最新显卡RTX3090、RTX3080ti、RTX3080详细技术参数与应用加速分析(修正)
地球最强--支持6块RTX3090静音级深度学习工作站硬件配置 http://www.xasun.com/article/95/2442.html




nvidia 的Amper(安倍)架构显卡上市,和上一代Turing(图灵)架构显卡相比,性能提升显著 技术参数对比表:
关键指标 | RTX 3090 | RTX 3080 | RTX 3070Ti | Titan RTX | RTX 2080Ti | 备注 | GPU 基频MHz | 1410 | 1410 | 1410 | 1350 | 1350 |
| GPU自动超频MHz | 1695 | 1710 | 1695 | 1770 | 1545 |
| 内存等效频率MHz | 19496 | 19000 | 16000 | 14000 | 14000 |
| CUDA核 | 10496 | 8704 | 6144 | 4608 | 4352 | 关键指标 | TMUs紋理單元 | 328 | 272 | 192
| 288 | 272 |
| ROPs光珊單元 | 112 | 96 | 64
| 96 | 88 |
| Tensor核数 | 328 | 272 | 192
| 576 | 544 | 深度学习关键指标 | RT核数 | 82 | 38 | 48
| 72 | 68 |
| 显存 | 24GB | 10GB | 16GB | 24GB | 11GB | 关键指标 | 显存位宽bits | 384 | 320 | 256 | 384 | 352 |
| 显存带宽GBs | 936 | 760 | 512 | 672 | 616 | 关键指标 | 像素填充率GPs | 163 | 150 | 108 | 170 | 136 | 图形生成指标 | 纹理填充率 | 556 | 465 | 325 | 510 | 420 |
| 半精度FP16 Tflops | 35.58 | 29.77 | 20.83 | 32.62 | 26.90 | 深度学习性能指标 | 单精度FP32 Tflops | 35.58 | 29.77 | 20.83
| 16.31 | 13.45 | 时域/显式计算指标 | 功耗W | 350 | 320 | 250 | 280 | 250 |
| 实际功耗 | 400 | 360 | 280 | 315 | 315 |
| 供电口 | 1x12-pin | 2x8-pin | 1x8-pin | 2x8-pin | 2x8-pin |
|
新卡上市时间: RTX3080 10GB 2020年9月17号 RTX3090 24GB 2020年9月24号 RTX3070 8GB 2020年10月 RTX3080 20GB 2020年 RTX3070Ti 16GB 2020年 第二代RTX卡对UltraLAB图形工作站在下面应用,有什么提升呢
1 科学与仿真计算方面
1.1 基于时域算法的电磁仿真计算提升,相关机型:GT410P、GX630M、Alpha730
1.2 基于GPU加速的分子动力模拟提升,相关机型:GX630M 显卡推荐:单精度浮点指标性价比最高的RTX3080Ti
2 3D图形设计方面
2.1 3D模型实时生成与即时渲染 相关机型:H380 显卡推荐:像素填充率、显存带宽两者兼顾,RTX3090、RTX3080Ti
3 图像处理方面
3.1 无人机航拍影像处理、倾斜摄影建模, 相关机型:H380 显卡推荐:像素填充率、显存带宽两者兼顾,RTX3080、RTX3080Ti
4 视景仿真方面
4.1 大型三维场景、科学可视化、三维GIS应用,相关机型:V390
显卡推荐:像素填充率、显存带宽两者兼顾,RTX3090、RTX3080Ti
5 影视后期方面
5.1 4K/6K/8K视频编解码计算,相关机型:GT400M
5.2 3D渲染计算加速,相关机型:H390、GT400M
显卡推荐:像素填充率、显存带宽两者兼顾,RTX3090、RTX3080Ti
6 深度学习和大数据分析方面
6.1 基于CNN算法的计算机视觉应用加速,相关机型:GX630M
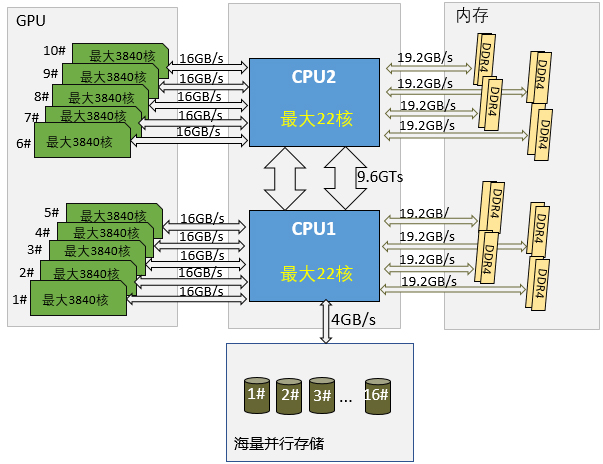
显卡推荐:半精度浮点指标、Tensor核数性价比最高,RTX3080Ti、RTX3070Ti 应用于深度学习,可能问题: (1)功耗问题 新卡的功耗比上一代升幅巨大,RTX3090/RTX3080Ti实际功耗到400w以上,对基于GX630M机型,支持8块GPU卡,可能成为历史,GX630M配备的双2000w电源,也不够用,
(2)散热问题 上一代GPU卡配备涡轮风扇,多卡并行间距空间很窄,进气散热也不错,但是新GPU因为功耗大幅提升,只能用双风扇以上的散热架构,多卡并行原设计间距势必增大 因此,综合上面两个原因,图灵超算工作站GX630M可能支持最多6块卡RTX3090/RTX3080Ti
最新的UltraLAB图形工作站基准配置近期推出 |


 IP卡
IP卡 狗仔卡
狗仔卡 发表于 2021-8-14 06:03:43
发表于 2021-8-14 06:03:43
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡