|
AMD在 2023 年国际消费电子展上推出了其下一代 Instinct MI300 加速器,我们有幸获得了一些动手时间,并拍摄了几张这款庞大芯片的特写照片。
毫无疑问,Instinct MI300 是一个改变游戏规则的设计——这个数据中心 APU 混合了总共 13 个小芯片,其中许多是 3D 堆叠的,以创建一个具有 24 个 Zen 4 CPU 内核并融合了 CDNA 3 图形的芯片引擎和 8 堆 HBM3。总体而言,该芯片拥有 1460 亿个晶体管,是 AMD 投入生产的最大芯片。

MI300 拥有 1460 亿个晶体管,轻松超过英特尔的 1000 亿个晶体管Ponte Vecchio,再加上 128GB 的HBM3 内存。考虑到其闪亮的外观,去边芯片很难拍摄,但您可以清楚地看到中心芯片侧面的八个 HBM3 堆栈。在这些 HBM 堆栈之间放置小的结构硅片,以确保在封装顶部拧紧冷却溶液时的稳定性。

该芯片的计算部分由九个 5nm 小芯片组成,它们是 CPU 或 GPU 内核,但 AMD 没有详细说明每个小芯片的使用数量。Zen 4 内核通常部署为八核裸片,因此我们可以查看三个 CPU 裸片和六个 GPU 裸片。GPU 芯片使用 AMD 的 CDNA 3 架构,这是 AMD 数据中心专用图形架构的第三次修订。AMD 没有指定 CU 数量。

这九个裸片被 3D 堆叠在四个 6nm 基础裸片之上,这些裸片不仅仅是无源中介层——我们被告知这些裸片是有源的,可以处理 I/O 和各种其他功能。AMD 向我们展示了另一个 MI300 样品,该样品的顶部裸片用砂带打磨机打磨掉,以揭示四个有源中介层裸片的架构。
在那里,我们可以清楚地看到不仅可以在 I/O 块之间实现通信的结构,还可以看到与 HBM3 堆栈接口的内存控制器之间的通信。但我们不允许拍摄第二个样本。
3D 设计允许在 CPU、GPU 和内存芯片之间实现令人难以置信的数据吞吐量,同时还允许 CPU 和 GPU 同时处理内存中的相同数据(零拷贝),从而节省电力、提高性能并简化编程。看看这个设备是否可以在没有标准 DRAM 的情况下使用将会很有趣,正如我们在英特尔的 Xeon Max CPU中看到的那样,它也采用了封装 HBM。
AMD 不愿透露细节,因此不清楚 AMD 是使用标准的 TSV 方法将上下裸片熔合在一起,还是使用更先进的混合键合方法。我们被告知 AMD 将很快分享有关封装的更多细节。
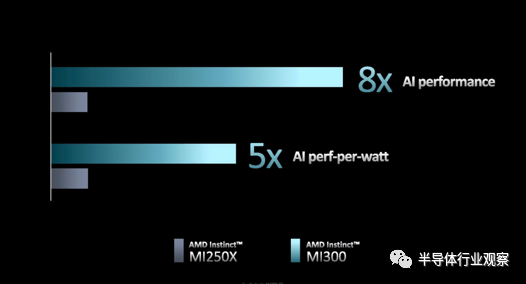
AMD 声称 MI300 提供的 AI 性能是 Instinct MI250 的八倍,每瓦性能是Instinct MI250的五倍(使用具有稀疏性的 FP8 测量)。AMD 还表示,它可以将 ChatGPT 和 DALL-E 等超大型 AI 模型的训练时间从几个月缩短到几周,从而节省数百万美元的电费。
当前一代的 Instinct MI250 为 Frontier 超级计算机提供动力,这是世界上第一台百亿亿级计算机,而 Instinct MI300 将为即将推出的两台 exaflop El Capitan 超级计算机提供动力。AMD 告诉我们,这些 halo MI300 芯片价格昂贵且相对稀有——它们不是大批量产品,因此它们不会像EPYC Genoa 数据中心 CPU那样得到广泛部署。但是,该技术将过滤到不同外形的多种变体。
该芯片还将与Nvidia 的 Grace Hopper Superchip竞争,后者在同一块板上结合了 Hopper GPU 和 Grace CPU。这些芯片预计将于今年上市。基于 Neoverse 的 Grace CPU 支持 Arm v9 指令集,并且系统配备了两个与 Nvidia 新品牌 NVLink-C2C 互连技术融合在一起的芯片。AMD 的方法旨在提供卓越的吞吐量和能效,因为将这些设备组合到一个封装中通常比连接到两个单独的设备时能够在单元之间实现更高的吞吐量。
MI300 还将与 Intel 的Falcon Shores竞争,该芯片将具有数量不等的计算块,具有 x86 内核、GPU 内核和内存,具有令人眼花缭乱的可能配置,但这些配置要到 2024 年才会到货。 
在这里,我们可以看到 MI300 封装的底部以及用于 LGA 安装系统的接触垫。AMD 没有分享有关插槽机制的详细信息,但我们一定会尽快了解更多信息——该芯片目前在 AMD 的实验室中,该公司预计将在 2023 年下半年交付 Instinct MI300。El Capitan超级计算机将在 2023 年部署时成为世界上最快的超级计算机。目前正在按计划进行。
| 

 IP卡
IP卡 狗仔卡
狗仔卡 发表于 2023-1-9 06:09:59
发表于 2023-1-9 06:09:59




 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡 楼主
楼主