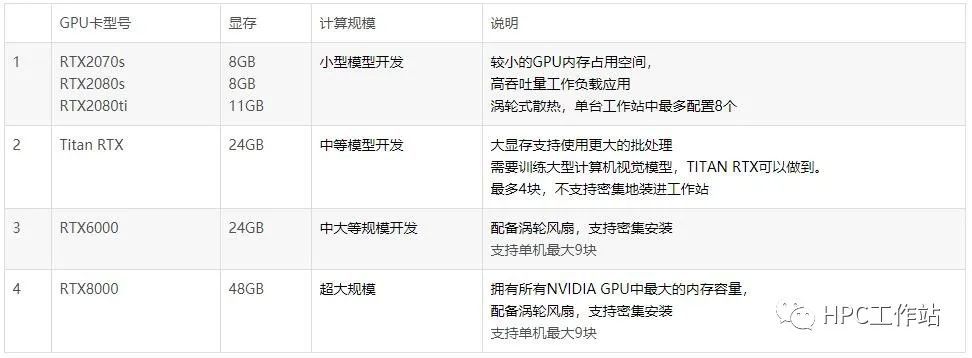
建议GPU:
应用2 RNN(循环神经网络)计算特点
这类典型应用主要是自然语言处理(NLP),包括语音识别,语言翻译,语音转文本和Q&A系统。
主要算法:RNN(包括变体: LSTM、GRU、NTM、双向RNN等)、Transformer
主流框架:CNTK、Torch/PyTorch、Keras
多GPU并行计算:不明确,跟程序设计、算法、框架、SDK以及具体应用都有很大关系,一些应用CPU多核并行反倒更快。
RNN和LSTM的训练并行计算是困难的,因为它们需要存储带宽绑定计算,这是硬件设计者的噩梦,最终限制了神经网络解决方案的适用性。简而言之,LSTM需要每个单元4个线性层(MLP层)在每个序列时间步骤中运行。线性层需要大量的存储带宽来计算,事实上,它们不能使用许多计算单元,通常是因为系统没有足够的存储带宽来满足计算单元。而且很容易添加更多的计算单元,但是很难增加更多的存储带宽(注意芯片上有足够的线,从处理器到存储的长电线等)
GPU内存非常重要,因为诸如XLNet和BERT之类的transformer网络需要大量的内存才能达到最高的精度,考虑矩阵乘法A*B=C的一种简单有效的方法是受内存(显存)带宽限制:将A,B的内存复制到芯片上比进行A * B的计算要昂贵。这意味着如果您要使用LSTM和其他执行大量小矩阵乘法的循环网络,则内存(显存)带宽是GPU的最重要功能。矩阵乘法越小,内存(显存)带宽就越重要,介于卷积运算和小型矩阵乘法之间的transformer在整体求解过程环节中并行效率低,加快方式提升显存带宽和足够的显存容量
RNN硬件配置要点:显存带宽+显存> 半精度计算(FP16) > Tensors> FLOP
GPU可选型号

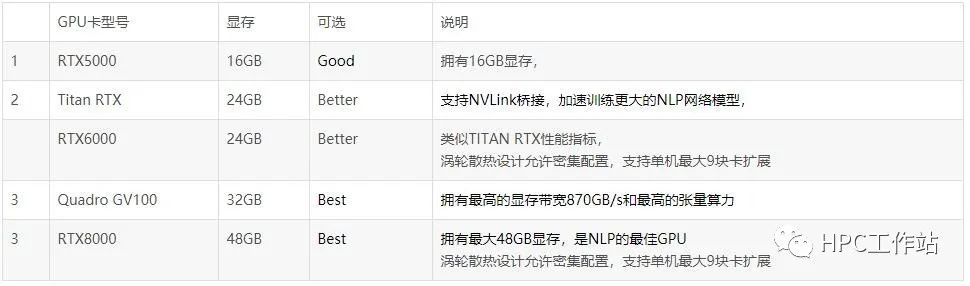
建议GPU:
(四)深度学习计算系统平台配备
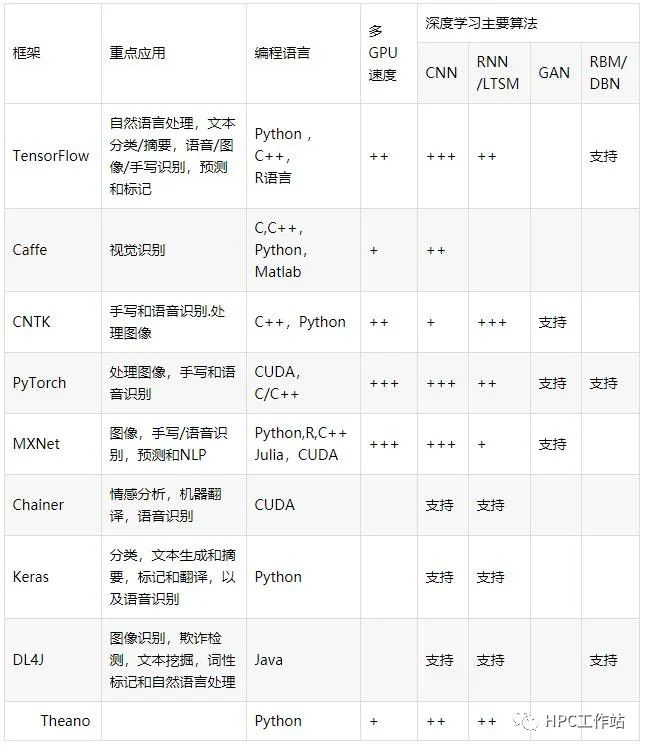
4.1深度学习框架对比
4.2 深度学习开发库SDK
开发环境:CUDA Toolkit
训练SDK:cuDNN (7.0版本支持Tensor Core)、NCCL、cuBLAS、cuSPARSE
推理SDK:TensorRT(版本3.0支持Tensor Core)、DALI
4.3 深度学习操作系统
操作系统:Windows 10 Pro 64位+ Ubuntu 18.04或RHEL 7.5
容器:Docker 18.06.1,NVIDIA Docker运行时v2.0.3
容器:RAPIDS容器
(五)深度学习计算硬件配置推荐
打造一个快速高效的深度学习计算平台,涉及到多方面因素:
(1)超算硬件设备-—GPU、CPU、内存、硬盘io…
(2)深度学习算法---CNN、RNN…
(3)深度学习框架---Tensorflow、PyTorch…
(4)开发库SDK---CUDA、cuDNN…
(5)程序设计算法优化—-张量单元、FP16精度数据计算、针对算法SDK优化、多卡并行优化算法…
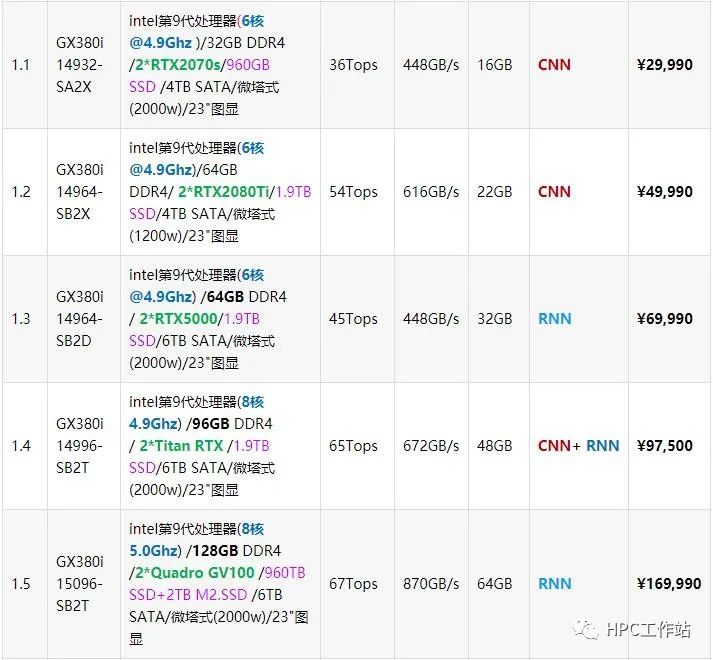
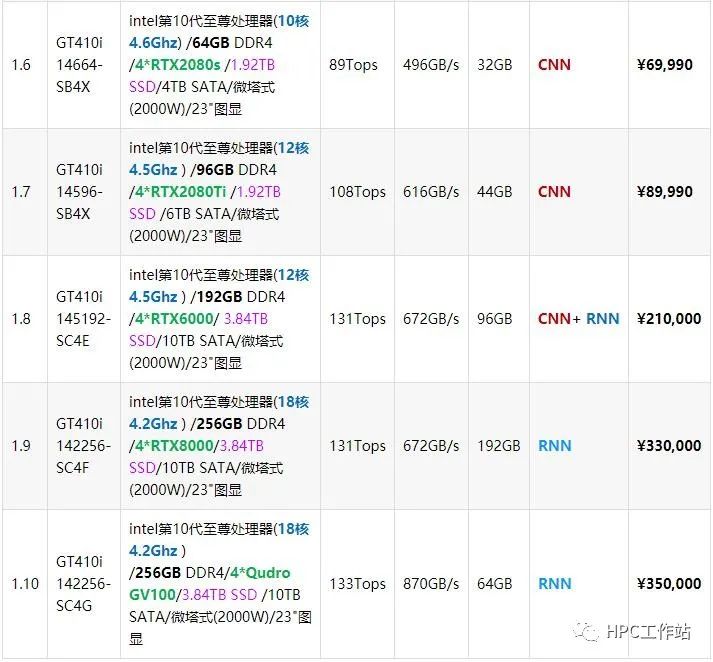
5.1 深度学习工作站配置推荐(科研类)
机型:UltraLAB GX380i/GT410
支持2~4块GPU卡
配备nvidia RTX---配置张量计算单元Tensor,支持intel AVX-512
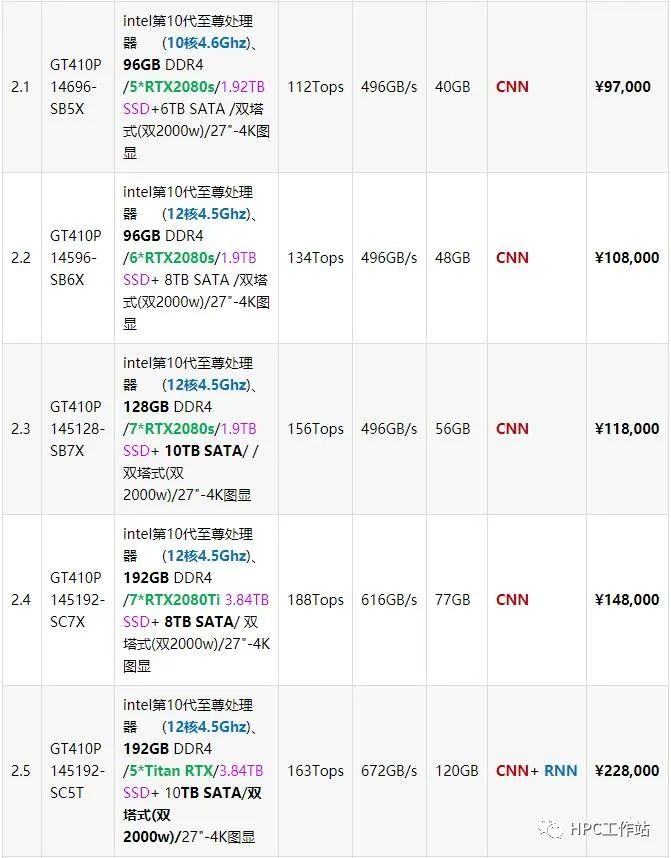
5.2 深度学习工作站配置推荐(高性能类)
机型:UltraLAB GT410P
支持支持5~7块GPU
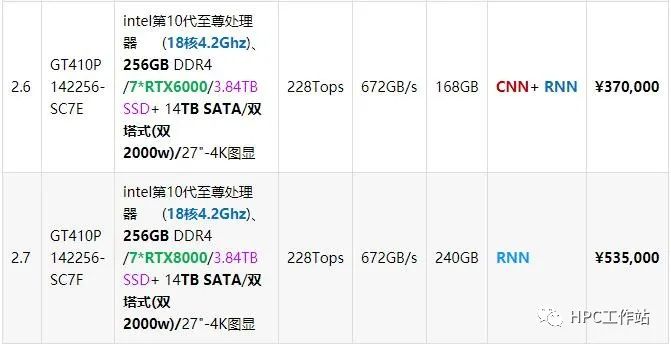
5.3 深度学习工作站配置推荐(超级类)
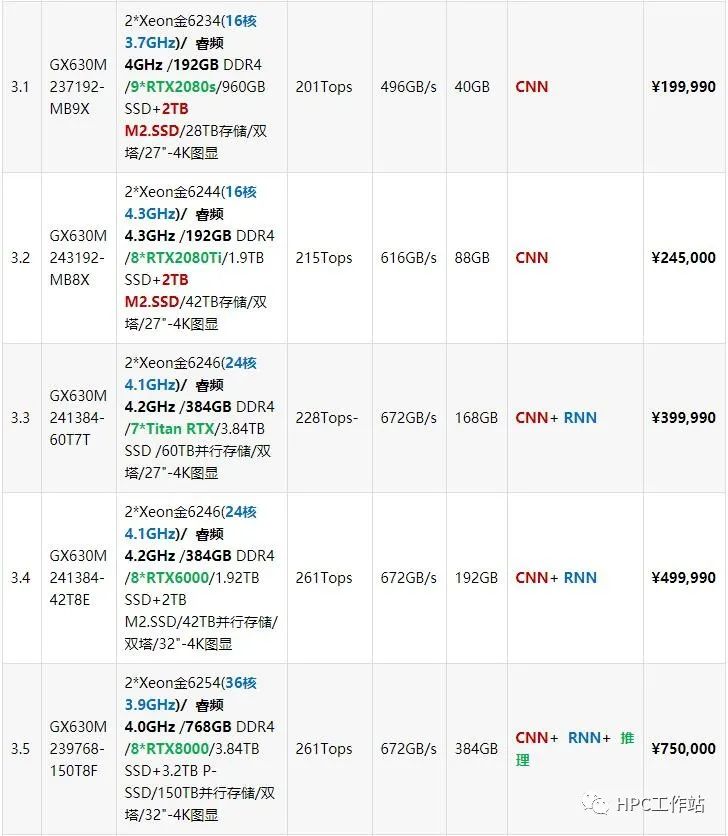
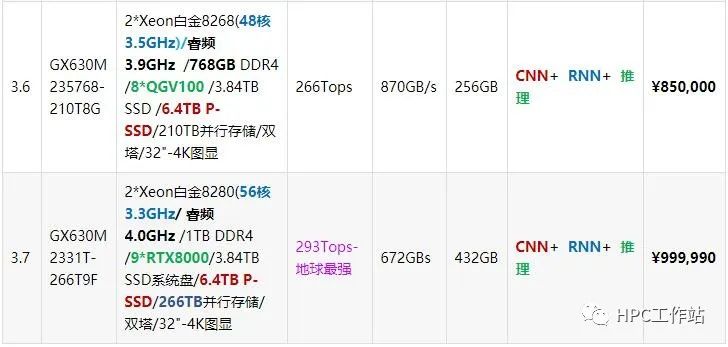
机型:UltraLAB GX630M)
支持8~9块GPU

 IP卡
IP卡 狗仔卡
狗仔卡 发表于 2020-11-21 12:55:07
发表于 2020-11-21 12:55:07
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡 PATHexport LD_LIBRARY_PATH=/usr/local/cuda-9.1/lib64
PATHexport LD_LIBRARY_PATH=/usr/local/cuda-9.1/lib64