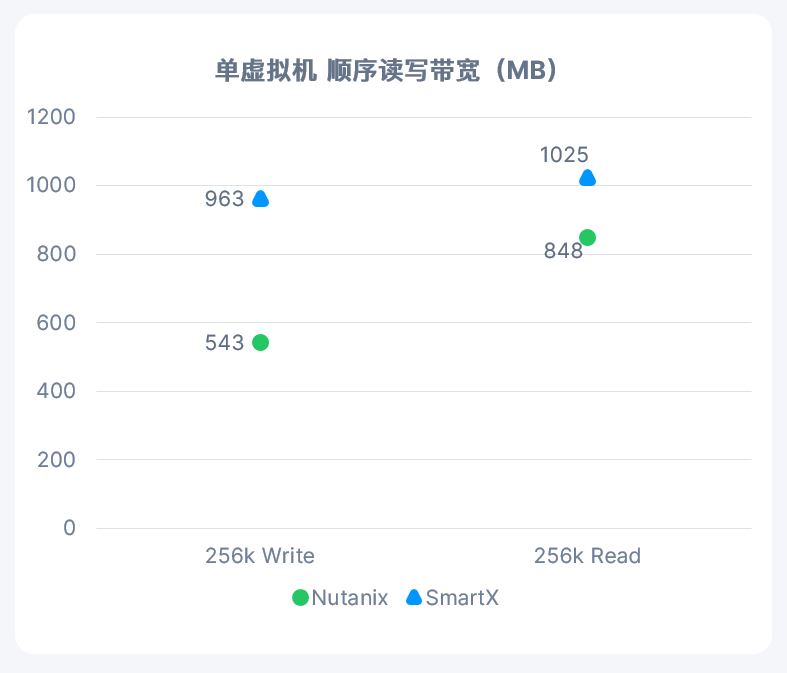
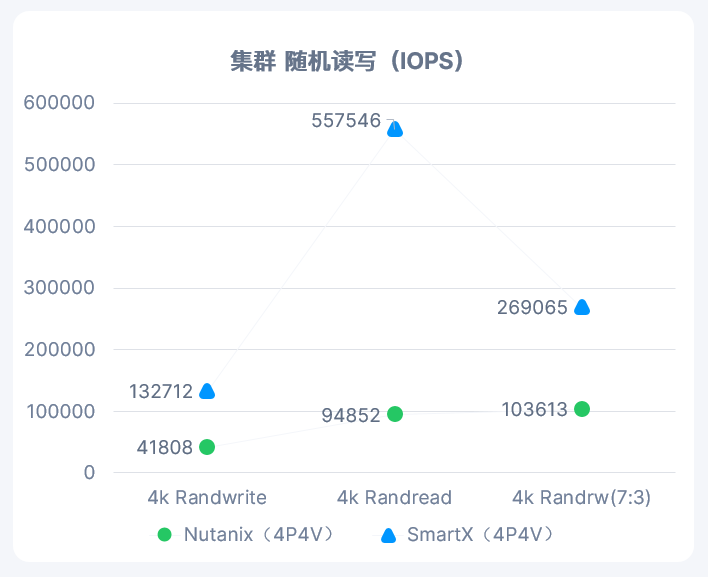
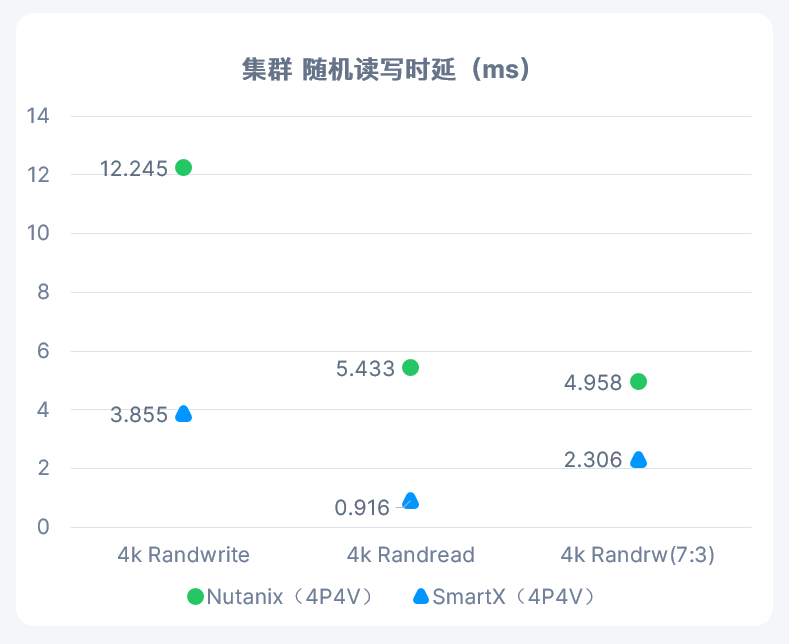
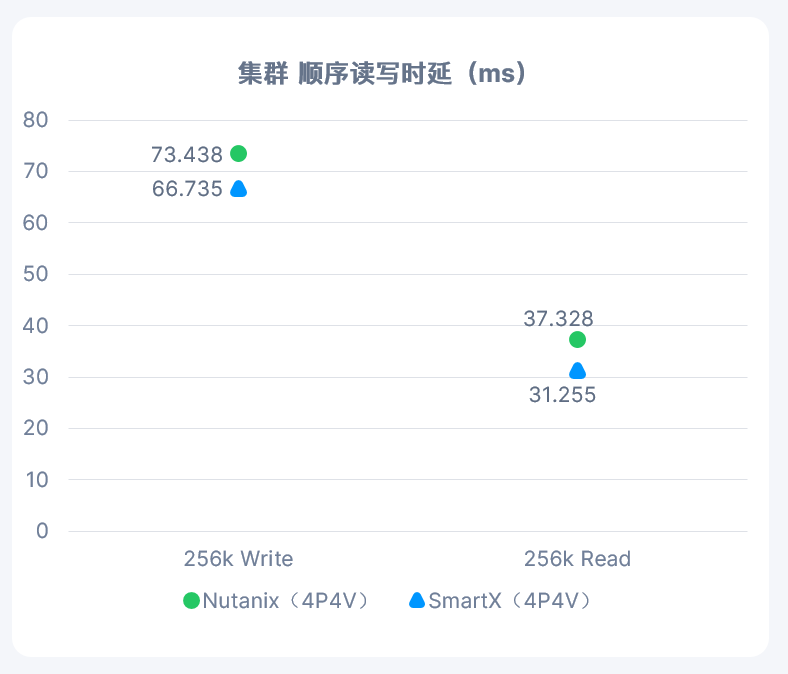
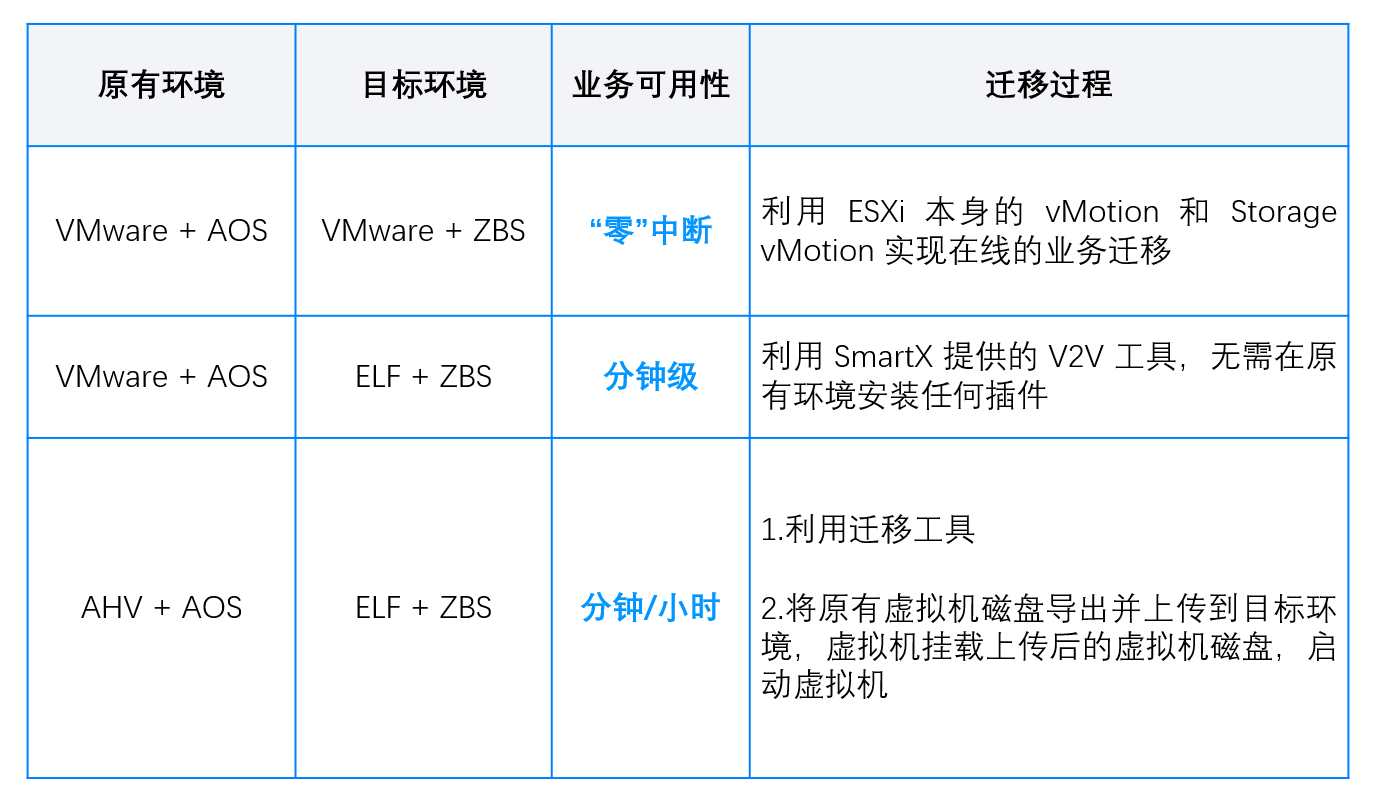
活动背景:本期的超融合技术探讨,主要帮助大家了解国内超融合市场的现状和一些超融合基础架构产品之间的区别。
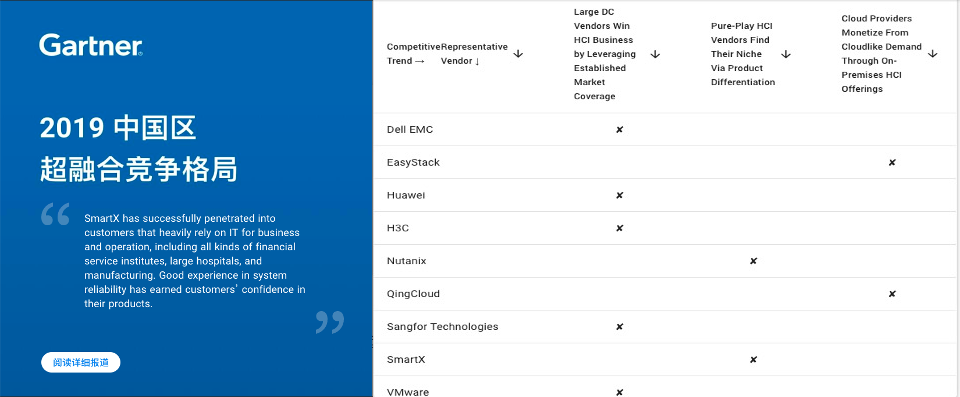
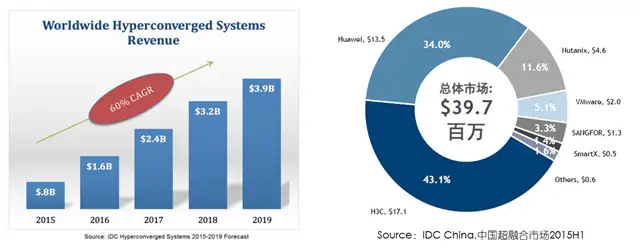
超融合目前还是一个新兴的市场,现在卖HCI(超融合)产品的厂商都是过去卖X86服务器的或是卖分布式存储软件的,因为HCI架构主要是以软件定义为基础,再结合X86硬件产品进行销售。国内主流的HCI产品厂商,除了传统的联想、华为、H3C等硬件厂商,甚至还有深信服这类安全厂商也在做HCI产品。其他新兴的厂商有达沃时代、大道云行、StorWind、青云HCI、SmartX等,这些厂商的市场份额虽然不大,但是每个产品却有自己不同于其他厂商的特点,可以适应多种不同的应用场景和环境。
问题总结:本期活动对国内主要几家超融合产品的特点、优势和区别进行了对比分析,主要包括以下几个方面的讨论问题:
1、国内外超融合产品市场和具体应用情况
2、国内外超融合产品的主要区别
3、国内外超融合产品的一些技术问题
讨论问题总结一、国内外超融合产品市场和具体应用情况1.国内外超融合产品主要有哪些?解答:HCI最初的领导者是Nutanix和VMware这些软件厂商,最早2011年就推出过超融合产品。在他之后有SimpliVity、Scale Computing、Pivot3等厂商之后,后来VMware也加入了这个领域。但是这些后来的厂商直到2013~2014年才推出首款产品。至于国内市场就要更晚一些,基本都是2014年后才逐渐推出自有产品。
目前主流产品主要有:
国外的有:Nutanix、VMwareEVO:RAIL、SimpliVity、Scale Computing等。
国内的有:SMARTX、深信服、达沃时代、大道云行、华为FusionStorage、青I等。
主要产品特点和现状,详细可以参考我分享的文档。
Nutanix和国内联想合作:2U产品,采用X3650服务器,封装Nutanix软件
Simplivity:采用Cisco或Dell的定制服务器,支持VMware;
VMware 的EVO:RAIL:提供纯软件部署,硬件由认证的合作伙伴提供,只支持VMware vSphere;EMC推出了vxrail,卖的比较火,最大支持64节点。
华为FusionCube:采用自家定制的x86刀片服务器,一体化产品。但是部分产品存储节点和计算节点是分开的,只能算是一体机。
青云QingCloud一体机:预集成了虚拟化平台、云平台管理软件、SDN网络和分布式存储。但是最近青云好像热衷于提供基于超融合架构的私有云服务,卖服务比较多,产品比较少。
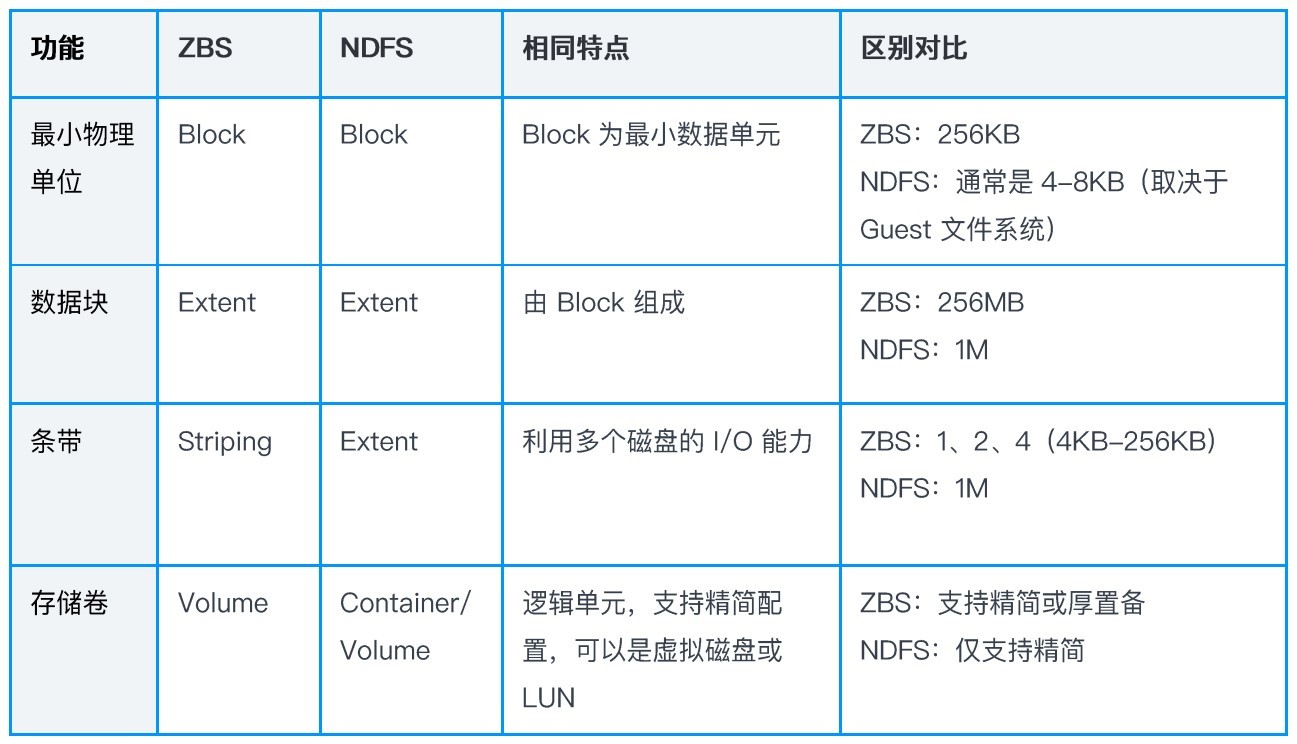
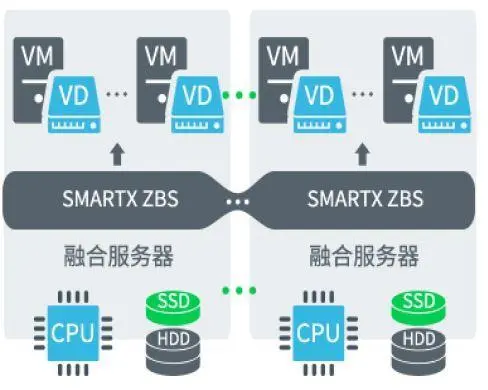
SMARTX:主要是软件,配置管理一套系统,支持水平扩展,支持商用x86服务器。现在也有硬件产品,Halo一体机,整合了SMARTX的ZBS分布式存储管理软件,适合不同用户选择。
Zetta(中科云):中科融合存储系统是一款自主研发、针对海量数据及高并发I/O应用而设计,集硬件平台、先进的分布式存储系统和智能管理功能于一体的存储产品。
深信服:而相比于国外厂商,深信服的超融合方案会更加全面。除了存储和计算资源,还特别是包含了网络资源,并且提供完整的2-7层网络服务。
超融合厂家阵营:

QQ图片20170502093734.png
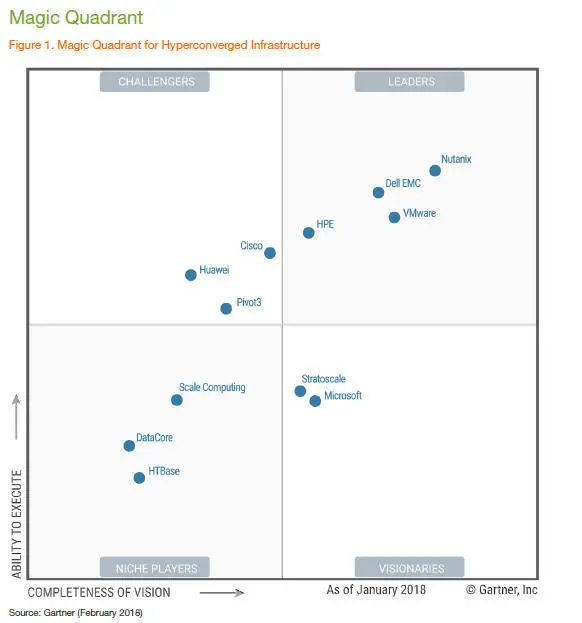
领导者领域:Nutanix排第一,毫不意外,SimpliVity与Nutanix极为接近排第二,然后Pivot3第三,这就让人意外了。
卓越表现者领域厂商有Atlantis, HyperGrid,EMC,VMware, Stratoscale,华为,HPE和思科,ScaleComputing是唯一的竞争者,而其它领域没有厂商。
Pivot3为什么得分这么高?部分归因于它的“高龄”——比Nutanix或SimpliVity建立要早,另外还有市场表现力好——该公司自称拥有超过1600位客户,还是最大的两个超融合数据存储集群之一的核心。
引用Forrester的结论就是“Pivot3是一个强大的参与厂商,尤其是当要求包含PB级数据存储时,它的空间有效数据保护还可以降低成本。”
观点:
1.Atlantis对比而言算是后起之秀,拥有较小的市场领域但因为其综合能力而处于强势地位。
2.Gridstore在微软专用化方面独一无二,目前仅支持Hyper-V和集成微软的环境,Gridstore解决方案的一个特别之处在于它的服务质量能力,允许多个类型虚拟机的定义,并确保最大和最小值输入/输出(I/O)的性能水平。
3.EMC对加入全行业转向软件定义基础设施环境处在有利位置。(报告中并不包括VxRack,只有VxRail。)
4.在厂商群中,Stratoscale是拥有更高级的工作负载与数据迁移功能的厂商之一并集成高可用性。
5.VMware宣称VSAN拥有4000以上用户,这将使它成为该市场部署最广泛超融合解决方案的厂商。
6.思科的HyperFlex处于早期阶段,影响了思科的本次评级,Forrester对思科的基础UCS平台给予了极大的认可,HyperFlex的“仕途”应该会扶摇直上。
7.HPE的产品也处于它的早期阶段,它在HCI细分市场的地位随着时间的推移将迅速改善。
8.华为提供FusionCube,支持不同的虚拟机管理程序,其产品看来技术成熟,但数据服务是弱项,界面使用相比其他厂商更为方便。
ScaleComputing的总结是:“一家小型公司但有一个很大的用户基础。”
超融合是存储市场热点之一,具有很大的发展潜力。随着厂商试图吸引和掌握市场份额,竞争渐趋白热化。
超融合的市场还在成长阶段,未来的盘子足够大,各个玩家之间的关系其实是竞合关系,尤其是超融合厂商,由于在计算平台领域是中立立场,既支持VMware,也支持OpenStack以及KVM、Hyper-V等其它架构,因此在未来与另外两大阵营之间有更多合作的可能性。
2.国内外厂商关于超融合产品的目标细分市场定位以及技术发展趋势?解答:不管是国内厂商还国外厂商,超融合产品的目标市场都是替换现有数据中心的虚拟化环境,简化IT架构。
那些目前运行在物理硬件上的应用最好还是继续保持运行在物理硬件架构上。所以,除了那些目前仍然需要直接运行在物理硬件环境中的应用程序,外,都是超融合架构的目标市场。
在技术的发展上,国外产品都以自有产品为主,包括Nutanix和VMWARE的VSAN。如果部署了以后,只能按照厂商的这条技术路线去扩展。而国内由于技术能够有限,基本都是以开源技术深度优化和整合为主。优势是比较开放,可以支持多种虚拟化平台,用户选择可以多一些。
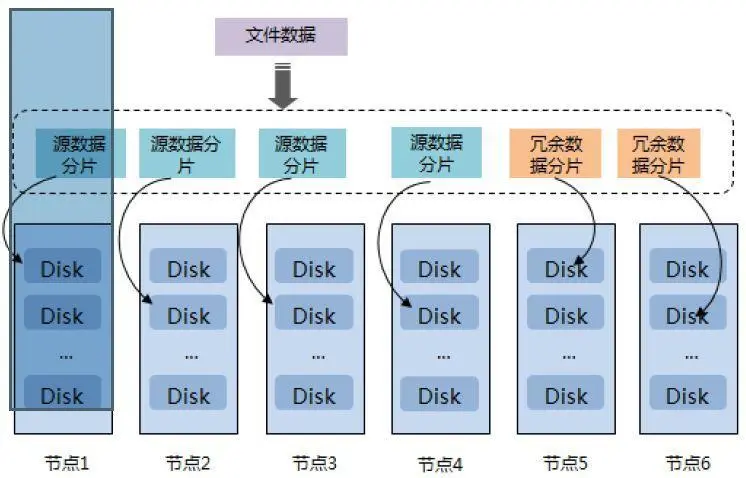
3.超融合基础架构产品对于数据共享的具体应用方案?超融合基础架构产品基本采用软件定义存储SDS来解决了虚拟化存储问题,提供一个大容量的数据存储池,这里需要说明的是SDS是指ServerSAN,由超融合基础架构产品提供分布式块存储。而当前的客户在生产环境还是对虚拟机及物理机都有着数据共享的需求,比如应用程序的HA等,这就需要分布式文件系统或者NAS存储系统。目前超融合架构产品普遍缺乏,在实际环境还是需要独立部署外部的NAS存储系统,当前哪一家超融合架构产品可以提供相应解决方案?
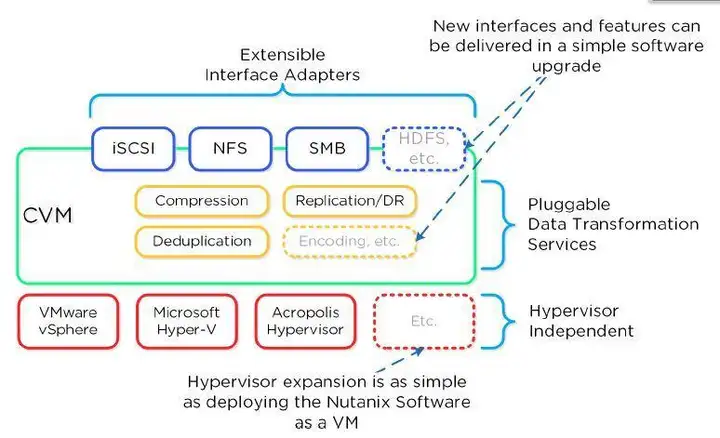
解答:很多超融合厂家针对底层数据存储采用ceph。Ceph是一个分布式存储系统,支持对象,文件,块接口。
分布式存储的应用场景相对于其存储接口,现在流行分为三种:
1.对象存储: 也就是通常意义的键值存储,其接口就是简单的GET,PUT,DEL和其他扩展,如七牛、又拍,Swift,S3等。
2.块存储: 这种接口通常以QEMUDriver或者KernelModule的方式存在,这种接口需要实现Linux的Block Device的接口或者QEMU提供的Block Driver接口,如Sheepdog,AWS的EBS,青云的云硬盘和阿里云的盘古系统,还有Ceph的RBD(RBD是Ceph面向块存储的接口)。
3、文件存储: 通常意义是支持POSIX接口,它跟传统的文件系统如Ext4是一个类型的,但区别在于分布式存储提供了并行化的能力,如Ceph的CephFS(CephFS是Ceph面向文件存储的接口),但是有时候又会把GFS,HDFS这种非POSIX接口的类文件存储接口归入此类。
众所周知,很多传统厂商如日立、富士通等存储大厂也采用了Ceph作为它们存储硬件的载体,Ceph能提供企业级的存储服务一定有它的优势,才能让传统的存储厂商弃而采用开源的存储方案。
弹性的数据分布策略和物理拓扑输入实现了高可用性和高持久性,Ceph的高性能重构还体现在利用CRush算法对数进行约束,避免数据分布到所有的集群的一个节点上,利用Ceph设计并提供的一个由CRush算法来支持一个高自由化的存储集群的设计,实现高可靠性,高持久性,高性能。
对于数据共享当前很多超融合架构产品都可以提供相应解决方案的!
4.超融合的应用范围?是不是超融合大多适用于大数据分析上,主要是在线分析型应用和数据库?
解答:首先,超融合系统适用于IT环境的所有应用类型。
其次,超融合系统的首要目的是管理虚拟化环境,那些目前运行在物理硬件上的应用最好还是继续保持运行在物理硬件架构上。所以,除了那些目前仍然需要直接运行在物理硬件环境中的应用程序,我不认为存在一种特殊的应用程序不能被部署在超融合的基础架构中。
最后,只需超融合群集规模足够,能提供的足够的性能,超融合架构是可以跑在线分析型应用和数据库的。
5.超融合是否可以支持一切系统?现有情况描述:
公司现有业务系统多套,OA、CRM、MAIL、等等20多套,现每个业务系统都跑在不同的X86服务器、POWER小机上,后期管理十分繁琐,需要不同的专业人员。
数据日益增多,现有数据3T,每年会有500G的增长量,现还需考虑媒体文件存档,大概一年需要800G文件存档。
问题:
1、OA、CRM、ERP等大型信息系统,是否能跑在超融合上,如何设计架构?
2、Oracle是否能够跑在超融合上?
3、超融合概念是“软件定义一切”,但经过了解目前只是软件定义存储,CPU、内存是否也能够融合,CPU使用高时,如何解决这个瓶颈?
4、数据量较大,增长量快速,是否适合超融合架构?与传统存储有什么优势?
解答:超融合以现阶段的产品能力而言主要用于支持应用运行,小型数据库,而不适合大型的数据库。所以你问题里的OA、CRM、ERP理论上都可以,但数据库组件建议放置在外。
具体解决:
1、大型信息系统理论上可以跑超融合,只要超融合的规模足够大,整个超融合架构群集的性能要大于大型信息系统的需求,就可以上,架构上都是分布式部署,根据性能需求配置节点数量。
2、Oracle目前有单独的超融合架构系统,类似于ORACLE推出的一体机,可以保证性能和稳定性,但是一般的超融合架构不建议上。
3、软件定义一起,在CPU和内存上还是遵循虚拟化层的定义,这个主要看你选用什么样的hypervisor,例如VMware就可以动态调节CPU负载,这个已经是成熟的技术,超融合只是将不同的hypervisor整合到一个统一的设备中。
4、数据量较大,增长量快速,非常适合选用超融合架构,因为超融合架构在扩展上非常灵活,需要扩充时,只需要按需增加节点,而不会影响原有的节点,而且还会提升整个超融合架构的性能。与传统存储相比具有按需扩展,使用灵活,系统使用率高等特点。
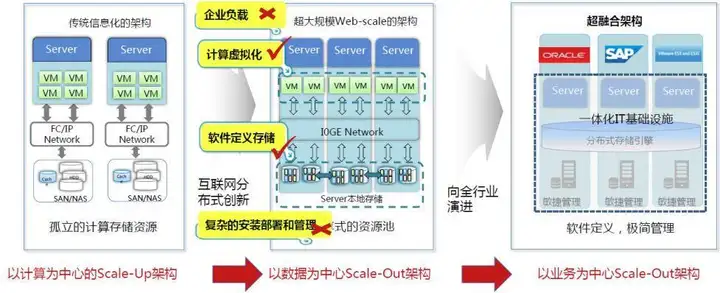
6.超融合架构如何帮组企业实现最好的转型?解答:随着时代发展,采用的 x86 服务器+网络+共享存储的传统三层架构逐渐显露出越来越多的弊端,给业务的快速扩展造成了较大的影响。主要表现在以下几个方面:
✔ 首先,随着各种业务的不断推出,虚拟机的数量不断快速增长,物理服务器和传统集中存储已不能满足业务快速增长的需求;
✔ 其次,在服务器扩展方面,由于传统物理服务器解决方案部署复杂、实施周期长,不能实现快速交付,从而延缓了公司业务的快速扩展;
✔ 第三,在购买方面,传统解决方案购买流程复杂,周期长,难以实现按需购买;
✔ 第四,在运维管理方面,管理窗口多,部署和运维人员多,运维难度大,对专业技术人员也有大量需求,这给企业带来了较大的人力成本压力;
✔ 第五,在售后服务方面,需要服务器和存储厂商等多方技术进行支持,因而在故障发生的时候,实效型很差,增加丢数据的风险。
在仔细分析公司的实际需求之后,采用新的 IT 架构解决这个难题,并对新架构提出了如下需求:
✔ 首先,由于机房空间有限,需要采用高密度的架构解决方案。在有限的空间里满足网络、存储、计算的要求;
✔ 其次,要求该架构弹性可扩展,并且具有稳定可靠、易于维护、高性能的特性;
✔ 第三,由于传统架构无法实现持续的可扩展性,使得性能无法保证。很多创新业务转型,互联网规模化的特点都需要高可靠及可持续的服务能力;
✔ 最后,互联网金融企业的规模化增长,业务规模无法预测,资源的变更频繁,需要及时满足不同业务的资源配置需求,持续降低运维成本和机房设施成本。
因此,新的 IT 架构应采用与互联网企业类似的 IT 架构——超融合架构。
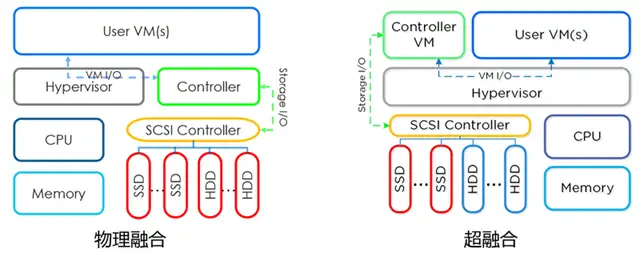
讨论问题总结二、国内外超融合产品的主要区别1.各个厂商之间的超融合产品的区别是什么?解答:HCI基础架构产品主要分为两大类:
第一种:纯软件方案,例如Nutanix和VMware的EVO:RAIL,支持安装到X86架构的服务器上,只需要购买软件许可授权即可,使用方便灵活。
第二种,软硬结合,例如Nutanix软件+联想X86服务器就变成了联想HX超融合一体机,VMware的EVO:RAIL+EMC(DELL)的X86服务器就变成了VxRail超融合一体机。购买硬件的好处是使用方便,开箱即用,稳定性也比自己组装的要好,安全可靠有保障。
目前市场上的超融合架构产品都是基于这两类产品进行销售。
二者怎么选择?建议技术型企业选择软件方案,使用灵活又可以降低成本。如果想省事,就直接购买硬件产品,部署又快又方便。
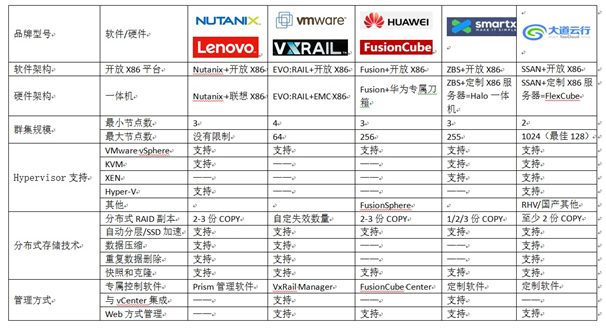
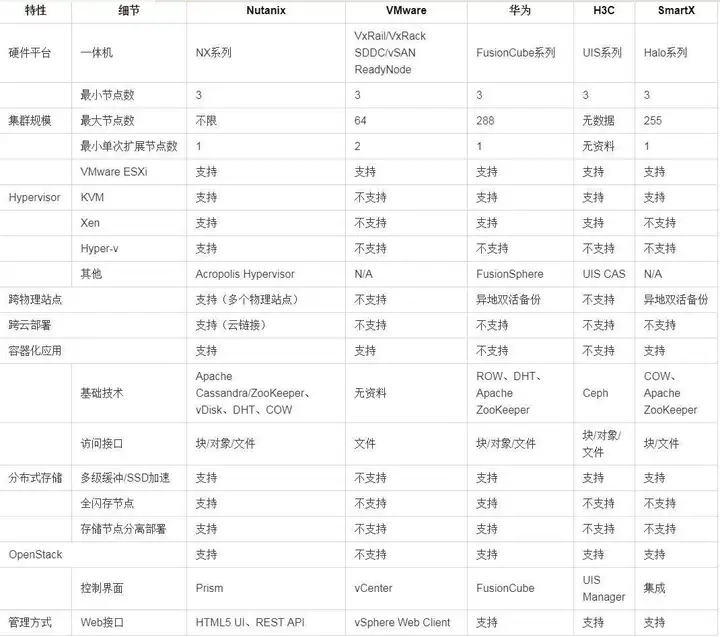
以下是目前主流的5个厂商的超融合架构产品分析,可以看到:
1、国外产品在虚拟化产品支持方面比较保守,只支持特定的Hypervisor ,而国内的厂商除了华为(只支持自家的和VMware),对Hypervisor 的支持都比较好。
2、群集规模,除了Nutanix,或多或少都有一些限制,都不是完全能够做到无限扩展,因为群集规模越大,管理和性能平衡上都是一个巨大的挑战。
3、目前国内外厂商都有纯软件和一体机的方案,大家可以按需选择。
4、分布式存储技术,做为超融合的核心技术,目前各超融合厂商的技术都做的比较好。但是国外的厂商Nutanix和VMware VSAN都是自己研发的,国内的厂商都是基于开源产品自己优化和修改的。优点是开放性比较好,缺点是稳定性可能会稍弱一些。
5、在管理方式上,各家都有自己的管理工具,都支持B/S的管理模式。
QQ图片20170502093843.png
下面是一些产品的优势对比分析:
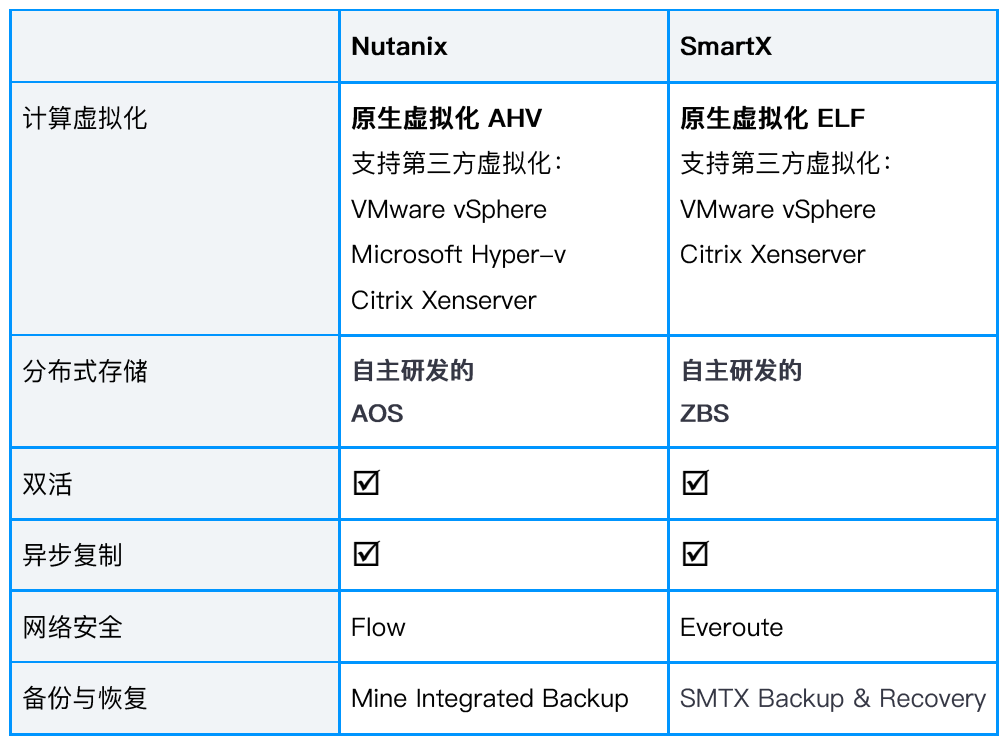
1、Nutanix
优势:
超融合基础架构市场的领导者,Nutanix已经部署在全球6000+家企业,并且是公认的最领先的分布式文件系统,拥有美国专利与商标局正式批准的分布式软件架构专利(US8,601,473).
Gartner2015/2016:魔力象限,Nutanix是集成系统的领导者
品牌知名度很高,具有深厚的技术沉淀,产品功能稳定完善,超融合生态链中具有无可比拟的优势。
全球白金赞助商Dell,Lenovo
全球金牌赞助商Mellanox,Commvault,Citrix,
合作伙伴Veeam,中科慈航,英迈中国,偉仕佳杰,博雅软件,长虹佳华等。
不足:
只提供一体机的方案,价格昂贵,不支持服务器利旧。
如支持的Vmware和Hyper-V计算虚化,客户需要从第三方单独购买授权。
Nutanix是VMware的合作伙伴,但现在已经变成最大(潜在)的竞争对手,虽然合作尚在。
松耦合带来CVM消耗资源较高,至少要24GB内存,8个vCPU。
Nutanix售后服务不足:
计算和存储分离,出故障容易扯皮;
本土没有研发团队
2、Vmware
①VxRail 最小规模4节点起配,扩展时只能以2 节点为单位进行扩展,只能扩展同型号节点,由于VxRail目前的配置型号是固定的,无法灵活定义计算资源和存储资源的数量;
②VxRail只能使用vSphereEnterprise Plus License;
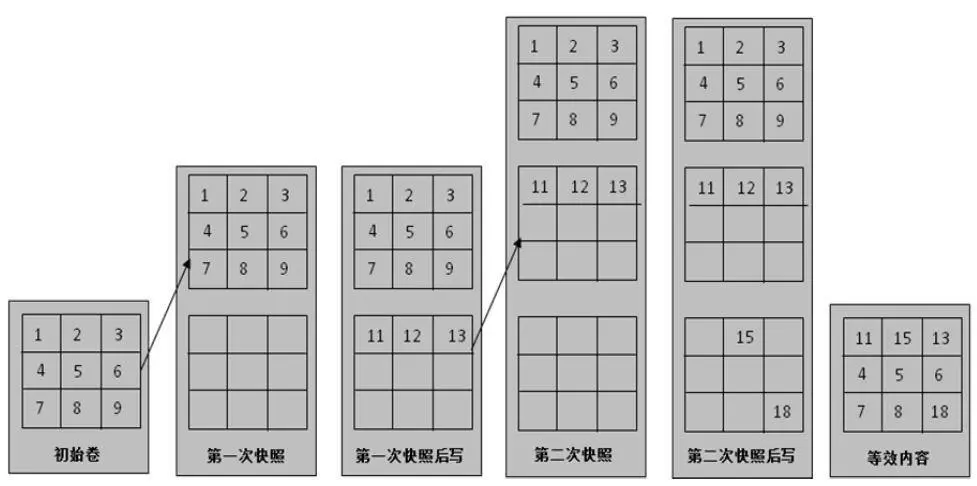
③只支持vSphere快照,VMware 推荐快照链不超过2-¬‐3 个,且单个快照不超过24-¬72小时,以免影响虚拟机性能;
④无内置链接克隆功能,无法快速、批量部署虚拟机;
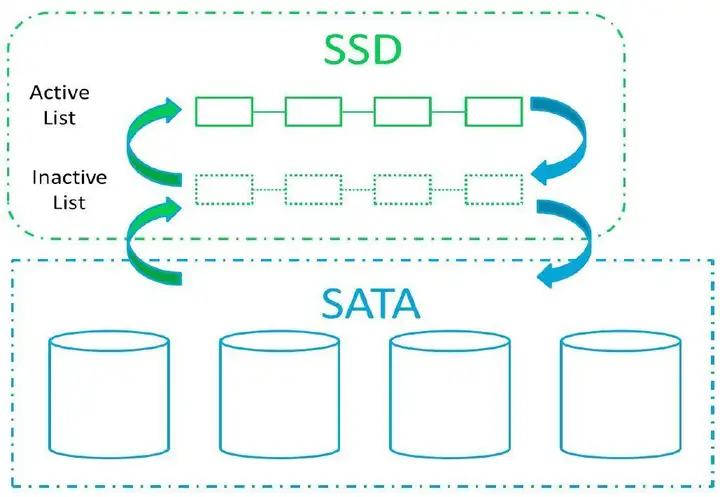
⑤不支持冷热数据分层,70%的SSD 作为Cache 使用;
⑥不支持数据本地化,尽可能保留数据在节点本地,避免不必要的跨网络数据访问,以实现快速的本地IO吞吐;
⑦不支持数据自动平衡,无法对每个节点本地磁盘容量进行数据平衡,在不影响数据本地访问的情况下,保证所有节点磁盘利用率基本一致;
⑧Dell由三家公司组合而成,内部关系复杂,有竞争有合作,产品整合任重道远;
1.Vmware纯软派:vSphere+VSan
2.VCE联盟集成派: Vmware+服务器+EMC存储服务
3.Dell OEM派: Nutanix软件+Dell服务器
⑨本地响应过慢、定制需求无法实现。
3、深信服
品牌知名度高,渠道丰富
深信服做网络安全出身,所画即所得的部署模式和网络层的深度集成却让人印象深刻,非常适合SMB客户从网络安全到基础架构的一揽子交付需求。
配合虚拟桌面方案,优势明显(虚拟桌面的性价比很高)
深信服超融合系统采用GlusterFS,其优势:
①扩展性和高性能
②高可用性
③全局统一命名空间
④弹性哈希算法
⑤弹性卷管理
⑥基于标准协议
劣势:
2015年10月份加入了超融合的战场,坦率的说在狭义的超融合架构(服务器+存储+虚拟化)上平淡无奇。
GlusterFS不是一个完美的分布式文件系统,这个系统自身有许多不足之处,包括众所周知的元数据性能差和小文件存储效率和访问性能很差。
①底层文件系统更适合一次写入多次读取,实际处理性能会比元数据系统差很多。当集群规模变大以及文件数量达到百万级别时,性能直线下降。(销售内部不推超过10个节点以上的方案)
②集群管理模式采用全对等式架构,大规模集群管理应该是采用集中式管理更好,不仅管理简单,效率也高。
③全对等式架构导致每次文件读写请求响应都是广播行为,所有节点都要参与一致性检查,其网络负担比较重。
4、H3C VS HuaWei
优势:
大品牌,大集成商,大客户,大规模,软硬件产品线丰富,各种集成方案
不足:
非专业超融合厂商
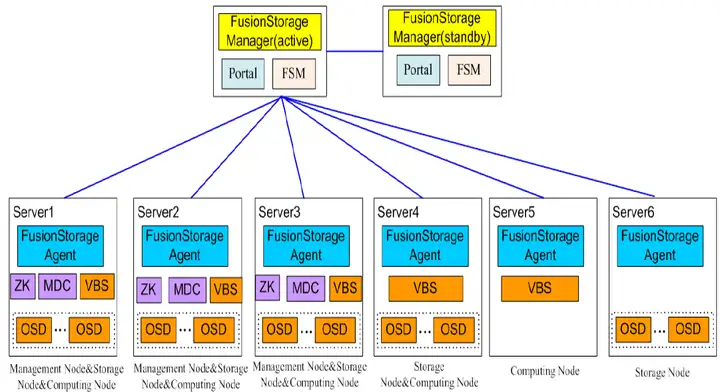
Huawei从FusionCube拆分出来的FusionStorage,通过Hypervisor集成或作为其堆栈的一部分而摇身一变成为时髦的“超融合”,但从规格、指标来看,与“原生”的超融合架构仍然存在差距(仍然基于存储SAN 架构)
Huawei的FusionStorage则除了支持VMware和KVM外,自己也有基于Xen开发的FusionSphere虚拟化平台。
专业专注其硬件销售,华为华三互为主要竞争对手,关注于大型方案,对中小企业客户关注不多,整体方案硬件成本高,采用传统服务器产品。
联想
优势:
超融合不需要存储,但一定要部署在服务器上。而服务器则是联想企业级最强的地方,与Nutanix合作推出的超融合HX系列,基于最好的x86服务器System x,目标成为超融合市场的标杆产品。
不足:
联想自身,没有自己的存储核心技术(缺少存储技术底蕴)。
多条产品线,内部竞争和销售策略混乱
产品推广问题多多:联想除了推荐自己的LenovoAIO产品线,同时还收购了SmartX的产品线。在OEM的Nutanix产品的同时,还跟SimpliVity进行产品合作,国内还跟Maxta产品合作。SimpliVity是Nutanix的主要竞争对手。而SimpliVity又是联想服务器在全球主要竞争对手的——思科(全球x86服务器市场,联想排第3,思科排第4)的战略合作伙伴,后者的OEM销售额占到了SimpliVity收入的20%。
HPE收购了SimpliVity!!!
2.国内外超融合架构/方案的差别具体体现在哪些方面?解答:国外厂家都基本采用自己的产品,而国内厂家,基本采用开源的方式。除了产品成熟度方面,国外厂商产品一般在技术上比较封闭。国内产品比较开放,支持的虚拟化平台也比较多。
还有就是价格方面了,国内肯定要便宜一些。
3.传统制造企业在超融合系统上的对比选择?客户现有几台物理服务器,各自单独运行OA、ERP、测试等业务系统,又新买了2台IBM3650服务器。
但是现在,客户出于数据安全(不丢数据)的考虑,出于业务系统稳定性的考虑:
1.在传统存储和超融合之间选择困惑?简单说明即可
2.比较倾向超融合,但是超融合又在国外大厂VMware VSAN、CISCO 超融合和国内华为、以及国内炒的比较多的深信服之间选择困惑?这几家优劣或区别是什么?如何选择能在低风险的情况下降低成本?
解答:具体解决方案如下:
问题1解答:
(一) 传统架构的短板
1.业务系统为典型的传统三层数据中心架构,即存储、计算、网络分离,数据IO的处理效率底。业务端的数据最终都是要落到磁盘端的,当业务数据产生后需要经过计算、网络、存储三层才能完成交互,数据IO需要在各层之间中转,总体IO处理效率水平底。
2.客户使用的传统SAN存储,存在单点故障。采用传统的RAID冗余保护机制。性能提升只能靠购置更高端设备或增加RAID中磁盘数量。每次升级都需要对数据存储空间重新配置。不能在线平滑升级,需要中断业务后才可操作。
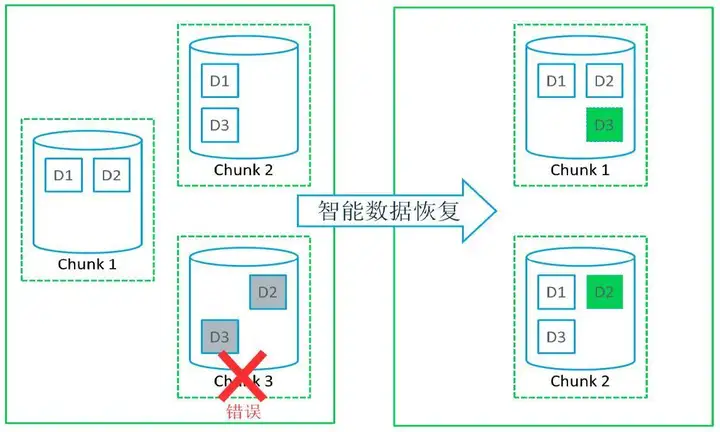
3.缺少对于生产磁盘故障的连续保护能力,当前存储系统仅实现了磁盘RAID组功能,一旦RAID组坏盘降级,存储系统将处于无保护的“裸奔”状态,若此时再坏盘,数据将有可能丢失,所以在当前生产系统环境下,数据安全性和业务的连续性将面临极大挑战。
(二) 运维和扩容的难点
1.数据中心臃肿,多种业务、多种设备,不断建立设备差异,业务业务信息孤岛,异构环境,给IT管理成本增加。数据中心规模增大,也带来了能耗,UPS配备、灭火器、精密空调设备、7x24小时运行、监控服务等,这种数据中心的运行成本非常高。
2.随着业务的不断发展,考虑未来业务系统对底层架构性能、容量、扩展性、处理效率等方面需求增长,以及实时备份策略对性能、扩展性和网络环境要求,需要建立面向云数据中心的基于横向扩展的超融合架构支撑未来备份乃至存储业务的发展要求。
3.业务数据增长迅速,如果按传统备份存储方式操作,当前存储和备份设备均为Scale-up纵向扩展架构设备,容量扩展通过后端SAS链路串接扩展柜实现,存在天然的扩展瓶颈(增加扩展柜后会带来SAS链路信号衰减问题,性能衰减严重),未来备份系统包括存储系统将会承载非常大的数据压力且存在扩容瓶颈。
问题2解答:
各家都各有特色,优缺点也很明显,超融合目前没有很完美的,还在发展,还需要方案验证!个人推崇Nutanix,但是很贵!深信服更贴合它的虚拟桌面卖。纯粹超融合的方案,缺少大规模部署案例,因为他目前的底层GFS文件系统不适合大规模部署(具体可以百度GFS补足)。
超融合未必比传统架构便宜。
补充几点说明:
问题1、在传统存储和超融合之间选择困惑?
如果选择超融合架构,存储就可以不用考虑了。
数据安全性,超融合一个数据可以有2-3个副本,安全性高于存储。
性能,超融合需要达到一定规模,性能才能高于存储,如果业务量小,规模下,只买几个超融合服务器,性能肯定不如存储。
问题2、补充
看你虚拟化怎么选,如果认定VMWARE虚拟化软件,那就用VSAN。华为也只支持自己的FusionSphere和VMWARE。如果有多种虚拟化平台,就选国内比较开源一些的。
成本上,国外产品一般都比较贵。
降低风险,选择产品前先做POC测试,然后尽量选择一体化硬件产品。Nutanix(联想HX)、VMware(EMC VxRail)、华为(FusionCube一体机)、SMARTX(Halo硬件)、大道运行(FlexCube硬件)。不要选择软件产品,自己组装。
4.超融合是否可以支持Power设备,与Power设备区别?在企业采购越来越多的设备的同时应该更多的考虑设备的数量,空间,功耗等方面,排除应用结合平台和架构的耦合性来说,超融合在节能减排上是如何的一个考虑,是否可以支持Power 设备强劲的处理能力环境。
解答:IBM有个融合架构叫pureflex,但好像一直没啥好口碑。
超融合基础架构起源:Web-scale IT:如Facebook,谷歌等公司新一代数据中心,实现灵活性、扩展性基础架构服务
事实上,这一概念最早源于存储初创厂商将Google、Facebook等互联网厂商采用的计算存储融合的架构用于虚拟化环境,为企业客户提供一种将存储做到计算服务器中的融合产品。“因此,超融合架构最核心的改变是存储,而这一概念的最初推动者也都是来自于互联网背景的存储初创厂商。
目前定义的超融合是基于X86服务器的,Power设备很难融入。
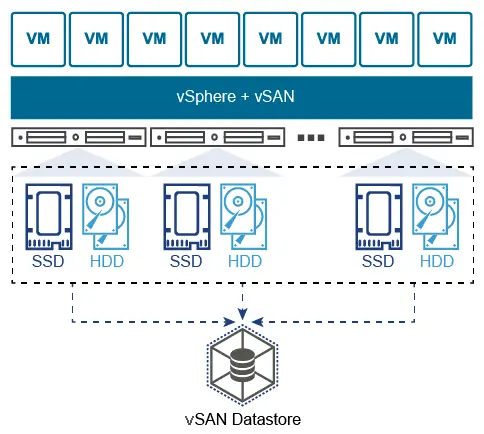
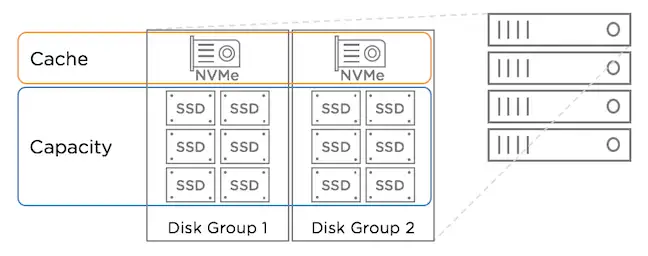
超融合基础架构(简称“HCI”),是指在同一套单元设备(x86服务器)中不仅仅具备计算、网络、存储和服务器虚拟化等资源和技术,而且还包括缓存加速、重复数据删除、在线数据压缩、备份软件、快照技术等元素,而多节点可以通过网络聚合起来,实现模块化的无缝横向扩展(scale-out),形成统一的资源池。
在POWER设备内,只能做到POWER VM虚拟化,网络和存储无法进行虚拟化,需要依靠传统网络和存储设备,所以单独依靠POWER设备是无法超融合的,在节能减排上,只能做计算资源虚拟化。
5.请问下国内这些厂商提供的超融合产品价格和传统架构区别?请问现在提供的超融合产品价格大概在什么位置?要切换到这套东西需要做哪些事情呢
解答:融合价格体系是这样的,和传统架构比,举个例子:
在达到相同性能的前提下,X86服务器+超融合软件的价格一定会低于X86服务器+存储+虚拟化软件的架构。大约会便宜1/3左右。
切换到超融合架构,需要了解现有虚拟化环境的配置和将来的需求,根据需要规划超融合架构的规模,然后在选择合适的产品进行采购部署。
6.对比一下宏杉的存储和深信服的超融合架构?如题,想了解下,应该继续使用传统的存储,在存储端做文章还是,使用服务器类型的超融合架构!对于中小型医院讲!后期的维护将来的发展趋势应该选择那种!感谢!
解答:我是这样理解的,传统的存储架构(混合存储、高端存储、全闪存阵列)相比超融合架构,还是有一定的优势的,
超融合强调的是融合,建设服务器、网络、存储之间的交互和故障节点,但是性能和安全可靠,和传统的存储还是无法相比,这就好比鸡蛋都放在一个篮子里是一个道理;
传统的存储(混合存储、高端存储、全闪存阵列),架构和技术都相对成熟,应用场景较多,应用类型较多,案例较多;
超融合通过服务器内安装软件,将服务器内的硬盘作为存储设备,本身和专业做存储的OS和架构上(例如FPGA,超融合是无法使用的)相比,存储的功能、性能、安全、可靠等都是无法相比的,例如超融合必须使用SSD(用来作为缓存)的,这些在专业的存储平台上,是有好多专门的技术来实现的;
存储平台的好多特性,超融合也是无法做到的(分级存储、存储双活等)
再说说医院的HIS 、LIS 、CIS、 PACS,这些业务系统,有些是需要高IOPS低延时的(可以采用全闪存阵列),有些是需要高吞吐量的(PACS)大容量的,如果要想统一解决这些问题,还需要传统的统一存储,超融合是无法满足的
最后说说宏杉,是一家专业做存储的公司,好多医院也在使用,品牌口碑都不错。
讨论问题总结三、国内外超融合产品的技术问题1.超融合设备是否有类似openstack产品升级问题?作为一款开源解决方案,openstack 确实火的不行,很多云环境也是基于openstack进行建立,但是在openstack在建设的过程当中,由于部分模块的缺陷导致在一个版本里不能解决问题,除非升级才有可能解决,但是升级的风险同样是巨大的,那么作为超融合产品是否很好的解决了这方面的问题呢 。
解答:每一家超融合厂家都有自己的升级方式,但是不影响业务不断服务一定是最最基本的要求。这个升级肯定是静默快速的。
最后拼的还是技术底蕴和专业服务。超融合是一套私有云的运维平台,厂家支持必不可少的。
超融合基础架构其实还是软件,是软件定义的基础架构,只要是软件,肯定会有产品升级问题,openstack 遇到的问题,超融合架构一定也会有。
所有产品都会有BUG和升级问题,就拿ORACLE来说,已经是很成熟的商业版本软件了。但是一个新版本的发布都会问题不断,升级又很麻烦,耗时间耗人了,折腾的不行。
风险都是同样存在的,就看我们怎么处理和应对了。
2.超融合技术核心部分是否就是一款软件?普通X86服务器能否加入?如题,如果某一位领导问你,什么是超融合技术,如何概括为一句能让他大体上“听得懂”的语言描述之?是否是一款软件融合服务器及存储与一体的架构?对于我们现有的机房中的普通X86服务器是否能够直接加入“这个圈子”?也就是说需要什么特殊硬件要求吗?
QQ图片20170502093959.png
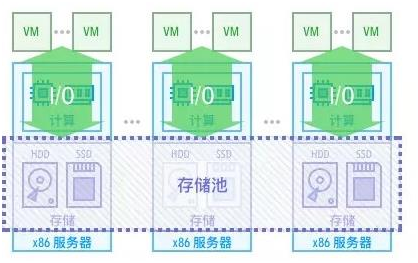
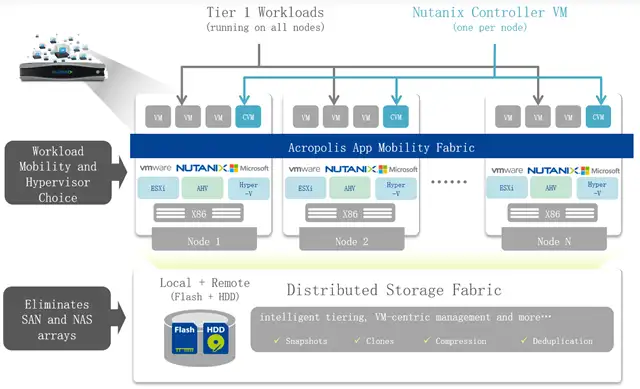
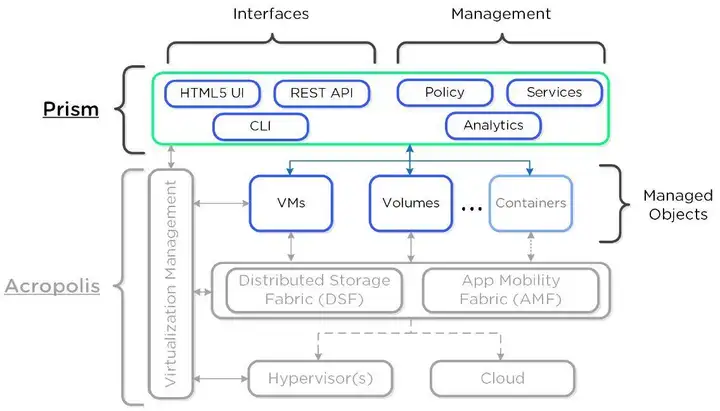
解答:超融合架构将围绕虚拟化计算的存储、网络集成到了同一个硬件盒子中,生态系统涵盖软件和硬件厂商,因其核心是软件。超融合架构的每个机箱,就是一个含有运算与存储资源的基础积木单元,再透过分布式软件将多台机箱组成丛集,就像堆积木般,组成适合不同应用情境的集群。只要将更多节点加入到集群中,就能扩展整个集群的效能与容量。
①使用通用服务器硬件构成基本单元:使用标准的X86服务器硬件,构成集运算与存储单元于一身的基础单元。
②以软件定义方式来运用硬件资源:以虚拟机(VM)为核心、软件定义式的型式来运用硬件资源,资源调派均不涉及底层实体硬件的组态设定调整,纯粹以软件定义方式来规画与运用底层硬件资源,然后向终端用户交付需要的资源。
③集群化架构:透过集群或分布式系统软件,结合多个基础单元机箱成为集群,藉由集群来提供IT环境所必需的硬件资源规模、服务与数据的可用性,以及扩展能力。
④便于快速部署:产品已预先完成软硬件安装测试,用户只需设定基本环境参数便能开始使用。
超融合基础架构核心是一款部署在X86服务器上的软件,部署完成后(至少需要2-3台服务器和交换机),你的这个X86服务器群集就能提供存储资源,计算资源和网络资源了。
核心部分是分布式存储管理软件,如果没有这个,这几个服务器仍然需要一个统一存储设备,那么就不叫超融合了。
下面是超融合基础架构定义”:
超融合基础架构(简称“HCI”),是指在同一套单元设备(x86服务器)中不仅仅具备计算、网络、存储和服务器虚拟化等资源和技术,而且还包括缓存加速、重复数据删除、在线数据压缩、备份软件、快照技术等元素,而多节点可以通过网络聚合起来,实现模块化的无缝横向扩展(scale-out),形成统一的资源池。
3.超融合产品的扩展性怎么样?会不会绑定某种基础组件或基于某种组件无法扩展或修改?超融合产品的扩展性怎么样?会不会绑定某种基础组件或基于某种组件无法扩展或修改?
如:绑定了某些组件,但是这些组件客户不想使用或修改后使用
解答:超融合产品扩展能力非常强,通常一个群集的规模可以达到在3-200多台。超融合产品的扩展一定基于同一款超融合架构软件才能实现的,组件一般都是可选的,按照功能需求进行选择,组件可以不要不使用,但是不能修改。
4.超融合是基础架构,但是否可以进行定制个性化超融合架构作为基础架构,是厂家弄好了直接用还是说可以进行定制,比如自己团队进行一些定制。其技术是否开放?
解答:超融合架构产品主要分为两种销售模式:
第一种:纯软件方案,例如Nutanix和VMware的EVO:RAIL,支持安装到X86架构的服务器上,只需要购买软件许可授权即可,使用方便灵活。
第二种,软硬结合,例如Nutanix软件+联想X86服务器就变成了联想HX超融合一体机,VMware的EVO:RAIL+EMC(DELL)的X86服务器就变成了VxRail超融合一体机。购买硬件的好处是使用方便,开箱即用,稳定性也比自己组装的要好,安全可靠有保障。
以上,你可以买厂家弄好的,也可以买软件,自己安装到X86服务器上,自己组建超融合基础架构。定制的话,你可以选择超融合软件的功能,不能自己做二次开发。
比如,对于超融合基础架构存储,你可以选择是否支持压缩、自动分层、重删等功能,副本数量2或3个,是否支持复制等。但是厂商没有的功能,就定制不了了。
关于开放性,部分超融合支持的虚拟化平台是开放的,比如VMWARE或OPENSTACK等
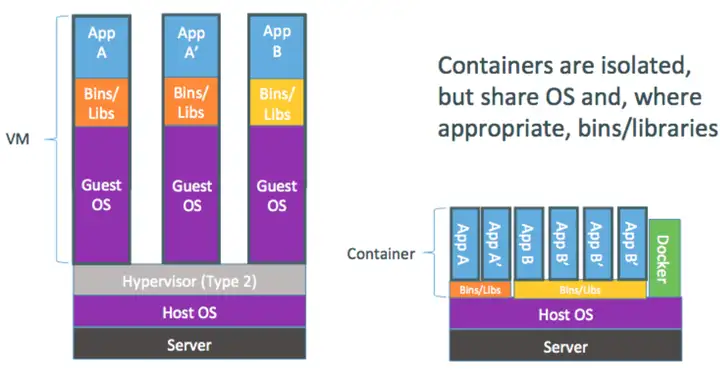
5.超融合感觉还在用传统的虚拟技术,未来会与现在流行的docker这套东西整合吗?超融合感觉还在用传统的虚拟技术,未来会与现在流行的docker这套东西整合吗?
解答:会。国内已经有生产案例了。
docker还在发展中~超融合很多都采用opstack管理框架,自然使用融合没有问题.
超融合和docker的发展其实并不冲突,超融合其实是基础架构设施,包括计算服务和存储服务。未来会与docker融合在一起的,而且有了超融合基础架构,docker还可以更方便的使用。因为docker也只能替代一部分VM的功能,也就是计算服务,数据存储服务还需要超融合基础架构实现。
6.超融合下的备份和集中监控如何实现?超融合下的虚拟机和存储通常都是虚拟化之后的文件,各家厂商都不一样,那对于备份来说,是基于传统的备份,还是有专门的备份方式?能否详细介绍下?
集中监控是采用传统的方式还是和超融合软件一起封装了?能否实现统一集中化的监控?
解答:在备份方面。超融合架构备份没有差别!跟传统架构的备份一样!超融合架构和传统备份基本没有什么区别。但是备份这块,超融合还有一个优势就是超融合的数据存储是多副本的,一般都为2-3份甚至多个COPY,即使一部分服务器坏掉数据也不会丢,所以在数据安全性上要高一些。基于这个基础,超融合的备份工作量可以减少一些,不是说不需要备份,在备份的数据量和保留周期上都可以适当缩短一些,减少备份投资成本。
在集中监控方面。现统一集中化的监控是必须的!!!
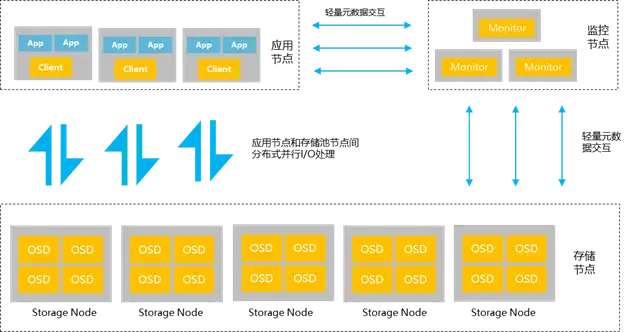
超融合就是计算存储网络的虚拟化技术,加上一个完整的统管平台~
有自研的,有openstack修改的,就是一套监控平台。
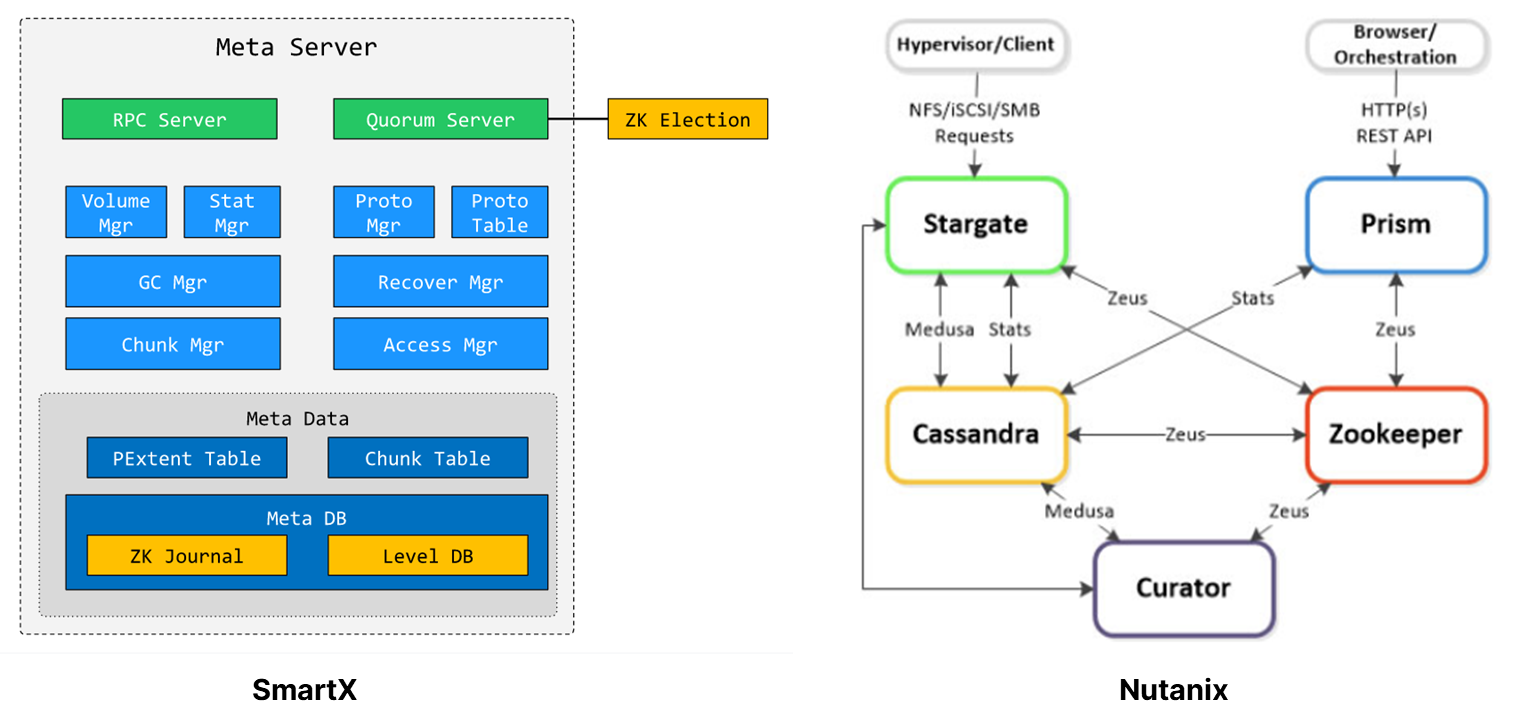
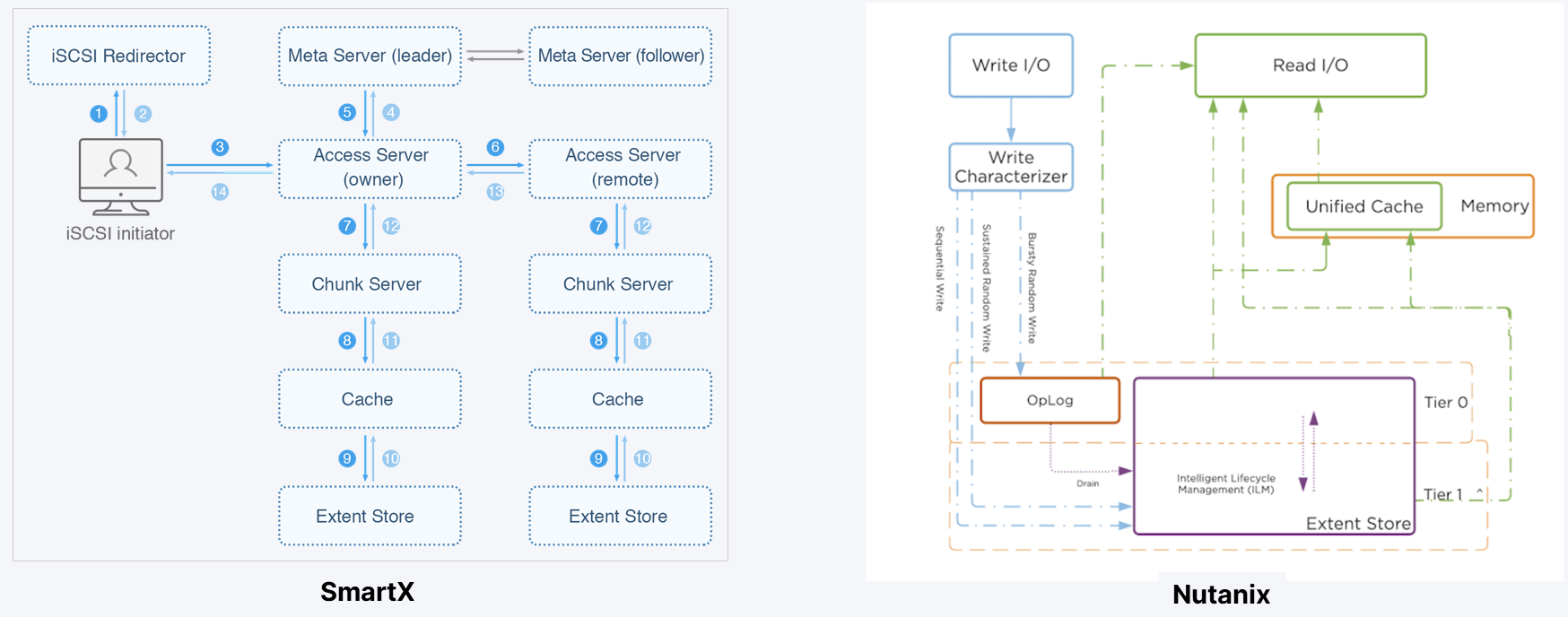
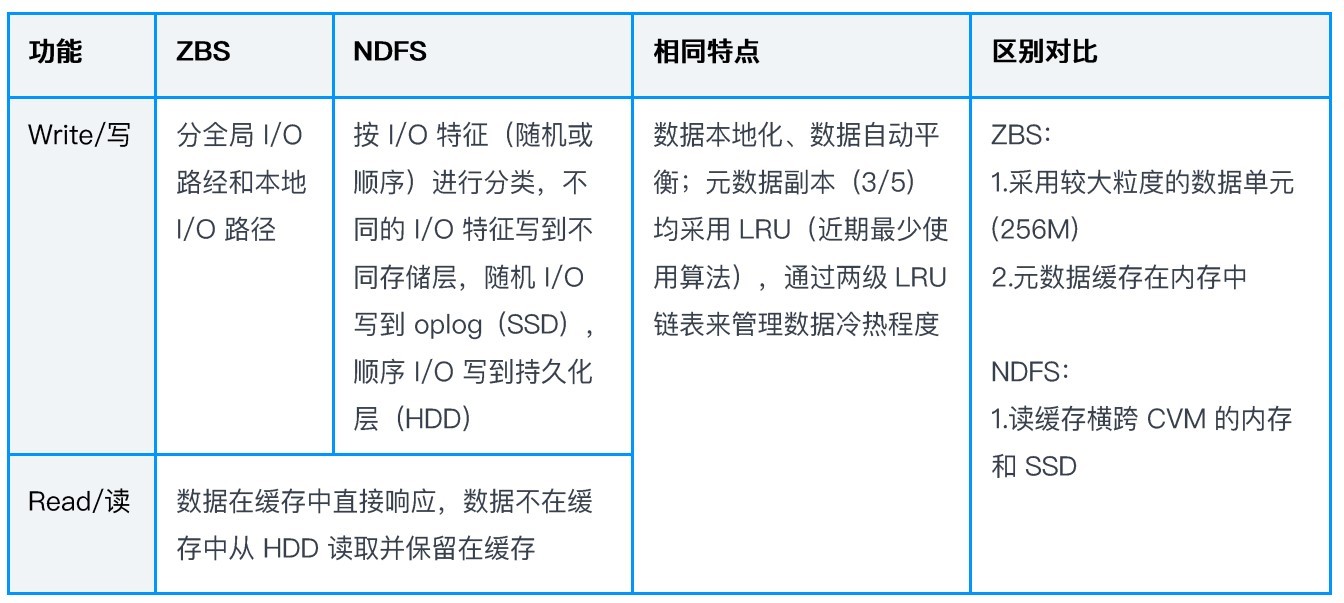
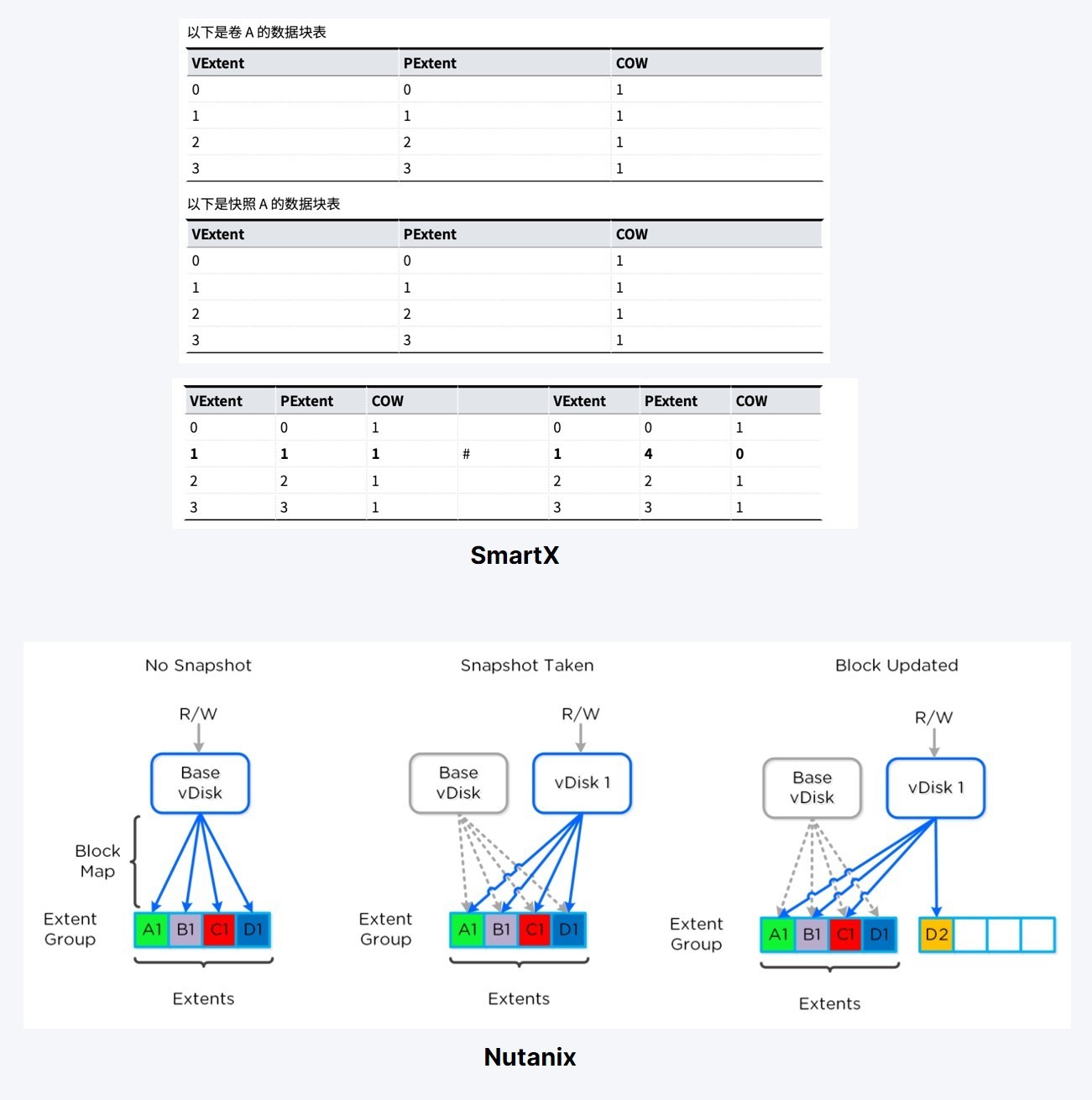
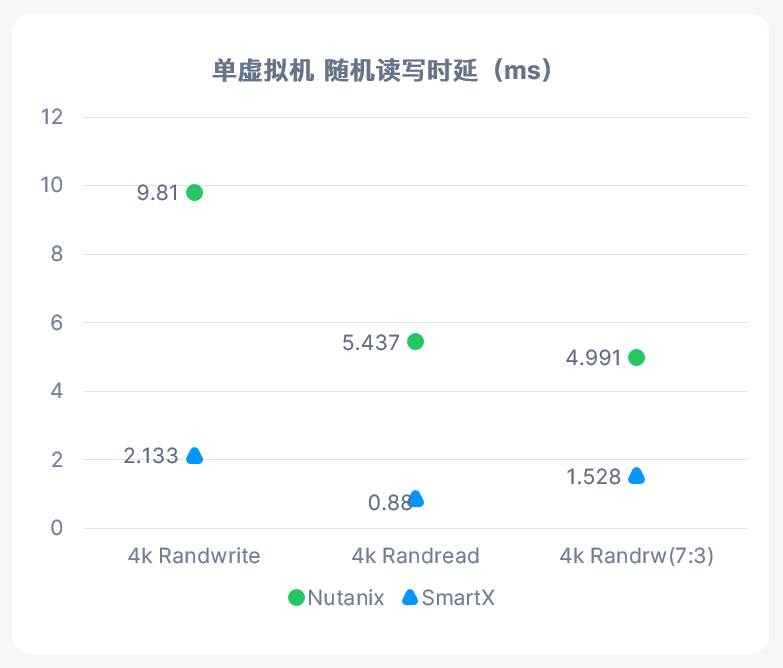
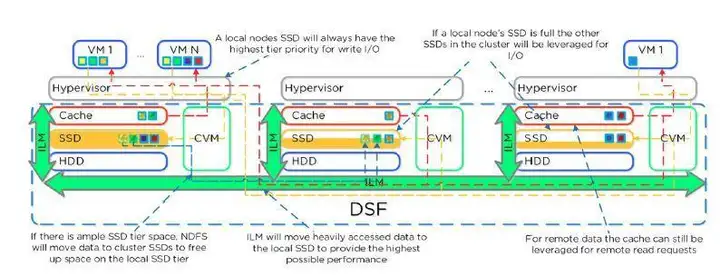
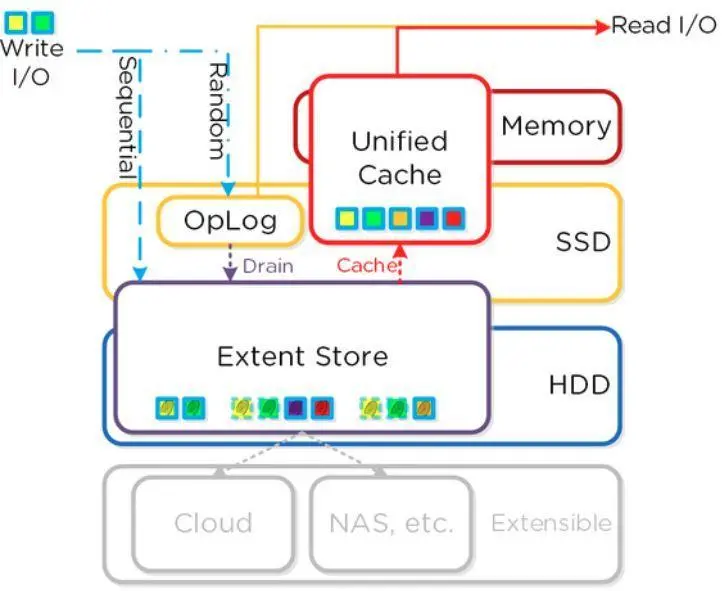
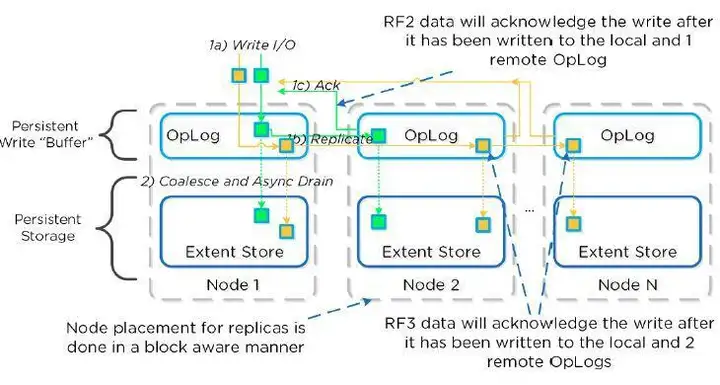
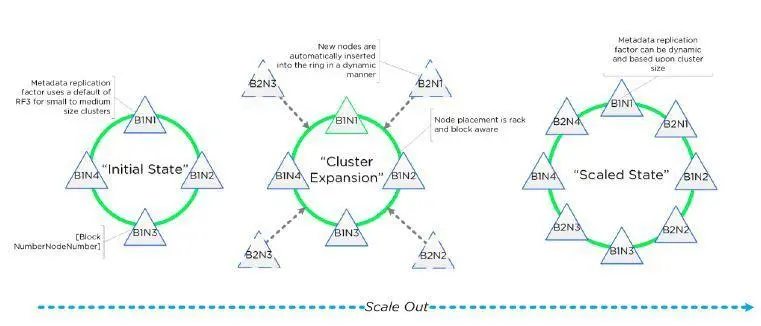
有时间看看Nutanix的产品架构,很容易理解。
超融合架构下的监控都是各个超融合基础架构厂商自己的产品,超融合基础架构对设备的管理要求比较高,因为一个超融合架构需要许多物理机组成。如果没有监控管理平台是无法想象的。所以在超融合架构下,一定是集中监控的,就看你选用哪个厂商的产品了,都配置有相应的集中监控平台。一个超融合平台,计算服务、存储服务、网络服务和监控服务都是融合在一起的。


 IP卡
IP卡 狗仔卡
狗仔卡 发表于 2023-1-30 12:20:08
发表于 2023-1-30 12:20:08





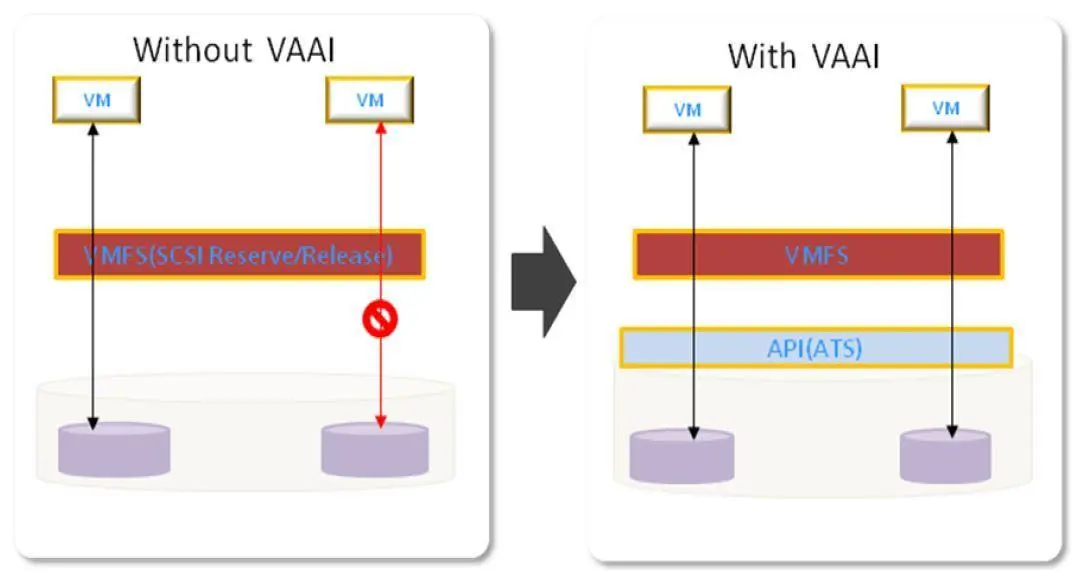
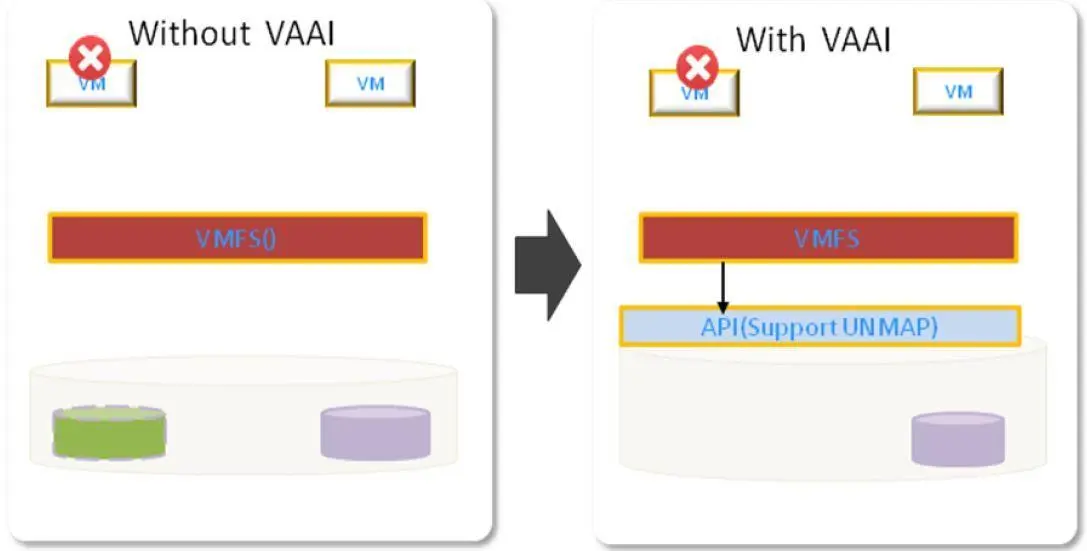


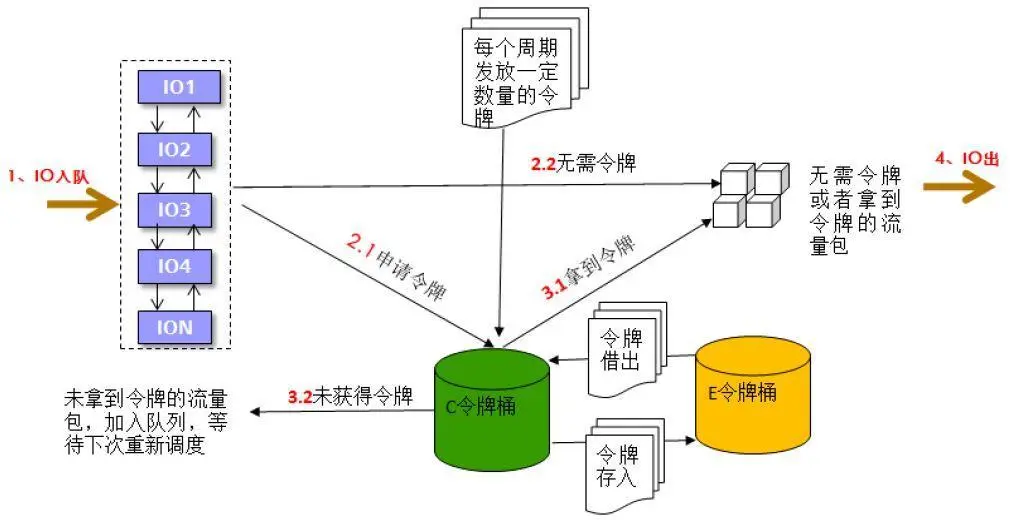
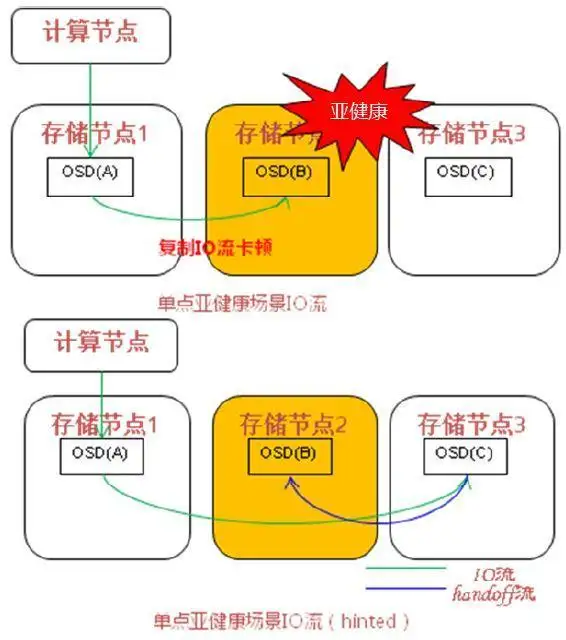

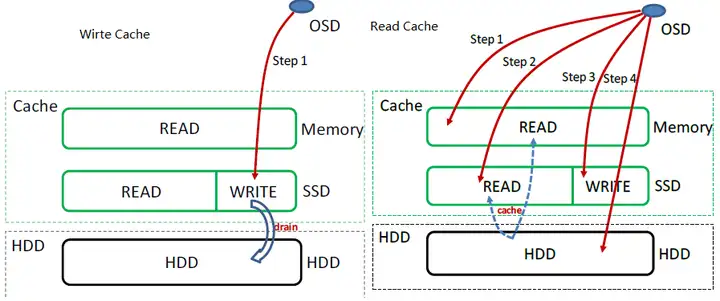
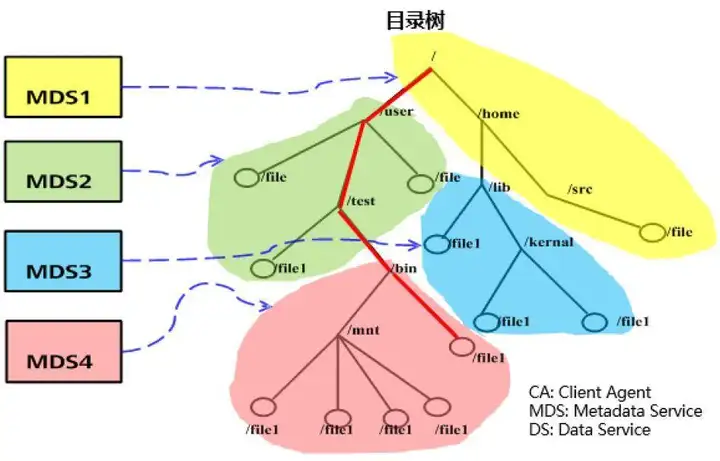

 [/url]
[/url] 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡