12306.cn无疑是全球最繁忙的网站,每到特殊节日,这个世界上规模最大的实时交易系统都要面临巨大考验。2012年初的春运高峰期间,每天有2000万人访问该网站,日点击量最高达到14亿,大量同时涌入的网络访问造成12306几近瘫痪。
为了改变“逢节必瘫”的现状,铁路总公司从2012年6月开始选择Pivotal GemFire分布式内存计算平台对12306进行改造。如今3年过去,2015年铁路客票的春运早已结束,不难发现,与往年相比今年大家对12306吐槽的花边新闻少了很多。
在第六届中国数据库技术大会(DTCC 2015)的“内存数据库专场”中,中国科学院自动化研究所大数据应用部高级研究员杨旭钧为我们详尽解读了GemFire是如何帮助12306摆脱“饱受诟病”的命运。

▲中国科学院自动化研究所大数据应用部高级研究员杨旭钧
回顾GemFire的前世今生
1982年
GemStone Systems成立于美国俄勒冈州西北部城市比弗顿市。GemStone是领先的分布式数据管理技术软件公司,在此方面有着厚重的历史。最初使用Smalltalk语言开发出了第一代面向对象的数据库。并成为Smalltalk执行委员会成员。
1986年
第一代产品Gemstone/S 正式面世,受到金融市场的广泛欢迎。
90年代中后期
随着Java语言的广泛应用,GemStone与Sun公司合作,参与到JEE的规范制定(JCache -JSR107),并陆续更新与JEE平台相结合的产品。GemStone开发出了GemFire,成为业界第一个满足J2EE标准的中间件。GemFire拥有全新的应用框架,兼容Java, C++, C#。而GemFire在CEP(complex event processing),Event Stream Processing,Data Virtualization, Distributed Caching几个方面有着举足轻重的地位。
2008年初
金融危机后,金融监管法规Dodd-Frank、Basel3等陆续出台,各大投资银行为了减少系统风险和增加透明度,加强了金融衍生品交易平台的投资规模,Gemfire击败Oracle等老牌厂商,跻身为华尔街第一大分布式数据处理平台软件。
2010年5月
VMware收购了老牌厂商Gemstone,并入SpringSource部门。
12306的“双高挑战”
据杨旭钧介绍,在2015年春运高峰日,12306的PV值是297亿,流量较平时增加1000倍。
12306作为一个面向公众的系统,互联网售票系统具备所有大型互联网系统的特性:“高并发”, “高流量”。尤其是在我国的各个节假日,系统的访问量会激增,导致整个系统后台压力过大,响应变慢。
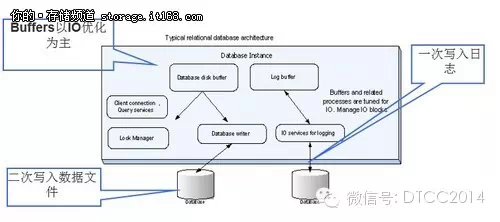
▲传统关系型数据库所面临的挑战
有网友调侃说,12306其实也是一个电商平台,而且是全球最复杂、规模最大的电商平台。但实际上,12306背后所隐藏的业务逻辑非常复杂,远远超过一般的电商平台。
对于电子商务网站的交易系统,例如淘宝网,当店家出售一件商品,库存减一,客户退货,库存加一,当库存为零,商品下架,有问题线下讨论。此类交易系统提供简单快速的计算。因为不同品牌商品的销售彼此之间没有关联性,不会因为某件品牌商品的出售关联到其他品牌商品的库存量,它们的商品库存是属于“静态库存”
再来看看12306:12306互联网售票系统是业务逻辑很复杂的系统,如果将每张可出售的火车票当成一件商品来看,每张票的销售都会关联到整条路线每个站点可销售的余票量,有些站点的余票量会产生变化, 有些站点余票量不会有变化。
由另外一个角度来看,当销售一张票, 改签,或退票时,整条路线每个站点的余票量都需要重新计算,也就是说每个站点的余票库存是个“动态变化库存”的概念。站点与站点之间的余票库存有巨大的关联性,此“动态库存”概念的业务逻辑是12306与电商网站最大的差异。12306的设计重点不但要具有大型电商网站所具备的特性外 (要提供快速响应时间,高可用性(容灾和备份)和系统的扩展性),还需要有强大的CPU计算资源来支撑。
鉴于12306没有图片、视频等影响带宽的内容,主要矛盾是数据库的高并发量,采用内存数据库是正确的解决思路。参考目前国内外成熟电商网站经验,例如国内的淘宝,百度,国外的谷歌等这类有着海量用户访问的网站,都不约而同的采用分布式的数据处理平台,而Gemfire正是一个基于内存的分布式数据库,并且拥有大量的成功案例,非常适合来解决12306的问题。我们能看到,这两年关于12306网火车余票量不准的抱怨确实减少了。
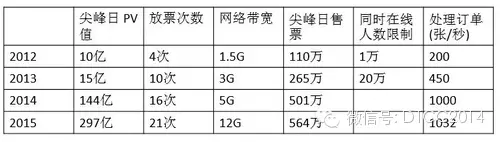
▲12306成长历程:12306网站3年时间访问量从10亿PV暴涨到100亿PV,售票量从100万增加到500万,出票处理能力200张/秒增加到1000张/秒。
杨旭钧表示,针对由海量用户访问带来的高并发挑战,Gemfire本身就是基于内存的技术架构,对于并发访问有天然的IO优势。同时Gemfire是一个分布式数据库,可以将数据访问的请求分散到集群中,有效降低了单个服务器的负荷。动态的分布式架构,可以在运行时增加服务节点,从而获得更高的并发性能。
高流量方面,主要涉及低延迟的余票查询。Gemfire支持类Map-Reduce并行处理,能够按车次将余票、共用定义等数据拆分成多个独立的计算单元,对余票查询中最耗时的共 用定义部分做预先处理,生成查询缓存。当余票数据发生变化时,系统会动态更新查询缓存。有了预处理及数据同步过程维护的动态查询缓存,单次查询可以控制在10ms-300ms之间, 同时10分钟的固有延迟也不存在了。
12306从2012年3月开始改造,把原先采用的Unix小型机架构,通过GemFire的分布式内存计算平台改造成Linux/X86服务器集群架构,从而提升了查询余票的速度。根据系统运行数据记录,技术改造之后,在只采用10几台X86服务器实现了以前数十台小型机的余票计算和查询能力,单次查询的最长时间从之前的15秒左右下降到0.2秒以下,缩短了75倍以上。2012年春运的极端高流量并发情况下,支持每秒上万次的并发查询,高峰期间达到2.6万QPS吞吐量,整个系统效率显著提高。
订单查询系统改造,在改造之前的系统运行模式下,每秒只能支持300-400个QPS的吞吐量,高流量的并发查询只能通过分库来实现。改造之后,可以实现高达上万个QPS的吞吐量,而且查询速度可以保障在20毫秒左右。新的技术架构可以按需弹性动态扩展,并发量增加时,还可以通过动态增加X86服务器来应对,保持毫秒级的响应时间。
在以往的春运期间,12306售票系统部署Gemfire集群在2个数据中心,提供服务。在2015年春运购票高峰之前,考虑到超大并发会造成网络流量大以及阻塞的问题,今年特别在阿里云建立一个数据中心,由阿里云提供“虚拟机”的租赁服务,将基于Gemfire实现余票查询功能的系统以及Web服务部署在这些虚拟机上,以分流“余票查询”请求,解决因为高峰期超高并发造成的网络阻塞问题,以进一步提高服务品质。为此,12306在2014年下半年在阿里云做了小规模的部署和调试。2015年春运购票高峰期的12306高效平稳运行,也验证了混合架构的可行性。
作为国内数据库与大数据领域最大规模的技术盛宴,来自BAT、360、京东、美团、58同城、Ebay、新浪、网易、搜狐、易车网、去哪儿网、携程网等互联网企业,微软、南大通用等数据库厂商、以及北京大学等学术机构等百余名顶尖专家现身演讲,为大家奉献了极为宝贵的干货演讲。
在2015中国数据库技术大会上,现场展台人员爆满,来自微软、百度、星环科技、宝存科技、云和恩墨、听云、永洪BI、Greeliant、Action Technology、巨杉数据库、联想、慧科、云智慧等厂商强力加盟,大会现场有互联网家庭机器人展台,现场参会的朋友有机会与机器人互动,同时大会现场还安排了填调查赢取奖品互动环节。更多惊喜,尽在2015中国数据库技术大会现场。
12306.cn无疑是全球最繁忙的网站,每到特殊节日,这个世界上规模最大的实时交易系统都要面临巨大考验。2012年初的春运高峰期间,每天有2000万人访问该网站,日点击量最高达到14亿,大量同时涌入的网络访问造成12306几近瘫痪。
为了改变“逢节必瘫”的现状,铁路总公司从2012年6月开始选择Pivotal GemFire分布式内存计算平台对12306进行改造。如今3年过去,2015年铁路客票的春运早已结束,不难发现,与往年相比今年大家对12306吐槽的花边新闻少了很多。
在第六届中国数据库技术大会(DTCC 2015)的“内存数据库专场”中,中国科学院自动化研究所大数据应用部高级研究员杨旭钧为我们详尽解读了GemFire是如何帮助12306摆脱“饱受诟病”的命运。

▲中国科学院自动化研究所大数据应用部高级研究员杨旭钧
回顾GemFire的前世今生
1982年
GemStone Systems成立于美国俄勒冈州西北部城市比弗顿市。GemStone是领先的分布式数据管理技术软件公司,在此方面有着厚重的历史。最初使用Smalltalk语言开发出了第一代面向对象的数据库。并成为Smalltalk执行委员会成员。
1986年
第一代产品Gemstone/S 正式面世,受到金融市场的广泛欢迎。
90年代中后期
随着Java语言的广泛应用,GemStone与Sun公司合作,参与到JEE的规范制定(JCache -JSR107),并陆续更新与JEE平台相结合的产品。GemStone开发出了GemFire,成为业界第一个满足J2EE标准的中间件。GemFire拥有全新的应用框架,兼容Java, C++, C#。而GemFire在CEP(complex event processing),Event Stream Processing,Data Virtualization, Distributed Caching几个方面有着举足轻重的地位。
2008年初
金融危机后,金融监管法规Dodd-Frank、Basel3等陆续出台,各大投资银行为了减少系统风险和增加透明度,加强了金融衍生品交易平台的投资规模,Gemfire击败Oracle等老牌厂商,跻身为华尔街第一大分布式数据处理平台软件。
2010年5月
VMware收购了老牌厂商Gemstone,并入SpringSource部门。
12306的“双高挑战”
据杨旭钧介绍,在2015年春运高峰日,12306的PV值是297亿,流量较平时增加1000倍。
12306作为一个面向公众的系统,互联网售票系统具备所有大型互联网系统的特性:“高并发”, “高流量”。尤其是在我国的各个节假日,系统的访问量会激增,导致整个系统后台压力过大,响应变慢。
▲传统关系型数据库所面临的挑战
有网友调侃说,12306其实也是一个电商平台,而且是全球最复杂、规模最大的电商平台。但实际上,12306背后所隐藏的业务逻辑非常复杂,远远超过一般的电商平台。
对于电子商务网站的交易系统,例如淘宝网,当店家出售一件商品,库存减一,客户退货,库存加一,当库存为零,商品下架,有问题线下讨论。此类交易系统提供简单快速的计算。因为不同品牌商品的销售彼此之间没有关联性,不会因为某件品牌商品的出售关联到其他品牌商品的库存量,它们的商品库存是属于“静态库存”
再来看看12306:12306互联网售票系统是业务逻辑很复杂的系统,如果将每张可出售的火车票当成一件商品来看,每张票的销售都会关联到整条路线每个站点可销售的余票量,有些站点的余票量会产生变化, 有些站点余票量不会有变化。
由另外一个角度来看,当销售一张票, 改签,或退票时,整条路线每个站点的余票量都需要重新计算,也就是说每个站点的余票库存是个“动态变化库存”的概念。站点与站点之间的余票库存有巨大的关联性,此“动态库存”概念的业务逻辑是12306与电商网站最大的差异。12306的设计重点不但要具有大型电商网站所具备的特性外 (要提供快速响应时间,高可用性(容灾和备份)和系统的扩展性),还需要有强大的CPU计算资源来支撑。
鉴于12306没有图片、视频等影响带宽的内容,主要矛盾是数据库的高并发量,采用内存数据库是正确的解决思路。参考目前国内外成熟电商网站经验,例如国内的淘宝,百度,国外的谷歌等这类有着海量用户访问的网站,都不约而同的采用分布式的数据处理平台,而Gemfire正是一个基于内存的分布式数据库,并且拥有大量的成功案例,非常适合来解决12306的问题。我们能看到,这两年关于12306网火车余票量不准的抱怨确实减少了。
▲12306成长历程:12306网站3年时间访问量从10亿PV暴涨到100亿PV,售票量从100万增加到500万,出票处理能力200张/秒增加到1000张/秒。
杨旭钧表示,针对由海量用户访问带来的高并发挑战,Gemfire本身就是基于内存的技术架构,对于并发访问有天然的IO优势。同时Gemfire是一个分布式数据库,可以将数据访问的请求分散到集群中,有效降低了单个服务器的负荷。动态的分布式架构,可以在运行时增加服务节点,从而获得更高的并发性能。
高流量方面,主要涉及低延迟的余票查询。Gemfire支持类Map-Reduce并行处理,能够按车次将余票、共用定义等数据拆分成多个独立的计算单元,对余票查询中最耗时的共 用定义部分做预先处理,生成查询缓存。当余票数据发生变化时,系统会动态更新查询缓存。有了预处理及数据同步过程维护的动态查询缓存,单次查询可以控制在10ms-300ms之间, 同时10分钟的固有延迟也不存在了。
12306从2012年3月开始改造,把原先采用的Unix小型机架构,通过GemFire的分布式内存计算平台改造成Linux/X86服务器集群架构,从而提升了查询余票的速度。根据系统运行数据记录,技术改造之后,在只采用10几台X86服务器实现了以前数十台小型机的余票计算和查询能力,单次查询的最长时间从之前的15秒左右下降到0.2秒以下,缩短了75倍以上。2012年春运的极端高流量并发情况下,支持每秒上万次的并发查询,高峰期间达到2.6万QPS吞吐量,整个系统效率显著提高。
订单查询系统改造,在改造之前的系统运行模式下,每秒只能支持300-400个QPS的吞吐量,高流量的并发查询只能通过分库来实现。改造之后,可以实现高达上万个QPS的吞吐量,而且查询速度可以保障在20毫秒左右。新的技术架构可以按需弹性动态扩展,并发量增加时,还可以通过动态增加X86服务器来应对,保持毫秒级的响应时间。
在以往的春运期间,12306售票系统部署Gemfire集群在2个数据中心,提供服务。在2015年春运购票高峰之前,考虑到超大并发会造成网络流量大以及阻塞的问题,今年特别在阿里云建立一个数据中心,由阿里云提供“虚拟机”的租赁服务,将基于Gemfire实现余票查询功能的系统以及Web服务部署在这些虚拟机上,以分流“余票查询”请求,解决因为高峰期超高并发造成的网络阻塞问题,以进一步提高服务品质。为此,12306在2014年下半年在阿里云做了小规模的部署和调试。2015年春运购票高峰期的12306高效平稳运行,也验证了混合架构的可行性。
作为国内数据库与大数据领域最大规模的技术盛宴,来自BAT、360、京东、美团、58同城、Ebay、新浪、网易、搜狐、易车网、去哪儿网、携程网等互联网企业,微软、南大通用等数据库厂商、以及北京大学等学术机构等百余名顶尖专家现身演讲,为大家奉献了极为宝贵的干货演讲。
在2015中国数据库技术大会上,现场展台人员爆满,来自微软、百度、星环科技、宝存科技、云和恩墨、听云、永洪BI、Greeliant、Action Technology、巨杉数据库、联想、慧科、云智慧等厂商强力加盟,大会现场有互联网家庭机器人展台,现场参会的朋友有机会与机器人互动,同时大会现场还安排了填调查赢取奖品互动环节。更多惊喜,尽在2015中国数据库技术大会现场。
12306.cn无疑是全球最繁忙的网站,每到特殊节日,这个世界上规模最大的实时交易系统都要面临巨大考验。2012年初的春运高峰期间,每天有2000万人访问该网站,日点击量最高达到14亿,大量同时涌入的网络访问造成12306几近瘫痪。
为了改变“逢节必瘫”的现状,铁路总公司从2012年6月开始选择Pivotal GemFire分布式内存计算平台对12306进行改造。如今3年过去,2015年铁路客票的春运早已结束,不难发现,与往年相比今年大家对12306吐槽的花边新闻少了很多。
在第六届中国数据库技术大会(DTCC 2015)的“内存数据库专场”中,中国科学院自动化研究所大数据应用部高级研究员杨旭钧为我们详尽解读了GemFire是如何帮助12306摆脱“饱受诟病”的命运。
▲中国科学院自动化研究所大数据应用部高级研究员杨旭钧
回顾GemFire的前世今生
1982年
GemStone Systems成立于美国俄勒冈州西北部城市比弗顿市。GemStone是领先的分布式数据管理技术软件公司,在此方面有着厚重的历史。最初使用Smalltalk语言开发出了第一代面向对象的数据库。并成为Smalltalk执行委员会成员。
1986年
第一代产品Gemstone/S 正式面世,受到金融市场的广泛欢迎。
90年代中后期
随着Java语言的广泛应用,GemStone与Sun公司合作,参与到JEE的规范制定(JCache -JSR107),并陆续更新与JEE平台相结合的产品。GemStone开发出了GemFire,成为业界第一个满足J2EE标准的中间件。GemFire拥有全新的应用框架,兼容Java, C++, C#。而GemFire在CEP(complex event processing),Event Stream Processing,Data Virtualization, Distributed Caching几个方面有着举足轻重的地位。
2008年初
金融危机后,金融监管法规Dodd-Frank、Basel3等陆续出台,各大投资银行为了减少系统风险和增加透明度,加强了金融衍生品交易平台的投资规模,Gemfire击败Oracle等老牌厂商,跻身为华尔街第一大分布式数据处理平台软件。
2010年5月
VMware收购了老牌厂商Gemstone,并入SpringSource部门。
12306的“双高挑战”
据杨旭钧介绍,在2015年春运高峰日,12306的PV值是297亿,流量较平时增加1000倍。
12306作为一个面向公众的系统,互联网售票系统具备所有大型互联网系统的特性:“高并发”, “高流量”。尤其是在我国的各个节假日,系统的访问量会激增,导致整个系统后台压力过大,响应变慢。
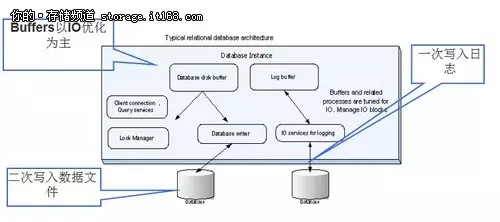
▲传统关系型数据库所面临的挑战
有网友调侃说,12306其实也是一个电商平台,而且是全球最复杂、规模最大的电商平台。但实际上,12306背后所隐藏的业务逻辑非常复杂,远远超过一般的电商平台。
对于电子商务网站的交易系统,例如淘宝网,当店家出售一件商品,库存减一,客户退货,库存加一,当库存为零,商品下架,有问题线下讨论。此类交易系统提供简单快速的计算。因为不同品牌商品的销售彼此之间没有关联性,不会因为某件品牌商品的出售关联到其他品牌商品的库存量,它们的商品库存是属于“静态库存”
再来看看12306:12306互联网售票系统是业务逻辑很复杂的系统,如果将每张可出售的火车票当成一件商品来看,每张票的销售都会关联到整条路线每个站点可销售的余票量,有些站点的余票量会产生变化, 有些站点余票量不会有变化。
由另外一个角度来看,当销售一张票, 改签,或退票时,整条路线每个站点的余票量都需要重新计算,也就是说每个站点的余票库存是个“动态变化库存”的概念。站点与站点之间的余票库存有巨大的关联性,此“动态库存”概念的业务逻辑是12306与电商网站最大的差异。12306的设计重点不但要具有大型电商网站所具备的特性外 (要提供快速响应时间,高可用性(容灾和备份)和系统的扩展性),还需要有强大的CPU计算资源来支撑。
鉴于12306没有图片、视频等影响带宽的内容,主要矛盾是数据库的高并发量,采用内存数据库是正确的解决思路。参考目前国内外成熟电商网站经验,例如国内的淘宝,百度,国外的谷歌等这类有着海量用户访问的网站,都不约而同的采用分布式的数据处理平台,而Gemfire正是一个基于内存的分布式数据库,并且拥有大量的成功案例,非常适合来解决12306的问题。我们能看到,这两年关于12306网火车余票量不准的抱怨确实减少了。
▲12306成长历程:12306网站3年时间访问量从10亿PV暴涨到100亿PV,售票量从100万增加到500万,出票处理能力200张/秒增加到1000张/秒。
杨旭钧表示,针对由海量用户访问带来的高并发挑战,Gemfire本身就是基于内存的技术架构,对于并发访问有天然的IO优势。同时Gemfire是一个分布式数据库,可以将数据访问的请求分散到集群中,有效降低了单个服务器的负荷。动态的分布式架构,可以在运行时增加服务节点,从而获得更高的并发性能。
高流量方面,主要涉及低延迟的余票查询。Gemfire支持类Map-Reduce并行处理,能够按车次将余票、共用定义等数据拆分成多个独立的计算单元,对余票查询中最耗时的共 用定义部分做预先处理,生成查询缓存。当余票数据发生变化时,系统会动态更新查询缓存。有了预处理及数据同步过程维护的动态查询缓存,单次查询可以控制在10ms-300ms之间, 同时10分钟的固有延迟也不存在了。
12306从2012年3月开始改造,把原先采用的Unix小型机架构,通过GemFire的分布式内存计算平台改造成Linux/X86服务器集群架构,从而提升了查询余票的速度。根据系统运行数据记录,技术改造之后,在只采用10几台X86服务器实现了以前数十台小型机的余票计算和查询能力,单次查询的最长时间从之前的15秒左右下降到0.2秒以下,缩短了75倍以上。2012年春运的极端高流量并发情况下,支持每秒上万次的并发查询,高峰期间达到2.6万QPS吞吐量,整个系统效率显著提高。
订单查询系统改造,在改造之前的系统运行模式下,每秒只能支持300-400个QPS的吞吐量,高流量的并发查询只能通过分库来实现。改造之后,可以实现高达上万个QPS的吞吐量,而且查询速度可以保障在20毫秒左右。新的技术架构可以按需弹性动态扩展,并发量增加时,还可以通过动态增加X86服务器来应对,保持毫秒级的响应时间。
在以往的春运期间,12306售票系统部署Gemfire集群在2个数据中心,提供服务。在2015年春运购票高峰之前,考虑到超大并发会造成网络流量大以及阻塞的问题,今年特别在阿里云建立一个数据中心,由阿里云提供“虚拟机”的租赁服务,将基于Gemfire实现余票查询功能的系统以及Web服务部署在这些虚拟机上,以分流“余票查询”请求,解决因为高峰期超高并发造成的网络阻塞问题,以进一步提高服务品质。为此,12306在2014年下半年在阿里云做了小规模的部署和调试。2015年春运购票高峰期的12306高效平稳运行,也验证了混合架构的可行性。
作为国内数据库与大数据领域最大规模的技术盛宴,来自BAT、360、京东、美团、58同城、Ebay、新浪、网易、搜狐、易车网、去哪儿网、携程网等互联网企业,微软、南大通用等数据库厂商、以及北京大学等学术机构等百余名顶尖专家现身演讲,为大家奉献了极为宝贵的干货演讲。
在2015中国数据库技术大会上,现场展台人员爆满,来自微软、百度、星环科技、宝存科技、云和恩墨、听云、永洪BI、Greeliant、Action Technology、巨杉数据库、联想、慧科、云智慧等厂商强力加盟,大会现场有互联网家庭机器人展台,现场参会的朋友有机会与机器人互动,同时大会现场还安排了填调查赢取奖品互动环节。更多惊喜,尽在2015中国数据库技术大会现场。


 IP卡
IP卡 狗仔卡
狗仔卡 发表于 2015-6-8 15:17:31
发表于 2015-6-8 15:17:31
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡 楼主
楼主













