AMD的NUMA架构处理器
AMD虽然是处理器行业的后起之秀,其NUMA架构和INTEL的SMP架构完全不同,消除了总线瓶颈,其设计思路和高端多路服务器相似。我注意到SUN的产品线里除了自己的高端UNIX服务器外,PC服务器只有AMD的,是不是因为SUN对AMD的后续发展更有信心?
另外的一个趋势是INTEL在其后续产品中逐渐放弃了单总线架构,逐步采用双总线,对于MP来说就是两条总线,对于DP来说就是每个CPU占用一条总线。
虽然INTEL坚持自己的设计思路要好于AMD,但看来似乎不得不承认,INTEL的SMP最终还是要发展到AMD的NUMA架构上去。
SMP、NUMA、MPP体系结构介绍【转】
从系统架构来看,目前的商用服务器大体可以分为三类,即对称多处理器结构 (SMP : Symmetric Multi-Processor) ,非一致存储访问结构 (NUMA : Non-Uniform Memory Access) ,以及海量并行处理结构 (MPP : Massive Parallel Processing) 。它们的特征分别描述如下:
SMP(Symmetric Multi-Processor)
所谓对称多处理器结构,是指服务器中多个 CPU 对称工作,无主次或从属关系。各 CPU 共享相同的物理内存,每个 CPU 访问内存中的任何地址所需时间是相同的,因此 SMP 也被称为一致存储器访问结构 (UMA : Uniform Memory Access) 。对 SMP 服务器进行扩展的方式包括增加内存、使用更快的 CPU 、增加 CPU 、扩充 I/O( 槽口数与总线数 ) 以及添加更多的外部设备 ( 通常是磁盘存储 ) 。
SMP 服务器的主要特征是共享,系统中所有资源 (CPU 、内存、 I/O 等 ) 都是共享的。也正是由于这种特征,导致了 SMP 服务器的主要问题,那就是它的扩展能力非常有限。对于 SMP 服务器而言,每一个共享的环节都可能造成 SMP 服务器扩展时的瓶颈,而最受限制的则是内存。由于每个 CPU 必须通过相同的内存总线访问相同的内存资源,因此随着 CPU 数量的增加,内存访问冲突将迅速增加,最终会造成 CPU 资源的浪费,使 CPU 性能的有效性大大降低。实验证明, SMP 服务器 CPU 利用率最好的情况是 2 至 4 个 CPU 。
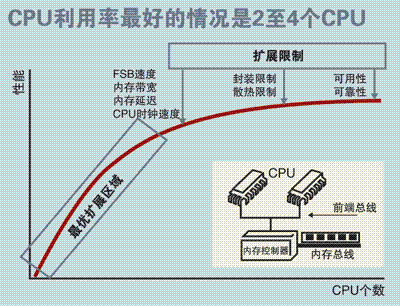
图 1.SMP 服务器 CPU 利用率状态
NUMA(Non-Uniform Memory Access)
由于 SMP 在扩展能力上的限制,人们开始探究如何进行有效地扩展从而构建大型系统的技术, NUMA 就是这种努力下的结果之一。利用 NUMA 技术,可以把几十个 CPU( 甚至上百个 CPU) 组合在一个服务器内。其 CPU 模块结构如图 2 所示:

图 2.NUMA 服务器 CPU 模块结构 NUMA 服务器的基本特征是具有多个 CPU 模块,每个 CPU 模块由多个 CPU( 如 4 个 ) 组成,并且具有独立的本地内存、 I/O 槽口等。由于其节点之间可以通过互联模块 ( 如称为 Crossbar Switch) 进行连接和信息交互,因此每个 CPU 可以访问整个系统的内存 ( 这是 NUMA 系统与 MPP 系统的重要差别 ) 。显然,访问本地内存的速度将远远高于访问远地内存 ( 系统内其它节点的内存 ) 的速度,这也是非一致存储访问 NUMA 的由来。由于这个特点,为了更好地发挥系统性能,开发应用程序时需要尽量减少不同 CPU 模块之间的信息交互。
利用 NUMA 技术,可以较好地解决原来 SMP 系统的扩展问题,在一个物理服务器内可以支持上百个 CPU 。比较典型的 NUMA 服务器的例子包括 HP 的 Superdome 、 SUN15K 、 IBMp690 等。
但 NUMA 技术同样有一定缺陷,由于访问远地内存的延时远远超过本地内存,因此当 CPU 数量增加时,系统性能无法线性增加。如 HP 公司发布 Superdome 服务器时,曾公布了它与 HP 其它 UNIX 服务器的相对性能值,结果发现, 64 路 CPU 的 Superdome (NUMA 结构 ) 的相对性能值是 20 ,而 8 路 N4000( 共享的 SMP 结构 ) 的相对性能值是 6.3 。从这个结果可以看到, 8 倍数量的 CPU 换来的只是 3 倍性能的提升。
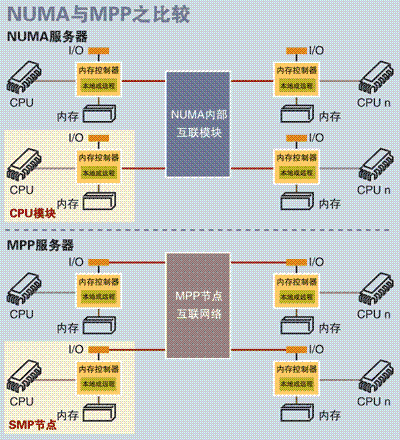
图 3.MPP 服务器架构图
MPP(Massive Parallel Processing)
和 NUMA 不同, MPP 提供了另外一种进行系统扩展的方式,它由多个 SMP 服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。其基本特征是由多个 SMP 服务器 ( 每个 SMP 服务器称节点 ) 通过节点互联网络连接而成,每个节点只访问自己的本地资源 ( 内存、存储等 ) ,是一种完全无共享 (Share Nothing) 结构,因而扩展能力最好,理论上其扩展无限制,目前的技术可实现 512 个节点互联,数千个 CPU 。目前业界对节点互联网络暂无标准,如 NCR 的 Bynet , IBM 的 SPSwitch ,它们都采用了不同的内部实现机制。但节点互联网仅供 MPP 服务器内部使用,对用户而言是透明的。
在 MPP 系统中,每个 SMP 节点也可以运行自己的操作系统、数据库等。但和 NUMA 不同的是,它不存在异地内存访问的问题。换言之,每个节点内的 CPU 不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配 (Data Redistribution) 。
但是 MPP 服务器需要一种复杂的机制来调度和平衡各个节点的负载和并行处理过程。目前一些基于 MPP 技术的服务器往往通过系统级软件 ( 如数据库 ) 来屏蔽这种复杂性。举例来说, NCR 的 Teradata 就是基于 MPP 技术的一个关系数据库软件,基于此数据库来开发应用时,不管后台服务器由多少个节点组成,开发人员所面对的都是同一个数据库系统,而不需要考虑如何调度其中某几个节点的负载。
NUMA 与 MPP 的区别
从架构来看, NUMA 与 MPP 具有许多相似之处:它们都由多个节点组成,每个节点都具有自己的 CPU 、内存、 I/O ,节点之间都可以通过节点互联机制进行信息交互。那么它们的区别在哪里?通过分析下面 NUMA 和 MPP 服务器的内部架构和工作原理不难发现其差异所在。
首先是节点互联机制不同, NUMA 的节点互联机制是在同一个物理服务器内部实现的,当某个 CPU 需要进行远地内存访问时,它必须等待,这也是 NUMA 服务器无法实现 CPU 增加时性能线性扩展的主要原因。而 MPP 的节点互联机制是在不同的 SMP 服务器外部通过 I/O 实现的,每个节点只访问本地内存和存储,节点之间的信息交互与节点本身的处理是并行进行的。因此 MPP 在增加节点时性能基本上可以实现线性扩展。
其次是内存访问机制不同。在 NUMA 服务器内部,任何一个 CPU 可以访问整个系统的内存,但远地访问的性能远远低于本地内存访问,因此在开发应用程序时应该尽量避免远地内存访问。在 MPP 服务器中,每个节点只访问本地内存,不存在远地内存访问的问题。
数据仓库的选择
哪种服务器更加适应数据仓库环境?这需要从数据仓库环境本身的负载特征入手。众所周知,典型的数据仓库环境具有大量复杂的数据处理和综合分析,要求系统具有很高的 I/O 处理能力,并且存储系统需要提供足够的 I/O 带宽与之匹配。而一个典型的 OLTP 系统则以联机事务处理为主,每个交易所涉及的数据不多,要求系统具有很高的事务处理能力,能够在单位时间里处理尽量多的交易。显然这两种应用环境的负载特征完全不同。
从 NUMA 架构来看,它可以在一个物理服务器内集成许多 CPU ,使系统具有较高的事务处理能力,由于远地内存访问时延远长于本地内存访问,因此需要尽量减少不同 CPU 模块之间的数据交互。显然, NUMA 架构更适用于 OLTP 事务处理环境,当用于数据仓库环境时,由于大量复杂的数据处理必然导致大量的数据交互,将使 CPU 的利用率大大降低。
相对而言, MPP 服务器架构的并行处理能力更优越,更适合于复杂的数据综合分析与处理环境。当然,它需要借助于支持 MPP 技术的关系数据库系统来屏蔽节点之间负载平衡与调度的复杂性。另外,这种并行处理能力也与节点互联网络有很大的关系。显然,适应于数据仓库环境的 MPP 服务器,其节点互联网络的 I/O 性能应该非常突出,才能充分发挥整个系统的性能。 |

 IP卡
IP卡 狗仔卡
狗仔卡 发表于 2011-2-5 16:25:42
发表于 2011-2-5 16:25:42
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡



