|
|
作者:微软亚洲研究院
链接:https://www.zhihu.com/question/19895141/answer/149475410
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
针对这个问题,我们邀请了微软亚洲研究院首席研究员周明博士为大家解答。
周明博士于2016年12月当选为全球计算语言学和自然语言处理研究领域最具影响力的学术组织——计算语言学协会(ACL, Association for Computational Linguistics)的新一届候任主席。此外,他还是中国计算机学会中文信息技术专委会主任、中国中文信息学会常务理事、哈工大、天津大学、南开大学、山东大学等多所学校博士导师。他1985年毕业于重庆大学,1991年获哈工大博士学位。1991-1993年清华大学博士后,随后留校任副教授。1996-1999访问日本高电社公司主持中日机器翻译研究。他是中国第一个中英翻译系统、日本最有名的中日机器翻译产品J-北京的发明人。1999年加入微软研究院并随后负责自然语言研究组,主持研制了微软输入法、对联、英库词典、中英翻译等著名系统。近年来与微软产品组合作开发了小冰(中国)、Rinna(日本)等聊天机器人系统。他发表了100余篇重要会议和期刊论文。拥有国际发明专利40余项。
————这里是正式回答的分割线————
自然语言处理(简称NLP),是研究计算机处理人类语言的一门技术,包括:
1.句法语义分析:对于给定的句子,进行分词、词性标记、命名实体识别和链接、句法分析、语义角色识别和多义词消歧。
2.信息抽取:从给定文本中抽取重要的信息,比如,时间、地点、人物、事件、原因、结果、数字、日期、货币、专有名词等等。通俗说来,就是要了解谁在什么时候、什么原因、对谁、做了什么事、有什么结果。涉及到实体识别、时间抽取、因果关系抽取等关键技术。
3.文本挖掘(或者文本数据挖掘):包括文本聚类、分类、信息抽取、摘要、情感分析以及对挖掘的信息和知识的可视化、交互式的表达界面。目前主流的技术都是基于统计机器学习的。
4.机器翻译:把输入的源语言文本通过自动翻译获得另外一种语言的文本。根据输入媒介不同,可以细分为文本翻译、语音翻译、手语翻译、图形翻译等。机器翻译从最早的基于规则的方法到二十年前的基于统计的方法,再到今天的基于神经网络(编码-解码)的方法,逐渐形成了一套比较严谨的方法体系。
5.信息检索:对大规模的文档进行索引。可简单对文档中的词汇,赋之以不同的权重来建立索引,也可利用1,2,3的技术来建立更加深层的索引。在查询的时候,对输入的查询表达式比如一个检索词或者一个句子进行分析,然后在索引里面查找匹配的候选文档,再根据一个排序机制把候选文档排序,最后输出排序得分最高的文档。
6.问答系统: 对一个自然语言表达的问题,由问答系统给出一个精准的答案。需要对自然语言查询语句进行某种程度的语义分析,包括实体链接、关系识别,形成逻辑表达式,然后到知识库中查找可能的候选答案并通过一个排序机制找出最佳的答案。
7.对话系统:系统通过一系列的对话,跟用户进行聊天、回答、完成某一项任务。涉及到用户意图理解、通用聊天引擎、问答引擎、对话管理等技术。此外,为了体现上下文相关,要具备多轮对话能力。同时,为了体现个性化,要开发用户画像以及基于用户画像的个性化回复。
随着深度学习在图像识别、语音识别领域的大放异彩,人们对深度学习在NLP的价值也寄予厚望。再加上AlphaGo的成功,人工智能的研究和应用变得炙手可热。自然语言处理作为人工智能领域的认知智能,成为目前大家关注的焦点。很多研究生都在进入自然语言领域,寄望未来在人工智能方向大展身手。但是,大家常常遇到一些问题。俗话说,万事开头难。如果第一件事情成功了,学生就能建立信心,找到窍门,今后越做越好。否则,也可能就灰心丧气,甚至离开这个领域。这里针对给出我个人的建议,希望我的这些粗浅观点能够引起大家更深层次的讨论。
建议1:如何在NLP领域快速学会第一个技能?
我的建议是:找到一个开源项目,比如机器翻译或者深度学习的项目。理解开源项目的任务,编译通过该项目发布的示范程序,得到与项目示范程序一致的结果。然后再深入理解开源项目示范程序的算法。自己编程实现一下这个示范程序的算法。再按照项目提供的标准测试集测试自己实现的程序。如果输出的结果与项目中出现的结果不一致,就要仔细查验自己的程序,反复修改,直到结果与示范程序基本一致。如果还是不行,就大胆给项目的作者写信请教。在此基础上,再看看自己能否进一步完善算法或者实现,取得比示范程序更好的结果。
建议2:如何选择第一个好题目?
工程型研究生,选题很多都是老师给定的。需要采取比较实用的方法,扎扎实实地动手实现。可能不需要多少理论创新,但是需要较强的实现能力和综合创新能力。而学术型研究生需要取得一流的研究成果,因此选题需要有一定的创新。我这里给出如下的几点建议。- 先找到自己喜欢的研究领域。你找到一本最近的ACL会议论文集, 从中找到一个你比较喜欢的领域。在选题的时候,多注意选择蓝海的领域。这是因为蓝海的领域,相对比较新,容易出成果。
- 充分调研这个领域目前的发展状况。包括如下几个方面的调研:方法方面,是否有一套比较清晰的数学体系和机器学习体系;数据方面,有没有一个大家公认的标准训练集和测试集;研究团队,是否有著名团队和人士参加。如果以上几个方面的调研结论不是太清晰,作为初学者可能不要轻易进入。
- 在确认进入一个领域之后,按照建议一所述,需要找到本领域的开源项目或者工具,仔细研究一遍现有的主要流派和方法,先入门。
- 反复阅读本领域最新发表的文章,多阅读本领域牛人发表的文章。在深入了解已有工作的基础上,探讨还有没有一些地方可以推翻、改进、综合、迁移。注意做实验的时候,不要贪多,每次实验只需要验证一个想法。每次实验之后,必须要进行分析存在的错误,找出原因。
- 对成功的实验,进一步探讨如何改进算法。注意实验数据必须是业界公认的数据。
- 与已有的算法进行比较,体会能够得出比较一般性的结论。如果有,则去写一篇文章,否则,应该换一个新的选题。
建议3:如何写出第一篇论文?- 接上一个问题,如果想法不错,且被实验所证明,就可开始写第一篇论文了。
- 确定论文的题目。在定题目的时候,一般不要“…系统”、“…研究与实践”,要避免太长的题目,因为不好体现要点。题目要具体,有深度,突出算法。
- 写论文摘要。要突出本文针对什么重要问题,提出了什么方法,跟已有工作相比,具有什么优势。实验结果表明,达到了什么水准,解决了什么问题。
- 写引言。首先讲出本项工作的背景,这个问题的定义,它具有什么重要性。然后介绍对这个问题,现有的方法是什么,有什么优点。但是(注意但是)现有的方法仍然有很多缺陷或者挑战。比如(注意比如),有什么问题。本文针对这个问题,受什么方法(谁的工作)之启发,提出了什么新的方法并做了如下几个方面的研究。然后对每个方面分门别类加以叙述,最后说明实验的结论。再说本文有几条贡献,一般写三条足矣。然后说说文章的章节组织,以及本文的重点。有的时候东西太多,篇幅有限,只能介绍最重要的部分,不需要面面俱到。
- 相关工作。对相关工作做一个梳理,按照流派划分,对主要的最多三个流派做一个简单介绍。介绍其原理,然后说明其局限性。
- 然后可设立两个章节介绍自己的工作。第一个章节是算法描述。包括问题定义,数学符号,算法描述。文章的主要公式基本都在这里。有时候要给出简明的推导过程。如果借鉴了别人的理论和算法,要给出清晰的引文信息。在此基础上,由于一般是基于机器学习或者深度学习的方法,要介绍你的模型训练方法和解码方法。第二章就是实验环节。一般要给出实验的目的,要检验什么,实验的方法,数据从哪里来,多大规模。最好数据是用公开评测数据,便于别人重复你的工作。然后对每个实验给出所需的技术参数,并报告实验结果。同时为了与已有工作比较,需要引用已有工作的结果,必要的时候需要重现重要的工作并报告结果。用实验数据说话,说明你比人家的方法要好。要对实验结果好好分析你的工作与别人的工作的不同及各自利弊,并说明其原因。对于目前尚不太好的地方,要分析问题之所在,并将其列为未来的工作。
- 结论。对本文的贡献再一次总结。既要从理论、方法上加以总结和提炼,也要说明在实验上的贡献和结论。所做的结论,要让读者感到信服,同时指出未来的研究方向。
- 参考文献。给出所有重要相关工作的论文。记住,漏掉了一篇重要的参考文献(或者牛人的工作),基本上就没有被录取的希望了。
- 写完第一稿,然后就是再改三遍。
- 把文章交给同一个项目组的人士,请他们从算法新颖度、创新性和实验规模和结论方面,以挑剔的眼光,审核你的文章。自己针对薄弱环节,进一步改进,重点加强算法深度和工作创新性。
- 然后请不同项目组的人士审阅。如果他们看不明白,说明文章的可读性不够。你需要修改篇章结构、进行文字润色,增加文章可读性。
- 如投ACL等国际会议,最好再请英文专业或者母语人士提炼文字。
————这里是回答结束的分割线————
感谢大家的阅读。
本帐号为微软亚洲研究院的官方知乎帐号。本帐号立足于计算机领域,特别是人工智能相关的前沿研究,旨在为人工智能的相关研究提供范例,从专业的角度促进公众对人工智能的理解,并为研究人员提供讨论和参与的开放平台,从而共建计算机领域的未来。
微软亚洲研究院的每一位专家都是我们的智囊团,你在这个帐号可以阅读到来自计算机科学领域各个不同方向的专家们的见解。请大家不要吝惜手里的“邀请”,让我们在分享中共同进步。
编辑于 2017-03-06
​赞同 1890​​38 条评论​分享
​收藏​喜欢​
收起​
继续浏览内容

知乎
发现更大的世界
打开

Chrome
继续

量子位
​
2020 新知答主
897 人赞同了该回答
GitHub上出现了一套NLP课程,目前已经获得了2200多颗星。
课程为期13周,从文本嵌入分类开始,讲到Seq2Seq,再到机器翻译、对话系统、对抗学习等等,内容丰富。入门选手可以考虑。
每周的课程,除了课堂视频之外,还有讨论课,大家可以 (用英文) 提问。已经讲完的课程带有视频和Python笔记,另外还有课后作业笔记。
现在,还差第12、13周,就要完结了。 满满的13周 满满的13周
课程大纲如下:第1周:文字嵌入
讲座:介绍文字嵌入、分布式语义、LSA、Word2Vec、GloVe的用法和使用场景。
讨论:单词和句子嵌入。第2周:文本分类
讲座:文本分类。
文本表示的经典方法:BOW,TF-IDF。
神经方法:嵌入,卷积,RNN。
讨论课:卷积神经网络的薪酬预测; 解释网络预测。第3周:语言模型
讲座:语言模型,N-gram和神经方法; 可视化训练的模型。
讨论课:使用语言模型生成ArXiv论文。第4周:Seq2seq/注意力机制
讲座:
Seq2seq:编码器 - 解码器框架。
Attention:Bahdanau模型。
讨论课:酒店和宿舍描述的机器翻译。第5周:结构化学习
讲座:结构化学习 (Structured Learning) ,结构化感知器,结构化预测,RL基础知识。
讨论课:POS标签。第6周:最大期望算法 (EM)
讲座:期望最大化和单词对齐模型。
讨论课:实现期望最大化。第7周:机器翻译
讲座:机器翻译,回顾PBMT的主要思想,过去3年NMT开发的应用程序特定思想以及该领域的一些开放性问题。
讨论课:学生演讲。第8周:迁移学习与多任务学习
讲座:网络学习的内容和原因:“模型”永远不仅仅是“模型”!NLP中的多任务学习,如何理解,模型表示包含哪些信息。
讨论课:通过与其他任务共同学习,提高指定实体的认可度第9周:域适应 (Domain Adaptation)
讲座:一般理论。示例加权 (Instance Weighting) 。代理标签(Proxy-Labels) 方法。特征匹配 (Feature Matching) 方法。类蒸馏 (Distillation-Like) 方法。
讨论:让通用的机翻模型去适应特定的领域。第10周:对话系统
任务导向的对话系统 vs 一般对话系统 (Task-Oriented vs General) 。任务导向系统的框架概述。一般对话:检索与生成是两种方法。针对一般对话的生成模型;针对一般对话的基于检索的模型。
讨论课:基于检索的简单问答。第11周:对抗学习与潜变量
讲座:先复习生成模型。后面讲生成对抗模型 (GAN) ,以及变分自编码器 (VAE) ,以及这些东西为何重要。第12-13周
TBA。等等,等等就会更新的。作者团
这份NLP教程一共有5位作者,其中一作小姐姐Elena Voita是俄罗斯AI公司Yandex的研究员,专供NLP、机器翻译方向,今年还发了一篇关于文本识别和机器翻译的ACL论文。
Elena Voita目前在阿姆斯特丹大学读机器学习、NLP方向的博士,同时还是爱丁堡大学访问博士。传送门
GitHub:
https://github.com/yandexdataschool/nlp_course
Jupyter:
https://mybinder.org/v2/gh/yandexdataschool/nlp_course/master
— 完 —
欢迎大家关注我们的知乎号:量子位
编辑于 2018-12-10
​赞同 897​​18 条评论​分享
​收藏​喜欢​
收起​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

人民邮电出版社
​
已认证的官方帐号
408 人赞同了该回答
非科班出身,自学撸出中文分词库HanLP,在GitHub标星1.5万,成为最受欢迎的自然语言处理项目。他将学习经验总结成书《自然语言处理入门》,帮助小白快速入门NLP。
针对题主的提问,HanLP自然语言处理类库的开发者何晗的经验很值得借鉴。
截至 2019 年 11月初,HanLP项目在 GitHub Star 数达到了 15.6 K,超过了宾夕法尼亚大学的 NLTK、斯坦福大学的 CoreNLP。
贴上GitHub地址:https://github.com/hankcs/HanLP
何晗在开发这款 NLP 工具包时,还是上海外国语大学一名日语专业的大二学生,HanLP项目脱胎他大学时接的一份兼职,何晗也因缘从一个非科班专业的小白逐步成长为NLP领域的专家。如今,正在攻读CS博士的他(研究方向:句法分析、语义分析与问答系统),结合自己的学习历程和HanLP的开发经验创作出版了《自然语言处理入门》一书,得到了周明、刘群、王斌等业内顶级 NLP 专家的推荐。
从着手开发HanLP,到HanLP达到工业使用的水准,何晗对自学NLP有深刻的见解。如果用一句话来总结,那就是:自顶而下,从工程去切入,由应用层往下面的基础层拓展,递归补充理论知识,才能事半功倍。以下入门NLP的建议,皆来自于何晗的经验,分享给像题主这样的初学者,希望能对大家有所启发。一、初学者,请避开自学NLP的常见误区- 有的初学者排斥基础理论——认为学校教的都是没用的,公司里都用不到;
- 有的初学者对基础理论敬而远之——认为理论太高深了,自己基础不好,学了也白学;
- 有的初学者,特别是已经工作的程序员,基本方向正确但学习路径错误,比较容易走极端:
- 在工作很忙的情况下,只是抱着经典书籍苦啃,直到筋疲力尽项目也毫无进展,从而丧失了学习NLP的兴趣;
- 或者,俗称调库小能手,跟风潮流,缺少理论基础,缺乏独立思考能力(比如,认为深度学习最牛,其他的基础理论都是垃圾;认为CNN/RNN/BERT会调参就行了)。
而实际上,自然语言处理是计算机科学、人工智能和语言学学科的交集,这三方面的学科知识都是需要储备的,基础理论的学习必不可少。但很多初学者都是在工作之后才入坑NLP,既难以静下心来啃书啃课,又缺少很好的老师传授知识经验。所以,有效可行的入门方式就是从工程切入,遵循这样的逻辑:延迟加载,只在使用的时候才去加载必要的资料:- 你首先看到的是一个摸得着的实际问题,为了解决该问题才去接触一个具体的方案;
- 为了理解这个方案,才会引入必要的背景知识;
- 为了实现这个方案,才会引入相关细节;
- 为了克服这个方案的问题,才会过渡到新的方案。
二、想快速入门NLP,边学边做疗效好
何晗入门NLP,读过的经典书有:《统计自然语言处理》(宗成庆 著)(对应语言学知识)、《统计学习方法》(李航 著)(对应人工智能知识),《挑战程序设计竞赛》(秋叶拓哉、盐田阳一、北川宜稔 著)(对应计算机算法知识)。
不过,在看经典书籍的过程中,他发现,学习自然语言处理并不需要完全把这几本书看透,最好是可以边看书边做项目。这些书都是非常牛的好书,然而可惜的是,看完书中的章节,不知该如何应用其中的知识点,即使实现了文章中提到的模型,也很难直接将其运用于工程项目。
想必很多初学者都面临类似的学习困惑。为了解决这个问题,何晗动手写了《自然语言处理入门》,目的就是希望学习者看完一章后,便可以将知识点直接用于项目,适合NLP初学者入门并快速布置到生产环境中。成效快,痛苦小,疑问少。
何晗在《自然语言处理入门》一书中,以自己的HanLP开源项目为案例,代码对照公式讲解每一个算法每一个模型,让入门者带着工程思维理解NLP的知识要点,试图在目前市面上艰深晦涩的教科书和简单的入门书之间作出平衡。 
《自然语言处理入门》带领学习者从基本概念入手。逐步介绍中文分词、词性标注、命名实体识别、信息抽取、文本聚类、文本分类、句法分析这几个热门问题的算法原理和工程实现。通过对多种算法的讲解和实现,比较各自的优缺点和适用场景。这些实现并非教学专用,而是生产级别的成熟代码,可以直接用于实际项目。
在理解这些热门问题的算法后,这本书会引导学习者根据自己的项目需求拓展新功能,最终达到理论和实践上的同步入门。
何晗认为,NLP的学习路径,应该尊重一般人的认知规律,而不是学术上的纲目顺序,以此为宗旨来编排图书的内容。因此,面向普通程序员,这本书内容分为以下三大部分: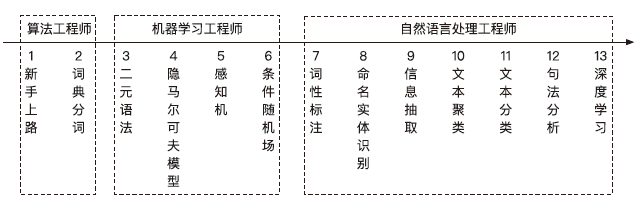
第一部分介绍一些字符串算法,让普通程序员从算法的角度思考中文信息处理。
第二部分由易到难地讲解一些常用的机器学习模型,让算法工程师晋级为机器学习工程师。由中文分词贯穿始终,构成一种探索式的递进学习。这些模型也并非局限于中文分词,会在第三部分应用到更多的自然语言处理问题上去。
第三部分新增了许多与文本处理紧密相关的算法,让机器学习工程师进化到自然语言处理工程师。特别地,最后一章介绍了当前流行的深度学习方法,起到扩展视野、承上启下的作用。学习者可根据自身情况,灵活跳过部分章节。
何晗在自学过程中走过不少弯路,深知数学语言的艰深晦涩,并且痛恨罗列公式故作高深的文章,所以他在书中只保留了必不可少的公式和推导,并且公式与代码相互印证。配套代码由Java和Python双语言写成,与GitHub上最新代码同步更新,所以你只要具备基本的编程经验,就可以跟随书本零起点入门。
自然语言处理入门 Python/Java双代码实现(图灵出品)
京东
¥ 99.00
去购买​
此外,何晗还总结出一份最为详尽的NLP+ML“双生树”思维导图,导图中的关联知识点不仅涵盖NLP领域的核心知识,甚至涉及许多前沿研究和应用,印刷尺寸宽60cm,高74cm,随书附赠供学习者参考。 三、进阶NLP的学习资料和工具推荐 三、进阶NLP的学习资料和工具推荐 - 多读论文,推荐用Google Scholar和Papers检索:
   - 追踪前沿动态,推荐NLP-progress,在各项NLP任务上的排行榜
网址:https://nlpprogress.com/
- 一个中肯的建议:NLP没有通用的解法,算法不够,语料来补
- 算法不是万能的。(想想:一两个百分点对实际业务有多少帮助,又增加了多少成本?)
- 不要完全相信论文。(a. 不要相信不公开源代码的论文; b. 不要相信公开源代码但数据预处理作假的论文; c. 即使能跑出作者宣称的分数,请考虑:模型是否能泛化到你的行业领域? 又增加了多少成本?)
- 语料极其重要。(a. 语料几乎可以把准确率提升到你期望的任何水准,只要数量质量足够; b. 目前通用语料几乎都是新闻,谁能标注出行业语料,谁就是大王; c. 深度学习时代,无标注的纯文本语料也大有用场; d. 软件工程2.0:用数据编程。)
最后,贴出何晗“零基础自学NLP”的线上分享地址:
零基础自学NLP的一些方法-何晗
这个回答的很大篇幅,整理自他的这场分享,感兴趣的知友,可以点击收听:)
自然语言处理入门 Python/Java双代码实现(图灵出品)
京东
¥ 99.00
去购买​
---------
欢迎关注
@人民邮电出版社
知乎号,帮你成长为硬核的技术大拿!
编辑于 2020-09-01
​赞同 408​​30 条评论​分享
​收藏​喜欢​
收起​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

李rumor
公众号「李rumor」,搞AI的朋克女纸,有猫
400 人赞同了该回答
分享一下我的学习路径,正常的理工科大学生大概三四个月可以入门(学过C语言、线性代数、概率论),独立解决NLP问题,搭建baseline并适当优化效果。
下文涉及的脑图/论文list/代码都在(持续更新ing):leerumor/nlp_tutorial​github.com
注:想组队学习的同学可以按文末的方式加入交流群NLP的知识体系
不管是NLP,还是其他领域,在学之前最好先对全局有个大概的印象,知道有哪些重要知识点。比如在学NLP之前,需要有一定的数学&编程基础 -> 掌握基本的统计学习模型 -> 了解深度学习网络原理。而真的去学NLP,只需要掌握五种基本任务(分类/序列标注/文本匹配/文本生成/语言模型),再套到具体的任务里就可以了: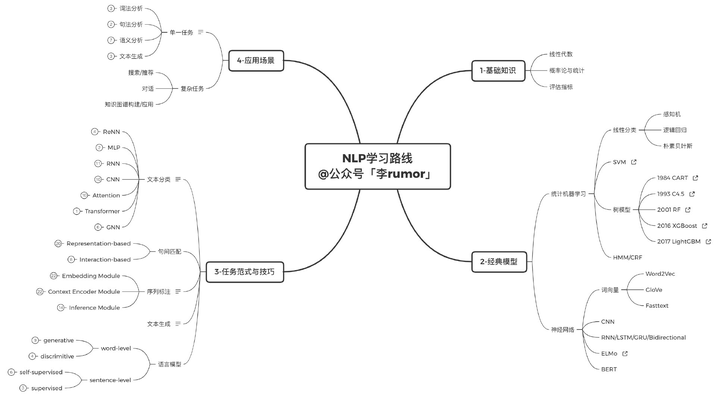
入门阶段建议主要精力放在体系的建立上,否则知识零散不便于记忆。可以按照以下的节奏:- 第一个月:读懂机器学习、深度学习原理,不要求手推公式
- 第二个月:了解经典任务的baseline,动手实践,看懂代码
- 第三个月:深一个应用场景,尝试自己修改模型,提升效果
第一个月:理论基础
数学和编程基础因人而异,之前就很扎实的同学可以花两三天稍微复习一下,或者之后边学机器学习边复习也可以;不扎实的同学最好花一周时间再分别入门一下,会用Python面向对象编程、了解矩阵运算、了解概率论,再根据后续的学习去补漏。
2. 统计机器学习基础(2周)
建议初学者先看懂线性分类、SVM、树模型和图模型,这里推荐李航的「统计学习方法」,看起来看快,大概一天一个知识点。看书不清楚的地方可以参考视频教程,推荐吴恩达的「CS229公开课」或者林田轩的「机器学习基石」。
在看教程时不必强迫症式的一章接着一章刷完,重点看以下部分即可: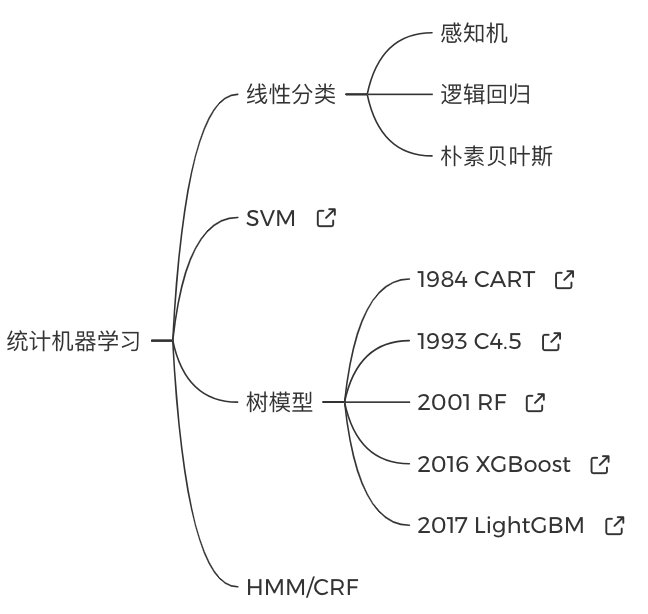
3. 深度学习基础(2周)
深度学习部分稍微轻松些,推荐邱锡鹏的「神经网络与深度学习」教材,或者吴恩达的「深度学习」网课、李宏毅的「深度学习」网课。先学会神经网络的前后向推导,再去了解其他经典编码器: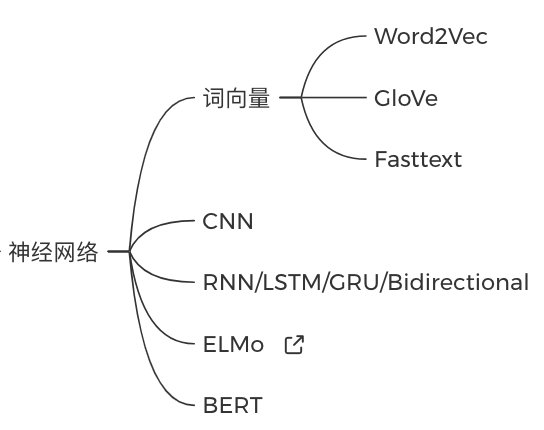 第二个月:经典模型&看懂代码 第二个月:经典模型&看懂代码
掌握基本的理论基础后就可以分任务开始实践了,其实就五类任务,他们还有很多共通的地方。
先掌握:TextCNN -> TextRNN -> 加Attention -> BERT精调 -> GNN(选学)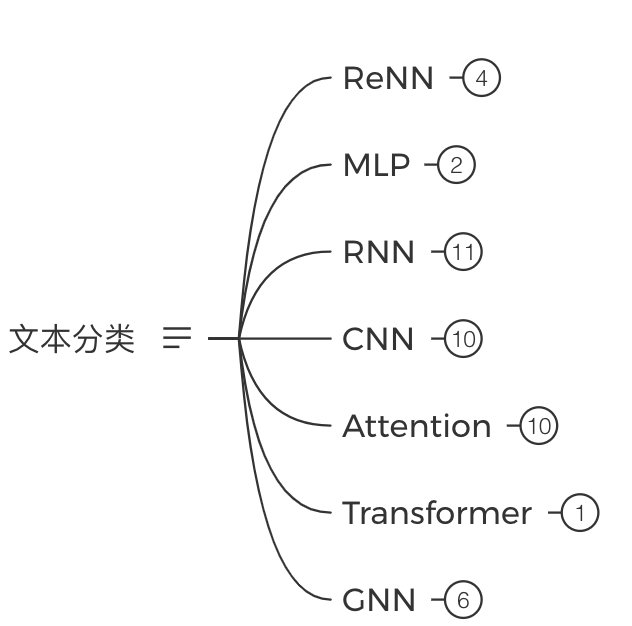
2. 序列标注(1周)
序列标注的baseline是LSTM+CRF,之后可以分别对Embedding、编码器、解码三个模块进行学习: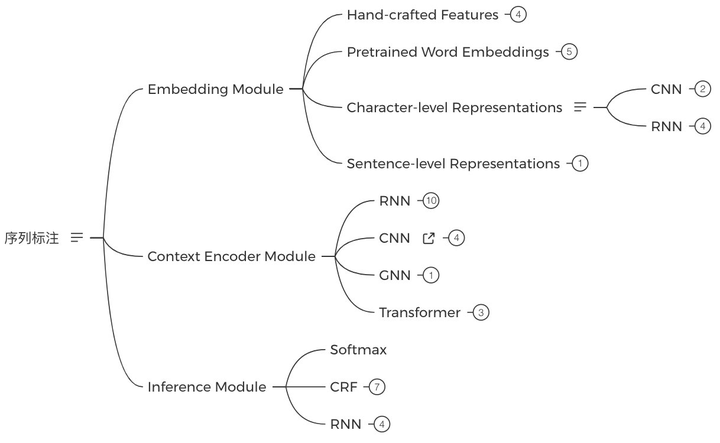
3. 文本匹配(1周)
文本有双塔和匹配两种做法,双塔可以先学SiamCNN,之后了解各种编码器优化方式;基于匹配的方式则在于句子表示间的交互,了解BERT那种TextA+TextB拼接的做法之后,可以再看看阿里的RE2这种轻量级模型的做法: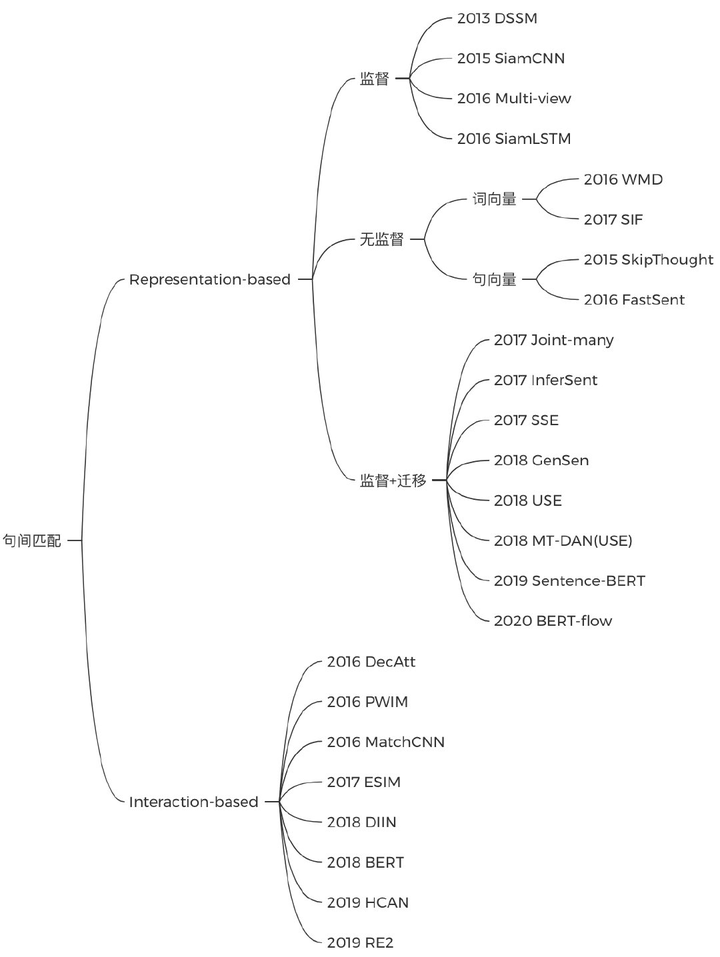
4. 文本生成(1周)
先掌握:Seq2Seq的LSTM实现 -> 加Attention -> Seq2Seq的Transformer实现 -> GPT2 -> T5
再根据兴趣学习VAE、GAN、RL等。
5语言模型(1周)
先掌握:BERT -> XLNet -> ALBERT -> ELECTRA
再了解其他改进: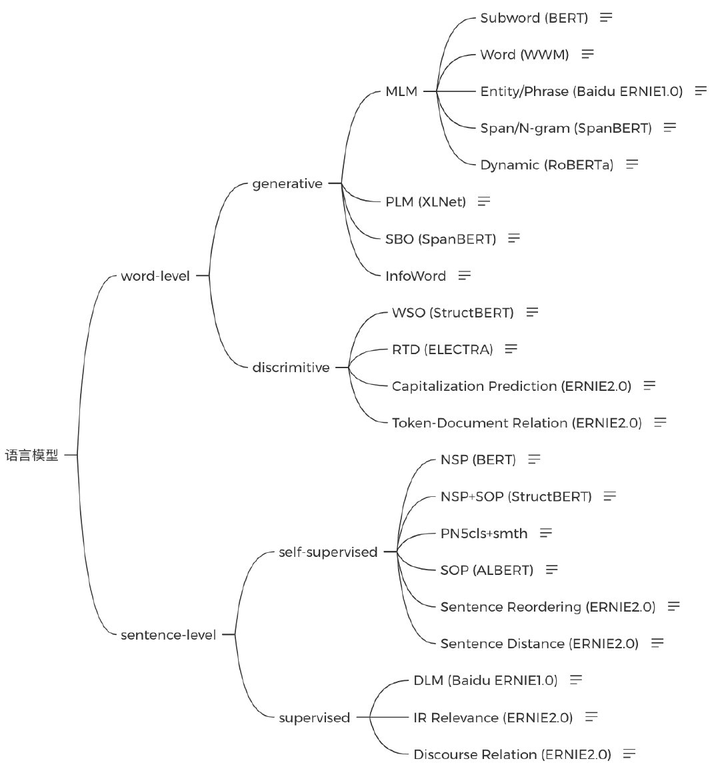
------
这里推荐几篇综述:第三个月:实践&进阶
打一个比赛(3周)
知道各种模型,能看懂原理之后,就要开始实战了。把Github上某个项目跑通并不算“实战”,而是努力去把一个项目做到从0到100,这其中积累的经验才真的有用。
强烈建议打一个比赛,常用的平台有:- Kaggle(国际最知名比赛平台,难度大,但教程丰富,可以学到很多技巧)
- 天池(阿里的竞赛平台,业内认可度高)
- Biendata(近几年知名度也很高的竞赛平台,最好挑知名机构办的比赛)
第一次可以参加已经结束的比赛,先尝试自己打,再去看别人输出的资料和源码,看自己有哪些不足。建议打中文比赛,看数据比较方便,同时可以看看kaggle同类型比赛的kernel,学习trick。同时多看些顶会论文并复现,争取做完一个任务后就把这个任务技巧摸清。
-----
这三个多月结束后,相信坚持下来的同学已经有了不错的水平。接下来就是再继续迭代,深化自己对每个知识点的理解,同时可以:- 认真去打一次比赛,拿到好名次
- 还在读研的话,重点还是在research下功夫,做出自己的成果
- 去找一个实习,边赚钱边学习
其实自己刚开始学的时候只到了minimum的水平,在后续的实践、面试中才逐渐把知识点补全,并归到自己的体系里。刚入门的同学们也不要气馁,先懵懵懂懂地看一看原理,哆哆嗦嗦地跑一跑代码,时间会给你答案。怀疑自己的时候,就算算自己到底学了多久,没到一万小时之前都还来得及。
---
欢迎初入NLP领域的小伙伴们加入rumor建立的「NLP卷王养成群」一起学习,添加微信leerumorrr备注知乎+NLP即可,群里的讨论氛围非常好~推荐阅读:
李rumor:2021年NLP入门书籍推荐|理论&实践​zhuanlan.zhihu.com https://github.com/leerumor/ai-study​github.com https://github.com/leerumor/ai-study​github.com
编辑于 01-17
​赞同 400​​19 条评论​分享
​收藏​喜欢​
收起​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

Geek An
AI/NLP Senior Researcher @ Tencent
152 人赞同了该回答
这是个非常有意思的问题。NLP的领域非常大,想要入门,其实弱水三千,取一瓢饮就可以。
笔者去年画了领域进展图,籍此,我们先来看看NLP领域的格局,如有不足,烦请指正。 2017 NLP领域进展 2017 NLP领域进展
可以看出,包括Subject Classification、Spam Detection、NER等工作已经基本可用,只要堆积足够的数据,就可以达到人类的水准,这些也是最好入门的。
而Summarization、Paraphrase、QA等事情离比较靠谱的通用应用还有一些距离,建议有一定实力再碰。
回过头来,要怎么入门NLP才会比较好?路径其实就几条:- 进入正规院校,拜入一个靠谱的老师门下,老实上课。国内外靠谱的老师很多,但现在的学生也多,竞争非常激烈。这里给出一些介绍靠谱老师的传送门:
- 工作转型,在实际的工作中切入NLP领域,开始深造。这需要你有非常强的学习能力,但也是很现实的一种路径。
- NLP在很多公司是广告、信息流、推荐的核心技术,如果能转到相应的部门,那么收益也绝不会少。
- 如何转是一个问题,最佳的方式是找到一个垂直行业的公司,如NLP+金融,开始做切入。
- 自学成才,这是一个有可能的选项,但并不容易
- 可行路径:这一条路可以通过看网课,学习各类材料,来获得提升,其他答案均已提到具体的方法,这里就不赘述。
- 问题所在:做NLP最核心的点就是要有交流的环境,工业和学术的氛围还是有很大的差别,学术一个月工业十个月,中间这九个月的各类dirty work是不可避免的。有交流环境,才会真正认识到要怎么处理这些真实世界中的事情。
- 而且,很多细节也需要交流才知道重要性,譬如CBOW和Skip-Gram的区别,为什么需要NCE/Sampled-Softmax,以及Negative Sampling的细节等等。要是只会跑个word2vec就是懂NLP了,那业界懂NLP的人就太多了。
2017 高产论文作者附图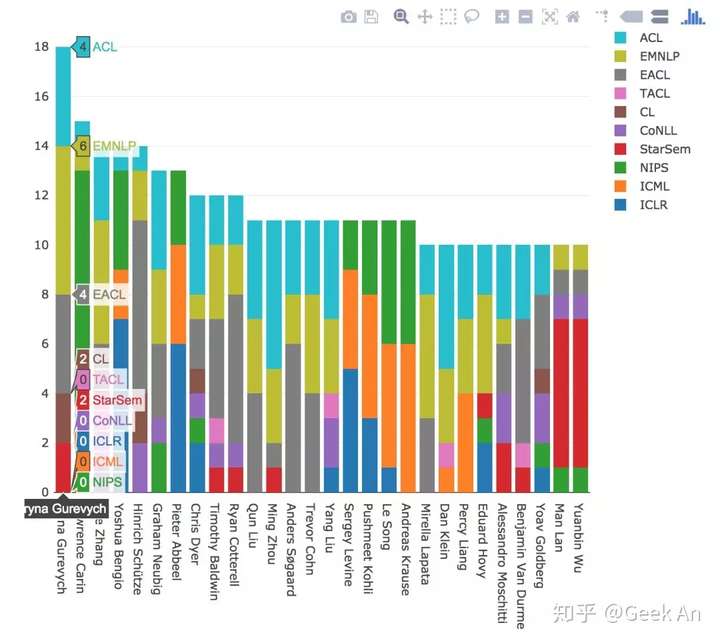 2017年高产论文作者图 2017年高产论文作者图
发布于 2018-05-26
​赞同 152​​24 条评论​分享
​收藏​喜欢​
收起​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

刘训灼
十年饮冰,难凉热血。
680 人赞同了该回答
 我入门NLP大概用了一学期 也就是4个月
首先所有的基础至少得会Python,别说用C或者Java,那样的话你肯定也不是入门阶段
最好有较好的数学基础(微积分 线性代数 概率论),有助于学习理解而不是成为调包侠
不过如果数学基础不好也别灰心,可以边入门边补数学知识,学到哪遇到对应数学知识针对学习
当然这会出现一些问题,但毕竟我回答的是NLP最快入门
不过如果想更长远的发展,有时间我建议系统学习这三门数学课。
个人认为最快学习模式是看书+遇到问题Google,不喜欢一开始看视频,节奏很慢
一开始我也焦头烂额,太多tutorial了,太多技术路线,并且也买了很多书(现在大部分没有看)
一开始花了很多时间在机器学习上,结果其实后面发现大部分没有直接用处ps: 不是说机器学习没有用处,而是现在很多自然语言处理顶层任务都是用DL的东西在做,想更快入门可以先不花太多时间在这上面。
所以我觉得最快的入门路线是 少量机器学习基础+部分深度学习(RNN LSTM Transformer Attention)
Step 0 了解一下自然语言处理的任务自然语言处理其实主要分为两大任务
让 计算机能具备一定理解自然语言的能力,比如:ps: 之前参加的Machine Translation的比赛,挺好玩的,还取得不错成绩~
2. 自然语言生成(NLG):
让计算机有一定创造力,比如:ps: 之前我做过的一个基于TransformerXL的写作文机器人,有趣的项目,效果也很好~
研究对象就是 从 词 到 句 到 文
顶层任务一般为:- 机器翻译
- 文本摘要
- 问答系统
- 对话系统
- 语音识别
- 阅读理解
- 看图说话
Step 1 机器学习+深度学习快速入门
在这里推荐一个复旦大学邱老师的开源书 《神经网络与深度学习》 豆瓣 9.4
nndl/nndl.github.io​github.com
基本上看了这本书,就涵盖了上面我说的 少量机器学习基础 和 深度学习
Step 2 自然语言处理核心技术学习
配合 HanLP作者何老师的《自然语言处理入门》,了解一下自然语言处理的核心技术,基本上路了
当然后续学习这本书肯定不够的,这里有更多相关书籍推荐:
NLPer:机器学习、深度学习、自然语言处理推荐书目​zhuanlan.zhihu.com
Step 3 深度学习框架学习
然后开始动手实践,学习Pytorch,推荐《动手学习深度学习》Pytorch 版https://github.com/ShusenTang/Dive-into-DL-PyTorch​github.com
ps: 在GitHub上动手实现深度学习也有TensorFlow版的
Step 4 实战
学习一些顶层任务的工作流:机器翻译 对话机器人 图说模型....
NLPer:如何实现聊天机器人?ChatBot技术栈​zhuanlan.zhihu.com
比如我写的这个ChatBot Flow,实现一些顶层任务,参加一些比赛 Kaggle 天池之类的
然后可以试着慢慢去阅读一些经典的论文,推荐一个强大的AI的论文网站
NLPer:分享一个实验室用的人工智能论文阅读网站:涵盖AI各方向 经典以及最新的论文​zhuanlan.zhihu.com
养成读paper的习惯,差不多上道了坐在滴滴上码的字,码字不易,别只收藏不点赞哦~
ps:我主要研究自然语言处理,同时也是个全栈玩家,另外爬虫方面也有比较多的经验
正在做聊天机器人相关的研究,对NLP、CS感兴趣的可以关注一下我哦,我们一起进步~
编辑于 2020-06-07
予人玫瑰,手有余香
赞赏
还没有人赞赏,快来当第一个赞赏的人吧!
​赞同 680​​18 条评论​分享
​收藏​喜欢​
收起​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

zibuyu9
​
机器学习等 4 个话题下的优秀答主
圆桌收录
人工智能 · 语言智能
1,209 人赞同了该回答
曾经写过一篇小文,初学者如何查阅自然语言处理(NLP)领域学术资料_zibuyu_新浪博客,也许可以供你参考。
昨天实验室一位刚进组的同学发邮件来问我如何查找学术论文,这让我想起自己刚读研究生时茫然四顾的情形:看着学长们高谈阔论领域动态,却不知如何入门。经过研究生几年的耳濡目染,现在终于能自信地知道去哪儿了解最新科研动态了。我想这可能是初学者们共通的困惑,与其只告诉一个人知道,不如将这些Folk Knowledge写下来,来减少更多人的麻烦吧。当然,这个总结不过是一家之谈,只盼有人能从中获得一点点益处,受个人认知所限,难免挂一漏万,还望大家海涵指正。
1. 国际学术组织、学术会议与学术论文
自然语言处理(natural language processing,NLP)在很大程度上与计算语言学(computational linguistics,CL)重合。与其他计算机学科类似,NLP/CL有一个属于自己的最权威的国际专业学会,叫做The Association for Computational Linguistics(ACL,URL:ACL Home Page),这个协会主办了NLP/CL领域最权威的国际会议,即ACL年会,ACL学会还会在北美和欧洲召开分年会,分别称为NAACL和EACL。除此之外,ACL学会下设多个特殊兴趣小组(special interest groups,SIGs),聚集了NLP/CL不同子领域的学者,性质类似一个大学校园的兴趣社团。其中比较有名的诸如SIGDAT(Linguistic data and corpus-based approaches to NLP)、SIGNLL(Natural Language Learning)等。这些SIGs也会召开一些国际学术会议,其中比较有名的就是SIGDAT组织的EMNLP(Conference on Empirical Methods on Natural Language Processing)和SIGNLL组织的CoNLL(Conference on Natural Language Learning)。此外还有一个International Committee on Computational Linguistics的老牌NLP/CL学术组织,它每两年组织一个称为International Conference on Computational Linguistics (COLING)的国际会议,也是NLP/CL的重要学术会议。NLP/CL的主要学术论文就分布在这些会议上。
作为NLP/CL领域的学者最大的幸福在于,ACL学会网站建立了称作ACL Anthology的页面(URL:ACL Anthology),支持该领域绝大部分国际学术会议论文的免费下载,甚至包含了其他组织主办的学术会议,例如COLING、IJCNLP等,并支持基于Google的全文检索功能,可谓一站在手,NLP论文我有。由于这个论文集合非常庞大,并且可以开放获取,很多学者也基于它开展研究,提供了更丰富的检索支持,具体入口可以参考ACL Anthology页面上方搜索框右侧的不同检索按钮。
与大部分计算机学科类似,由于技术发展迅速,NLP/CL领域更重视发表学术会议论文,原因是发表周期短,并可以通过会议进行交流。当然NLP/CL也有自己的旗舰学术期刊,发表过很多经典学术论文,那就是Computational Linguistics(URL:MIT Press Journals)。该期刊每期只有几篇文章,平均质量高于会议论文,时间允许的话值得及时追踪。此外,ACL学会为了提高学术影响力,也刚刚创办了Transactions of ACL(TACL,URL:Transactions of the Association for Computational Linguistics (ISSN: 2307-387X)),值得关注。值得一提的是这两份期刊也都是开放获取的。此外也有一些与NLP/CL有关的期刊,如ACM Transactions on Speech and Language Processing,ACM Transactions on Asian Language Information Processing,Journal of Quantitative Linguistics等等。
根据Google Scholar Metrics 2013年对NLP/CL学术期刊和会议的评价,ACL、EMNLP、NAACL、COLING、LREC、Computational Linguistics位于前5位,基本反映了本领域学者的关注程度。
NLP/CL作为交叉学科,其相关领域也值得关注。主要包括以下几个方面:(1)信息检索和数据挖掘领域。相关学术会议主要由美国计算机学会(ACM)主办,包括SIGIR、WWW、WSDM等;(2)人工智能领域。相关学术会议主要包括AAAI和IJCAI等,相关学术期刊主要包括Artificial Intelligence和Journal of AI Research;(3)机器学习领域,相关学术会议主要包括ICML,NIPS,AISTATS,UAI等,相关学术期刊主要包括Journal of Machine Learning Research(JMLR)和Machine Learning(ML)等。例如最近兴起的knowledge graph研究论文,就有相当一部分发表在人工智能和信息检索领域的会议和期刊上。实际上国内计算机学会(CCF)制定了“中国计算机学会推荐国际学术会议和期刊目录”(CCF推荐排名),通过这个列表,可以迅速了解每个领域的主要期刊与学术会议。
最后,值得一提的是,美国Hal Daumé III维护了一个natural language processing的博客(natural language processing blog),经常评论最新学术动态,值得关注。我经常看他关于ACL、NAACL等学术会议的参会感想和对论文的点评,很有启发。另外,ACL学会维护了一个Wiki页面(ACL Wiki),包含了大量NLP/CL的相关信息,如著名研究机构、历届会议录用率,等等,都是居家必备之良品,值得深挖。
2. 国内学术组织、学术会议与学术论文
与国际上相似,国内也有一个与NLP/CL相关的学会,叫做中国中文信息学会(URL:中国中文信息学会)。通过学会的理事名单(中国中文信息学会)基本可以了解国内从事NLP/CL的主要单位和学者。学会每年组织很多学术会议,例如全国计算语言学学术会议(CCL)、全国青年计算语言学研讨会(YCCL)、全国信息检索学术会议(CCIR)、全国机器翻译研讨会(CWMT),等等,是国内NLP/CL学者进行学术交流的重要平台。尤其值得一提的是,全国青年计算语言学研讨会是专门面向国内NLP/CL研究生的学术会议,从组织到审稿都由该领域研究生担任,非常有特色,也是NLP/CL同学们学术交流、快速成长的好去处。值得一提的是,2010年在北京召开的COLING以及2015年即将在北京召开的ACL,学会都是主要承办者,这也一定程度上反映了学会在国内NLP/CL领域的重要地位。此外,计算机学会中文信息技术专委会组织的自然语言处理与中文计算会议(NLP&CC)也是最近崛起的重要学术会议。中文信息学会主编了一份历史悠久的《中文信息学报》,是国内该领域的重要学术期刊,发表过很多篇重量级论文。此外,国内著名的《计算机学报》、《软件学报》等期刊上也经常有NLP/CL论文发表,值得关注。
过去几年,在水木社区BBS上开设的AI、NLP版面曾经是国内NLP/CL领域在线交流讨论的重要平台。这几年随着社会媒体的发展,越来越多学者转战新浪微博,有浓厚的交流氛围。如何找到这些学者呢,一个简单的方法就是在新浪微博搜索的“找人”功能中检索“自然语言处理”、 “计算语言学”、“信息检索”、“机器学习”等字样,马上就能跟过去只在论文中看到名字的老师同学们近距离交流了。还有一种办法,清华大学梁斌开发的“微博寻人”系统(清华大学信息检索组)可以检索每个领域的有影响力人士,因此也可以用来寻找NLP/CL领域的重要学者。值得一提的是,很多在国外任教的老师和求学的同学也活跃在新浪微博上,例如王威廉(Sina Visitor System)、李沐(Sina Visitor System)等,经常爆料业内新闻,值得关注。还有,国内NLP/CL的著名博客是52nlp(我爱自然语言处理),影响力比较大。总之,学术研究既需要苦练内功,也需要与人交流。所谓言者无意、听者有心,也许其他人的一句话就能点醒你苦思良久的问题。无疑,博客微博等提供了很好的交流平台,当然也注意不要沉迷哦。
3. 如何快速了解某个领域研究进展
最后简单说一下快速了解某领域研究进展的经验。你会发现,搜索引擎是查阅文献的重要工具,尤其是谷歌提供的Google Scholar,由于其庞大的索引量,将是我们披荆斩棘的利器。
当需要了解某个领域,如果能找到一篇该领域的最新研究综述,就省劲多了。最方便的方法还是在Google Scholar中搜索“领域名称 + survey / review / tutorial / 综述”来查找。也有一些出版社专门出版各领域的综述文章,例如NOW Publisher出版的Foundations and Trends系列,Morgan & Claypool Publisher出版的Synthesis Lectures on Human Language Technologies系列等。它们发表了很多热门方向的综述,如文档摘要、情感分析和意见挖掘、学习排序、语言模型等。
如果方向太新还没有相关综述,一般还可以查找该方向发表的最新论文,阅读它们的“相关工作”章节,顺着列出的参考文献,就基本能够了解相关研究脉络了。当然,还有很多其他办法,例如去http://videolectures.net
上看著名学者在各大学术会议或暑期学校上做的tutorial报告,去直接咨询这个领域的研究者,等等。
编辑于 2015-07-16
​赞同 1209​​33 条评论​分享
​收藏​喜欢​
收起​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

李文哲
​
机器学习话题下的优秀答主
81 人赞同了该回答
怎么快速入门 == 寻找学习的最短路径
A. 怎么寻找学习最短路径?- A.1 找到高质量的内容
- A.2 避免什么都学(this is worst!)
A.1 怎么找到高质量的内容?- 靠前人的经验 (最好有一个有经验的人带你)
- 搜索能力 (这点很重要,学习能力强的人都具备很强的搜索能力)
- 独立思考能力 (只有独立思考能力,才能辨别内容的质量)
A.2 避免什么都学,怎么做到?- 不要以BFS(breadth-first search)方式来学习 (如果你理解什么是BFS,应该懂什么意思)
- 建议以DFS(depth-first search)方式来学习 (有个明确的目标,不断地深入知识)
总之,我不太喜欢列出一个非常丰富的大纲,资料列表(就像这里很多回复一样)。犹如成功的重要因素是选择,快速入门的法宝也是选择。
如果你想快速入门,千万别按照完整的大纲来学,you will get lost!
那最后,我的一个具体的建议是,用2-3个月来搭建一个聊天机器人吧,这绝对能够让你入门。而且要知道聊天机器人系统本身涉及到了各种各样NLP的技术。如还有疑问,可以关注我/私信我。
编辑于 2018-11-07
​赞同 81​​8 条评论​分享
​收藏​喜欢​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

Dr.Wu
​
机器学习话题下的优秀答主
编辑推荐
2,629 人赞同了该回答
一定一定要掌握python,其中的一些库 nltk,spacy,尤其是spacy他的速度要远好于我之前用的所有工具。包括迈入deep learning之后的pytorch等等库,都是依赖python的,所以学习python是必不可少的。
推荐《数学之美》,这个书写得特别科普且生动形象,我相信你不会觉得枯燥。这个我极力推荐,我相信科研的真正原因是因为兴趣,而不是因为功利的一些东西。
接下来说,《统计自然语言处理基础》这本书,这书实在是太老了,但是也很经典,看不看随意了。
现在自然语言处理都要靠统计学知识,所以我十分十分推荐《统计学习方法》,李航的。李航老师用自己课余时间7年写的,而且有博士生Review的。自然语言处理和机器学习不同,机器学习依靠的更多是严谨的数学知识以及推倒,去创造一个又一个机器学习算法。而自然语言处理是把那些机器学习大牛们创造出来的东西当Tool使用。所以入门也只是需要涉猎而已,把每个模型原理看看,不一定细致到推倒。
统计学习方法(第2版)李航
京东
¥ 88.20
去购买​

数学之美
京东
¥ 33.97
去购买​
宗成庆老师 的统计自然语言处理第二版非常好~《中文信息处理丛书:统计自然语言处理(第2版)》 蓝色皮的~~~
然后就是Stanford公开课了,Stanford公开课要求一定的英语水平。| Coursera 我觉得讲的比大量的中国老师好~
举例:
http://www.ark.cs.cmu.edu/LS2/in...
或者
http://www.stanford.edu/class/cs...
如果做工程前先搜索有没有已经做好的工具,不要自己从头来。做学术前也要好好的Survey!
开始推荐工具包:
中文的显然是哈工大开源的那个工具包 LTP (Language Technology Platform) developed by HIT-SCIR(哈尔滨工业大学社会计算与信息检索研究中心).
英文的(python):- pattern - simpler to get started than NLTK
- chardet - character encoding detection
- pyenchant - easy access to dictionaries
- scikit-learn - has support for text classification
- unidecode - because ascii is much easier to deal with
希望可以掌握以下的几个tool:
CRF++
GIZA
Word2Vec
还记得小时候看过的数码宝贝,每个萌萌哒的数码宝贝都会因为主人身上发生的一些事情而获得进化能力,其实在自然语言处理领域我觉得一切也是这样~ 我简单的按照自己的见解总结了每个阶段的特征,以及提高的解决方案
1.幼年体——自然语言处理好屌,我什么都不会但是好想提高
建议。。。去看公开课~去做Kaggle的那个情感分析题。
2.成长期——觉得简单模型太Naive,高大上的才是最好的
这个阶段需要自己动手实现一些高级算法,或者说常用算法,比如LDA,比如SVM,比如逻辑斯蒂回归。并且拥抱Kaggle,知道trick在这个领域的重要性。在预训练模型和Transformer模型有了以后,一定要精通这两个模型,精通到什么程度呢,Bert Base的参数量是怎么得到的要能脱口而出。
3.成熟期——高大上的都不work,通过特征工程加规则才work
大部分人应该都在这个级别吧,包括我自己,我总是想进化,但积累还是不够。觉得高大上的模型都是一些人为了paper写的,真正的土方法才是重剑无锋,大巧不工。在这个阶段,应该就是不断读论文,不断看各种模型变种吧,什么句子相似度计算word2vec cosine已经不再适合你了。
4.完全体——在公开数据集上,把某个高大上的模型做work了~
这类应该只有少数博士可以做到吧,我已经不知道到了这个水平再怎么提高了~是不是只能说不忘初心,方得始终。
5.究极体——参见Micheal Jordan Andrew Ng.
好好锻炼身体,保持更长久的究极体形态
希望可以理解自然语言处理的基本架构~:分词=>词性标注=> arser arser
Quora上推荐的NLP的论文(摘自Quora 我过一阵会翻译括号里面的解释):
Parsing(句法结构分析~语言学知识多,会比较枯燥)- Klein & Manning: "Accurate Unlexicalized Parsing" ( )
- Klein & Manning: "Corpus-Based Induction of Syntactic Structure: Models of Dependency and Constituency" (革命性的用非监督学习的方法做了parser)
- Nivre "Deterministic Dependency Parsing of English Text" (shows that deterministic parsing actually works quite well)
- McDonald et al. "Non-Projective Dependency Parsing using Spanning-Tree Algorithms" (the other main method of dependency parsing, MST parsing)
Machine Translation(机器翻译,如果不做机器翻译就可以跳过了,不过翻译模型在其他领域也有应用)- Knight "A statistical MT tutorial workbook" (easy to understand, use instead of the original Brown paper)
- Och "The Alignment-Template Approach to Statistical Machine Translation" (foundations of phrase based systems)
- Wu "Inversion Transduction Grammars and the Bilingual Parsing of Parallel Corpora" (arguably the first realistic method for biparsing, which is used in many systems)
- Chiang "Hierarchical Phrase-Based Translation" (significantly improves accuracy by allowing for gappy phrases)
Language Modeling (语言模型)- Goodman "A bit of progress in language modeling" (describes just about everything related to n-gram language models 这是一个survey,这个survey写了几乎所有和n-gram有关的东西,包括平滑 聚类)
- Teh "A Bayesian interpretation of Interpolated Kneser-Ney" (shows how to get state-of-the art accuracy in a Bayesian framework, opening the path for other applications)
Machine Learning for NLP- Sutton & McCallum "An introduction to conditional random fields for relational learning" (CRF实在是在NLP中太好用了!!!!!而且我们大家都知道有很多现成的tool实现这个,而这个就是一个很简单的论文讲述CRF的,不过其实还是蛮数学= =。。。)
- Knight "Bayesian Inference with Tears" (explains the general idea of bayesian techniques quite well)
- Berg-Kirkpatrick et al. "ainless Unsupervised Learning with Features" (this is from this year and thus a bit of a gamble, but this has the potential to bring the power of discriminative methods to unsupervised learning)
Information Extraction- Hearst. Automatic Acquisition of Hyponyms from Large Text Corpora. COLING 1992. (The very first paper for all the bootstrapping methods for NLP. It is a hypothetical work in a sense that it doesn't give experimental results, but it influenced it's followers a lot.)
- Collins and Singer. Unsupervised Models for Named Entity Classification. EMNLP 1999. (It applies several variants of co-training like IE methods to NER task and gives the motivation why they did so. Students can learn the logic from this work for writing a good research paper in NLP.)
Computational Semantics- Gildea and Jurafsky. Automatic Labeling of Semantic Roles. Computational Linguistics 2002. (It opened up the trends in NLP for semantic role labeling, followed by several CoNLL shared tasks dedicated for SRL. It shows how linguistics and engineering can collaborate with each other. It has a shorter version in ACL 2000.)
- Pantel and Lin. Discovering Word Senses from Text. KDD 2002. (Supervised WSD has been explored a lot in the early 00's thanks to the senseval workshop, but a few system actually benefits from WSD because manually crafted sense mappings are hard to obtain. These days we see a lot of evidence that unsupervised clustering improves NLP tasks such as NER, parsing, SRL, etc,
其实我相信,大家更感兴趣的是上层的一些应用~而不是如何实现分词,如何实现命名实体识别等等。而且应该大家更对信息检索感兴趣。不过自然语言处理和信息检索还是有所区别的,So~~~我就不在这边写啦
编辑于 2020-07-22
​赞同 2629​​39 条评论​分享
​收藏​喜欢​
收起​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

机器之心
​
数学话题下的优秀答主
205 人赞同了该回答
这里有一份用深度学习做自然语言处理的最佳实践清单,希望对你有所帮助。
对于如何使用深度学习进行自然语言处理,本文作者 Sebastian Ruder 给出了一份详细的最佳实践清单,不仅包括与大多数 NLP 任务相关的最佳实践,还有最常见任务的最佳实践,尤其是分类、序列标注、自然语言生成和神经机器翻译。作者对最佳实践的选择很严格,只有被证明在至少两个独立的群体中有益的实践才会入选,并且每个最佳实践作者至少给出两个参引。作者承认这份清单并不全面,比如其不熟悉的解析、信息提取等就没有涉及。机器之心对该文进行了编译,原文链接在此,点击即可跳转。 简介
本文是一系列关于如何使用神经网络进行自然语言处理(NLP)的最佳实践汇集,将随着新观点的出现定期进行更新,从而不断提升我们对用于 NLP 的深度学习的理解。
NLP 社区中有这样一句说法:带有注意力的 LSTM 能在所有任务上实现当前最佳的表现。尽管在过去的两年这确实是真的,NLP 社区却在慢慢偏离带有注意力的 LSTM,而去发现更有趣的模型。
但是,NLP 社区并非想再花费两年独立地(重新)发现下一个带有注意力的 LSTM。我们不打算重新发明已经奏效的技巧或方法。尽管现存的深度学习库已经从整体上编码了神经网络的最佳实践,比如初始化方案,但是很多其他的细节,尤其是特定任务或特定领域还有待从业者解决。
本文并不打算盘点当前最佳,而是收集与大量任务相关的最佳实践。换言之,本文并不描述某个特定架构,而是旨在收集那些构建成功框架的特征。其中的很多特征对于推动当前最佳是最有用的,因此我希望对于它们的更广泛了解将会带来更强的评估、更有意义的基线对比,以及更多灵感,帮助我们觉察那些可能奏效的方法。
本文假设你对神经网络应用于 NLP 的情况已经很熟悉(如果不熟悉,我建议你看一下 Yoav Goldberg 写的A Primer on Neural Network Modelsfor Natural Language Processing),并大体上对 NLP 或某个特定任务感兴趣。本文的主要目标是使你快速掌握相关的最佳实践,从而尽快做出有意义的贡献。我首先会对与绝大多数任务相关的最佳实践做一个概述,接着略述与最常见的任务相关的最佳实践,尤其是分类、序列标注、自然语言生成和神经机器翻译。
免责声明:把某些东西定义为最佳实践极其困难:最佳的标准是什么?如果有更好的实践出现呢?本文基于我的个人理解和经验(肯定不全面)。接下来,我将只讨论被证明在至少两个独立的群体中有益的实践。对于每个最佳实践我将给出至少两个参引。
最佳实践
词嵌入
在最近的 NLP 发展中,词嵌入无疑是最广为人知的最佳实践,这是因为预训练嵌入的使用对我们十分有帮助 (Kim, 2014) [12]。词嵌入的最佳维度绝大多数是依赖任务的:一个更小的维度更多在句法任务上工作更好,比如命名实体识别(named entity recognition)(Melamud et al., 2016) [44],或者词性标注(POS)(Plank et al., 2016) [32],尽管一个更大的维度对于更多的语义任务来说更有用,比如情感分析 (Ruder et al., 2016) [45]。
深度
虽然短时间内我们还无法达到计算机视觉的深度,但是 NLP 中的神经网络已经发展地更深了。现在最佳的方法通常使用 deep Bi-LSTM,它通常包含 3-4 层,比如词性标注 (Plank et al., 2016) 和语义角色标注 (He et al., 2017) [33]。一些任务的模型甚至更深。谷歌的 NMT 模型有 8 个编码器和 8 个解码器层,(Wu et al., 2016) [20]。然而,大多数情况下,模型超过 2 层所带来的性能提升是最小的 (Reimers & Gurevych, 2017) [46]。
这些观察适用于绝大多数序列标注和结构化预测问题。对于分类,深或者非常深的模型只在字符级的输入中表现良好,并且浅层的字词级模型依然是当前最佳 (Zhang et al., 2015; Conneau et al., 2016; Le et al., 2017) [28, 29, 30]。
层连接
训练深度神经网络时,可以使用一些核心技巧避免梯度消失问题。不同的层和连接因此被提出来了,这里我们将讨论 3 点:i) Highway 层,ii) 残差连接(residual connection),iii) 密集型残差连接。
Highway 层:它受到 LSTM 的门控机制所启发 (Srivastava et al., 2015) [1]。首先让我们假设一个单层的 MLP,它将一个非线性 g 的仿射变换应用到其输入 x: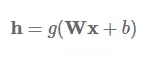
Highway 层接着计算以下函数: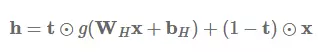
其中 t=σ(WTx+bT) 被称作变换门(transform gate),(1−t) 被称作进位门(carry gate)。我们可以看到,Highway 层和 LSTM 门很相似,因为它们自适应地把输入的一些维度直接传递到输出。
Highway 层主要用于语言建模,并取得了当前最佳的结果 (Kim et al., 2016; Jozefowicz et al., 2016; Zilly et al., 2017) [2, 3, 4],但它同时也用于其他任务,如语音识别 (Zhang et al., 2016) [5]。想了解更多相关信息和代码,可查看 Sristava 的主页(http://people.idsia.ch/~rupesh/very_deep_learning/
)。
残差连接:残差连接(He et al., 2016)[6] 的首次提出是应用于计算机视觉,也是计算机视觉在 ImageNet 2016 夺冠的最大助力。残差连接甚至比 Highway 层更直接。我们使用代表当前层的指数 L 来增加之前的层输出 h。然后,残差连接学习以下函数: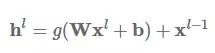
仅通过一个快捷连接,残差连接即可把之前层的输入添加到当前层。这一简单的更改缓解了梯度消失问题,因为层级不能变得更好,模型可以默认使用恒等函数(identity function)。
密集型残差连接:密集型残差连接 (Huang et al., 2017) [7] ( CVPR 2017 最佳论文奖)从每一个层向所有随后的层添加连接,而不是从每一个层向下一个层添加层: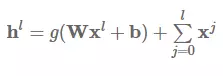
密集型残差连接已成功应用于计算机视觉,也被证明在神经机器翻译方面的表现持续优于残差连接 (Britz et al., 2017) [27]。
Dropout
尽管在计算机视觉领域的多数应用中,批归一化已使其他正则化器变得过时,但是 dropout (Srivasta et al., 2014) [8] 依然是应用于 NLP 深度神经网络中的正则化器。0.5 的 dropout 率表明其在绝大多数场景中依然高效 (Kim, 2014)。近年来,dropout 的变体比如适应性 dropout(Ba & Frey, 2013) [9]和进化 dropout (Li et al., 2016) [10] 已被提出,但没有一个在 NLP 社区中获得广泛应用。造成这一问题的主要原因是它无法用于循环连接,因为聚集 dropout masks 会将嵌入清零。
循环 dropout:循环 dropout(Gal & Ghahramani, 2016)[11] 通过在层 ll 的时间步中应用相同的 dropout masks 来解决这一问题。这避免了放大序列中的 dropout 噪音,并为序列模型带来了有效的正则化。循环 dropout 已在语义角色标注 (He et al., 2017) 和语言建模 (Melis et al., 2017) [34] 中取得了当前最佳的结果。
多任务学习
如果有额外的数据,多任务学习(MTL)通常可用于在目标任务中提升性能。
辅助目标(auxiliary objective):我们通常能找到对我们所关心的任务有用的辅助目标 (Ruder, 2017) [13]。当我们已经预测了周围词以预训练词嵌入 (Mikolov et al., 2013) 时,我们还可以在训练中将其作为辅助目标 (Rei, 2017) [35]。我们也经常在序列到序列模型中使用相似的目标(Ramachandran et al., 2016)[36]。
特定任务层:尽管把 MTL 用于 NLP 的标准方法是硬参数共享,但允许模型学习特定任务层很有意义。这可通过把一项任务的输出层放置在较低级别来完成 (Søgaard & Goldberg, 2016) [47]。另一方法是诱导私有和共享的子空间 (Liu et al., 2017; Ruder et al., 2017) [48, 49]。
注意力机制
注意力机制是在序列到序列模型中用于注意编码器状态的最常用方法,它同时还可用于回顾序列模型的过去状态。使用注意力机制,系统能基于隐藏状态 s_1,...,s_m 而获得环境向量(context vector)c_i,这些环境向量可以和当前的隐藏状态 h_i 一起实现预测。环境向量 c_i 可以由前面状态的加权平均数得出,其中状态所加的权就是注意力权重 a_i: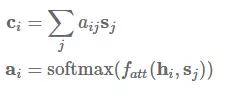
注意力函数 f_att(h_i,s_j) 计算的是目前的隐藏状态 h_i 和前面的隐藏状态 s_j 之间的非归一化分配值。在下文中,我们将讨论四种注意力变体:加性注意力(additive attention)、乘法(点积)注意力(multiplicative attention)、自注意力(self-attention)和关键值注意力(key-value attention)。
加性注意力是最经典的注意力机制 (Bahdanau et al., 2015) [15],它使用了有一个隐藏层的前馈网络来计算注意力的分配: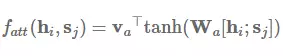
其中 v_a 和 W_a 是所学到的注意力参数,[* ; *] 代表了级联。类似地,我们同样能使用矩阵 W_1 和 W_2 分别为 h_i 和 s_j 学习单独的转换,这一过程可以表示为: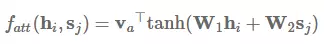
乘法注意力(Multiplicative attention)(Luong et al., 2015) [16] 通过计算以下函数而简化了注意力操作: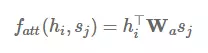
加性注意力和乘法注意力在复杂度上是相似的,但是乘法注意力在实践中往往要更快速、具有更高效的存储,因为它可以使用矩阵操作更高效地实现。两个变体在低维度 d_h 解码器状态中性能相似,但加性注意力机制在更高的维度上性能更优。缓解这一现象的方法是将 f_att(h_i,s_j) 缩放到 d_h^(-1/2) 倍 (Vaswani et al., 2017) [17]。
注意力机制不仅能用来处理编码器或前面的隐藏层,它同样还能用来获得其他特征的分布,例如阅读理解任务中作为文本的词嵌入 (Kadlec et al., 2017) [37]。然而,注意力机制并不直接适用于分类任务,因为这些任务并不需要情感分析(sentiment analysis)等额外的信息。在这些模型中,通常我们使用 LSTM 的最终隐藏状态或像最大池化和平均池化那样的聚合函数来表征句子。
自注意力机制(Self-attention)通常也不会使用其他额外的信息,但是它能使用自注意力关注本身进而从句子中抽取相关信息 (Lin et al., 2017) [18]。自注意力又称作内部注意力,它在很多任务上都有十分出色的表现,比如阅读理解 (Cheng et al., 2016) [38]、文本继承 (textual entailment/Parikh et al., 2016) [39]、自动文本摘要 (Paulus et al., 2017) [40]。
我们能计算每个隐藏状态 h_i 的非归一化分配值从而简化加性注意力: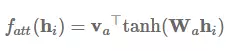
在矩阵形式中,对于隐藏状态 H=h_1,…,h_n,我们能通过以下形式计算注意力向量 a 和最后的句子表征 c: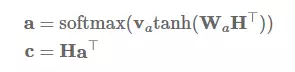
我们不仅可以抽取一个向量,同时还能通过将 v_a 替代为 V_a 矩阵而执行一些其他注意力特征,这可以令我们抽取注意力矩阵 A: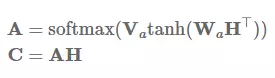
在实践中,我们可以执行以下的正交约束而惩罚计算冗余,并以 Frobenius 范数平方的形式鼓励注意力向量的多样性: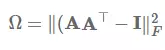
Vaswani et al. (2017) 同样使用了类似的多头注意力(multi-head attention)。
最后,关键值注意力 (Daniluk et al., 2017) [19] 是最近出现的注意力变体机制,它将形式和函数分开,从而为注意力计算保持分离的向量。它同样在多种文本建模任务 (Liu & Lapata, 2017) [41] 中发挥了很大的作用。具体来说,关键值注意力将每一个隐藏向量 h_i 分离为一个键值 k_i 和一个向量 v_i:[k_i;v_i]=h_i。键值使用加性注意力来计算注意力分布 a_i: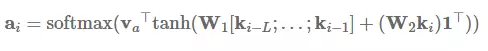
其中 L 为注意力窗体的长度,I 为所有单元为 1 的向量。然后使用注意力分布值可以求得环境表征 c_i: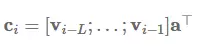
其中环境向量 c_i 将联合现阶段的状态值 v_i 进行预测。
最优化
最优化算法和方案通常是模型的一部分,并且常常被视为黑箱操作。有时算法轻微的变化,如在 Adam 算法中减少超参数β2 的值 (Dozat & Manning, 2017) [50] 将会造成优化行为的巨大改变。
Adam 方法 (Kingma & Ba, 2015) [21] 是使用最广泛、最常见的优化算法,它通常也作为 NLP 研究员的优化器。Adam 方法要明显地比 vanilla 随机梯度下降更优秀,并且其收敛速度也十分迅速。但近来有研究表明通过精调并带动量的梯度下降方法要比 Adam 方法更优秀 (Zhang et al., 2017) [42]。
从优化方案来说,因为 Adam 方法会适应性地为每一个参数调整学习速率 (Ruder, 2016) [22],所以我们可以使用 Adam 方法精确地执行 SGD 风格的退火处理。特别是我们可以通过重启(restart)执行学习速率退火处理:即设定一个学习速率并训练模型,直到模型收敛。然后,我们可以平分学习速率,并通过加载前面最好的模型而重启优化过程。在 Adam 中,这会令优化器忘记预训练参数的学习速率,并且重新开始。Denkowski & Neubig (2017) [23] 表示带有两个重启和学习速率退火处理的 Adam 算法要比带有退火处理的 SGD 算法更加优秀。
集成方法
通过平均多个模型的预测将多个模型组合为一个集成模型被证明是提高模型性能的有效策略。尽管在测试时使用集成做预测十分昂贵,最近提取方面的一些进展允许我们把昂贵的集成压缩成更小的模型 (Hinton et al., 2015; Kuncoro et al., 2016; Kim & Rush, 2016) [24, 25, 26]。
如果评估模型的多样性增加 (Denkowski & Neubig, 2017),集成是确保结果可靠的重要方式。尽管集成一个模型的不同检查点被证明很有效 (Jean et al., 2015; Sennrich et al., 2016) [51, 52],但这种方法牺牲了模型的多样性。周期学习率有助于缓解这一影响 (Huang et al., 2017) [53]。但是,如果资源可用,我们更喜欢集成多个独立训练的模型以最大化模型多样性。
超参数优化
我们可以简单地调整模型超参数从而在基线上获得显著提升,而不仅仅只是使用预定义或现有的超参数来训练模型。最近 Bayesian Optimization 的新进展可以用于在神经网络黑箱训练中优化超参数 (Snoek et al., 2012) [56],这种方法要比广泛使用的网格搜索高效地多。LSTM 的自动超参数调整已经在语言建模产生了最佳的性能,远远胜过其他更复杂的模型 (Melis et al., 2017)。
LSTM 技巧
学习初始状态:我们通常初始化 LSTM 状态为零向量。但我们可以将初始状态看作参数进行优化,而不是人为地调整来提升性能。这一方法十分受 Hinton 的推荐。关于这一技巧的 TensorFlow 实现,详见:https://r2rt.com/non-zero-initial-states-for-recurrent-neural-networks.html
尝试输入和输出嵌入:适合于输入和输出嵌入在 LSTM 模型中占了绝大多数参数数量的情况。如果 LSTM 在语言建模中预测词汇,输入和输出参数可以共享 (Inan et al., 2016; Press & Wolf, 2017) [54, 55]。这一技巧在不允许学习大规模参数的小数据集中十分有用。
梯度范数截断(Gradient norm clipping):降低梯度消失风险的一个方法是截断其最大值 (Mikolov, 2012) [57]。但是这并没有持续提升性能(Reimers & Gurevych, 2017)。与其独立地截断每个梯度,截断梯度的全局范数 (Pascanu et al., 2013) 反而会带来更加显著的提升(这里有一个 Tensorflow 实现:https://stackoverflow.com/questions/36498127/how-to-effectively-apply-gradient-clipping-in-tensor-flow
)。
下投影(Down-projection):为了进一步减少输出参数的数量,LSTM 的隐态可以被投影到更小的尺寸。这对带有大量输出的任务尤其有用,比如语言建模(Melis et al., 2017)。
特定任务的最佳实践
下面,我们要介绍特定任务的最佳实践。大部分模型在执行特定类型的单项任务时表现很好,部分模型可以应用于其他任务,不过在应用之前需要验证其性能。我们还将讨论以下任务:分类、序列标注、自然语言生成(NLG)和自然语言生成的特殊案例神经机器翻译。
分类
由于卷积操作更加高效,近期 CNN 应用范围扩大,成为处理 NLP 中分类任务的通用方法。下面的最佳实践和 CNN 相关,可选择多个最优超参数(optimal hyperparameter)。- CNN 过滤器:使过滤器大小接近最优过滤器大小,如 (3,4,5) 性能最佳(Kim, 2014; Kim et al., 2016)。特征映射的最佳数量范围是 50~600(Zhang & Wallace, 2015)[59]。
- 聚合函数(Aggregation function):1-最大池化优于平均池化和 k-最大池化(Zhang & Wallace, 2015)。
序列标注
序列标注在 NLP 中非常普遍。现有的很多最佳实践都是模型架构的一个环节,下列指南主要讨论模型输出和预测阶段。
标注策略(Tagging scheme): 对于将标签分配到文本分隔的任务,不同的标注策略均可采用。比如:BIO,分隔的第一个符号处标注 B-tag,其他符号处标注 I-tag,分隔外的符号标注 O-tag;IOB,和 BIO 相似,不同之处在于如果前面的符号属于相同的类别,但不属于同一个分隔,则使用 B-tag 来标注;IOBES,还需要在单个符号实体处标注 S-tag,每个分隔的最后一个符号处标注 E-tag。IOBES 和 BIO 的性能相似。
条件随机场输出层(CRF output layer): 如果输出之间存在依赖,如在命名实体识别(named entity recognition)中,可以用线性链条件随机场(linear-chain conditional random field)代替最后的 softmax 层。经证实,这种方法对于要求对约束进行建模的任务有持续改善的效果(Huang et al., 2015; Max & Hovy, 2016; Lample et al., 2016)[60, 61, 62]。
约束解码(Constrained decoding): 除了条件随机场输出层以外,还可用约束解码来排除错误排序,即不产生有效的 BIO 过渡(BIO transition)(He et al., 2017)。约束解码的优势在于可以执行随意约束(arbitrary constraint),如特定任务约束或句法约束。
自然语言生成
多数现有最佳实践可用于自然语言生成(NLG)。事实上,目前出现的很多技巧都植根于语言建模方面的进步,语言建模是最典型的 NLP 任务。
建模覆盖率(Modelling coverage): 重复是 NLG 任务的一大难题,因为当前的模型无法很好地记忆已经产生的输出结果。在模型中直接设置建模覆盖率是解决该问题的好方法。如果提前知道哪些实体应该出现在输出结果中(就像菜谱中的调料),则需要使用一个检查表(checklist)(Kiddon et al., 2016)[63]。如果使用注意力机制,我们可以追踪覆盖率向量 c_i,它是过去的时间步上注意力分布 a_t 的总和(Tu et al., 2016; See et al., 2017)[64, 65]: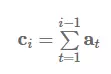
该向量可以捕捉我们在源语言所有单词上使用的注意力。现在我们可以在覆盖率向量上设置加性注意力(additive attention),以鼓励模型不重复关注同样的单词:
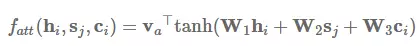
此外,我们可以添加辅助损失(auxiliary loss),该损失可以捕捉我们想关注的特定任务的注意力行为:我们希望神经机器翻译可以做到一对一对齐(one-to-one alignment);如果最后的覆盖率向量多于或少于每一个指数上的覆盖率向量,那么模型将被罚分(Tu et al., 2016)。总之,如果模型重复处理同样的位置,我们就会惩罚该模型(See et al., 2017)。
神经机器翻译- 虽然神经机器翻译只是 NLG 的一个分支,但 NMT 获得了大量关注,有许多方法专门为该任务开发。相似地,许多最佳实践或超参数选择只能应用到 NMT 领域。
- 嵌入维度(Embedding dimensionality):2048 维嵌入的性能最佳,但很少达到该效果。128 维嵌入的性能却出乎意料地好,收敛速度几乎达到之前的 2 倍(Britz et al., 2017)。
- 编码器和解码器深度: 编码器的深度无需超过 2−4 层。深层模型性能优于浅层模型,但多于 4 层对解码器来说没有必要(Britz et al., 2017)。
- 方向性(Directionality):双向编码器性能稍好于单向编码器。Sutskever et al.(2014)[_67_] 提出颠倒源语言的顺序,以减少长期依赖的数量。使用单向编码器颠倒源语言顺序优于未颠倒语序(Britz et al., 2017)。
- 束搜索策略(Beam search strategy):大小 10、长度归一化罚项为 1.0 的中型束(Wu et al., 2016)性能最佳(Britz et al., 2017)。
- 子词翻译(Sub-word translation):Senrich et al. (2016) [66] 提出根据字节对编码(byte-pair encoding/BPE)将单词分隔成子词(sub-word)。BPE 迭代合并出现频率高的符号对(symbol pair),最后将出现频率高的 n 元合并成一个单独的符号,进而有效去除非词表词(out-of-vocabulary-word)。该技术最初用来处理罕见单词,但是子词单元的模型性能全面超过全词系统,32000 个子词单元是最高效的单词数量(Denkowski & Neubig, 2017)。
结语
我确定这份清单上一定有遗漏的最佳实践。相似地,也有很多我不熟悉的任务,如解析、信息提取,我没办法做出推荐。我希望本文对开始学习新的 NLP 任务有所帮助。即使你对这里列出的大部分内容都很熟悉,我也希望你能够学到一些新的东西或者重新掌握有用的技巧。
本文来源于微信公众号:机器之心(almosthuman2014),如需转载,请私信联系,十分感谢。
发布于 2017-07-26
​赞同 205​​2 条评论​分享
​收藏​喜欢​
收起​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

杨智
互联网
117 人赞同了该回答
说说自己的历程吧。
我是一名非科班的自然语言,机器学习,数据挖掘关注者。
因工作关系,5年前需要做与自然语言处理的项目。当时的项目老大先是扔给我一本书《统计自然语言处理》,直接给我看蒙了。不能说一点都不懂,但是看的云里雾里,不知道get几层。
但看这本书的过程中,我狂搜了些自然语言处理的课件,有北大的,中科院的,都写的很好,从语言模型开始。从分词,标注,语法树,语意等等。也大体知道自然语言处理,分词法,语法,语义。然后是各种应用,信息检索,机器翻译等自然语言经典应用问题。
断断续续做了些小项目,基于语言模型的拼音输入法,仿照sun'pinyin写的,他们的blog写的很详细,从模型建模,到平滑处理,很详细,我也用python实现了一遍,当时这个输入法配合上一个简单的ui还在部门内部推广了,搞了个基于云的拼音输入法,获得个小奖品,很是洋洋得意。这个过程中,我看着sunpinyin的blog, 回过头又去看课件,去了解很细节的问题,如拉普拉斯平滑,回退平滑的细节等,收获很多。
后来老大告诉我,看自然语言问题时,可以找博士论文先看,因为博士论文一般都会来龙去脉讲的非常详细,看完一遍之后基本上这个问题就了解的差不多,然后就是follow业界的进度,那就是关注各种会议和期考,可自行百度和谷歌。
搞好这个拼音输入法,进入实际项目,做一套中文自然语言的基础处理引擎,好在不是让我一个人来,公司开始找大学合作,我做企业项目负责跟进的,大学负责具体算法,我跟着自己调查分词标注算法,了解了有基于词典的,语言模型的,hmm,crf的,那个crf的,我始终搞不大明白,后来先了解了hmm的vertbe算法,em算法,大学的博士给我讲了一遍crf,终于豁然开朗。还把解码过程写到了http://52nlp.cn
上,关注的人还可以。从那以后我感觉我就真入门了。在来一个什么问题,我基本上也有套路来学习和研究了。总结下,
1.先各种课件,加那本自然语言的书,搞清楚自然语言大概都有哪些问题,主要是为了解决什么问题的。
2.基于某个问题看博士论文,了解来龙去脉。然后follow业界进度。
3.找各种资源,会议的,期刊的,博客http://52nlp.cn
(不是打广告,我不是博主,不过博客真心不错)
4.微博上关注各种这个领域的大牛,他们有时候会推荐很多有用的资料。
当然,数学之美 我也读了,确实不错。
发布于 2016-05-15
​赞同 117​​13 条评论​分享
​收藏​喜欢​
收起​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

川陀学者
​
谷歌 软件工程师
49 人赞同了该回答
强烈推荐斯坦福的两门课,均是斯坦福NLP大牛Chris Manning教授的。
第一门是Natural Language Processing,Chris和另一个大牛Dan Jurafsky共同讲授。这门课于2012年讲授,主要是从偏统计以及传统机器学习方法来入门NLP,对于了解NLP研究领域、应用场景以及基础方法十分有效。讲义在https://web.stanford.edu/~jurafsky/NLPCourseraSlides.html
, 视频在Stanford Online官网
https://www.youtube.com/playlist?list=PLoROMvodv4rOFZnDyrlW3-nI7tMLtmiJZ
。
第二门是cs224n: Natural Language Processing with Deep Learning, 主要是以深度学习的方法来解决NLP问题,内容也稍微新一些,着重于RNN、Attention机制和Transformer模型,可以在第一门课的基础上了解前沿成果。其官网是http://web.stanford.edu/class/cs224n/index.html
, 2019冬季学期的视频列表链接为https://www.youtube.com/playlist?list=PLoROMvodv4rOhcuXMZkNm7j3fVwBBY42z
,学习笔记可参考
川陀学者:斯坦福CS224N深度学习自然语言处理2019冬学习笔记目录​zhuanlan.zhihu.com
编辑于 2019-03-31
​赞同 49​​2 条评论​分享
​收藏​喜欢​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

阿里云云栖号
​
已认证的官方帐号
94 人赞同了该回答
下面这篇自然语言处理入门教程,希望对你有所帮助。
自然语言处理(NLP)是计算机科学领域和人工智能领域中的一个分支,它与计算机和人类之间使用自然语言进行互动密切相关。NLP的最终目标是使计算机能够像人类一样理解语言。它是虚拟助手、语音识别、情感分析、自动文本摘要、机器翻译等的驱动力。在这篇文章中,你将学习到自然语言处理的基础知识,深入了解到它的一些技术,了解到NLP如何从深度学习的最新进展。
1.简介
自然语言处理(NLP)是计算机科学、语言学和机器学习的交叉点,它关注计算机与人类之间使用自然语言中的沟通交流。总之,NLP致力于让计算机能够理解和生成人类语言。NLP技术应用于多个领域,比如天猫精灵和Siri这样的语音助手,还有机器翻译和文本过滤等。机器学习是受NLP影响最深远的领域之一,尤为突出的是深度学习技术。该领域分为以下三个部分:
1.语音识别:将口语翻译成文本。
2.自然语言理解:计算机理解人类的能力。
3.自然语言生成:计算机生成自然语言。
2.为什么NLP很难
人类语言有其特殊性。人类语言专门用于传达讲话者和写作者的意思,即使小孩子能够很快学会,它依然是一个复杂的系统。它的另一个显著之处在于它完全与符号有关。Chris Manning(斯坦福教授)表示,它是一个离散的、象征性的、绝对的信号系统,这意味着人们可以通过使用不同的方式传达相同的含义,比如演说,手势,信号等。人类大脑对这些符号的编码是持续的激活模式,在这个模式中,符号通过声音和视觉的连续信号实现传输。
由于其复杂性,理解人类语言被认为是一项艰巨的任务。例如,在句子中排列单词有无数种不同的方法。此外,一个单词可以有多种含义,并且正确解释句子需要恰当的语境信息。每种语言或多或少都是独特且含糊的。比如:“The Pope’s baby steps on gays”,这句话显然有两种截然不同的解释,这是反映NLP中的困难之处的一个很好的例子。
随着计算机对语言的理解愈渐完美,将会产生可以处理互联网上全部信息的人工智能(AI),继而产生强人工智能(AGI)。
3.句法和语义分析
句法分析和语义分析是理解自然语言的两种主要方法。语言是一组意义的语句,但是什么使语句有意义呢?实际上,你可以将有效性分为两类:句法和语义。术语“句法”是指文本的语法结构,而术语“语义”是指由它表达的含义。但是,句法上正确的语句不必在语义上正确。只需看看下面的例子。语句“cow kow supremely”在语法上是有效的(主语-动词-副词),但没有任何意义。
句法分析:

句法分析,也称为语法分析或解析,是通过遵循正式语法规则来分析自然语言的过程。语法规则适用于单词和词组,而不是单个单词。语法分析主要为文本分配语义结构。
语义分析:
我们理解他人的语言是一种无意识的过程,依赖于直觉和对语言本身的认识。因此,我们理解语言的方式很大程度上取决于意义和语境。计算机却不能依赖上述方法,需要采用不同的途径。 “语义”这个词是一个语言术语,意思与意义或逻辑相近。
因此,语义分析是理解单词、符号和语句结构的含义和解释的过程,这使计算机能够以人类的方式理解部分涉及意义和语境的自然语言。为什么说只能部分理解呢?是因为语义分析是NLP中最棘手的部分之一,仍未完全解决。例如,语音识别技术已非常成熟,并且工作近乎完美,但仍然缺乏在自然语言理解(例如语义)中的熟练程度。手机基本上可以理解我们所说的内容,但通常无法用它做任何事情,因为它不了解其背后意义。
4.理解文本的技巧
下面我们将讨论多种用于自然语言处理的现行技术。
什么是解析?首先,让我们看一下词典释义:
解析—“将句子分解为其组成部分,并阐述各部分的句法角色。”
实际上解释的已经非常到位,但它可以更全面一些。解析是指计算机对句子的形式分析,其结果是一个解析树,这个解析树可以可视化地显示句子成分之间的句法关系,用于进一步处理和理解。
在下面你可以看到句子“The thief robbed the apartment”的解析树,以及由它传达的三种不同信息类型的描述。
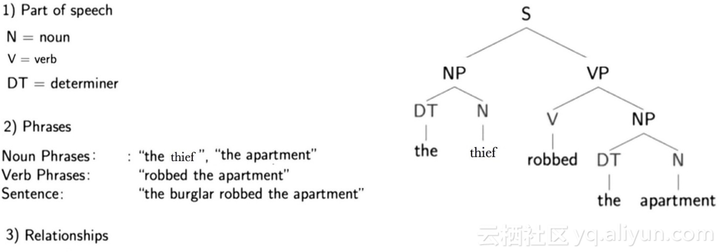
我先看单个单词正上方的字母,它们用于显示每个单词的词性(名词-N,动词-V和限定词-DT)。我们再看解析树中更高的层级,一些单词进行层次分组组成短语。例如,“the thief”是一个名词短语(NP),“robbed the apartment”是一个动词短语(VP),这些短语一起形成一个句子(S),在树中标记在更高的层级。
这些短语以名词为主体,包含一个或多个单词,可能还包含描述性词语、动词或副词,简言之,就是把把名词和与其相关的单词组合在一起。
从解析树中还能看出,单词的表述结构影响其在句中的语法关系。例如,在此结构中,“thief”是“robbed”的主语。
结合结构来看,动词“robbed”,上方标有“V”,更上一级标有“VP”;主语“thief”,上方标有N和“NP”,通过“S”联系在一起。这就像主语—动词关系的模板,同样还有许多其他类型的关系。
词干提取:
词干提取是一种来自形态学和信息检索的技术,在NLP中用于预处理和效率提升。但是,我们首先看一下词典中的释义:词干 — “起源于或由其引起。”
基本上,“词干提取”是将单词进行缩减得到词干的过程,而“词干”的实际意义是是在删除单词的所有的前缀后缀之后保留的一部分。例如,“touched”,它的词干是“touch”,同时“touch”也是“touching”等词的词干。
为什么需要词干?因为我们会遇到不同的词汇变形,而实际上它们具有相同的词干和意义。举例来说:
# I was taking a ride in the car
# I was riding in the car.
这两个句子意思是一致的,ride和riding的用法也是相同的。
词汇表中所有的单词有不同的注释,其中还包括大量实际意义相同的单词,要存储它们,需要一个庞大数据库,但是通过词干提取,仅关注单词的词干,可以很好地解决这个问题。现行的通用算法之一是1979年的“Porter Stemming Algorithm”(波特词干算法),非常使用便捷。
文字分割:
NLP中的文本分割是将文本转换为有意义的单元的过程,可以是单词、句子、也可以是不同的主题或潜在的意图等。在文本分割中,文本根据不同语种被分割为成份单词,由于人类语言的复杂性,通常比较难。举个例子,在英语中利用空格来分隔单词,相对高效实用,但是也有像“ice box”这类词语的例外,ice和box这两个由空格隔开的词合并一起使用才有原本含义的,所以人们有时把它写作“ice-box”,那么就给文字分割带来了难题。
命名实体识别:
命名实体识别(NER)用于确定文本中哪些词条属于命名实体,这些词条可以被定位并归入预定义的类别,类别的范围包括人名,组织,地点,还有货币价值和百分比。
看下面的例子:
NER之前:Martin bought 300 shares of SAP in 2016.
NER之后:[Martin]Person bought 300 shares of [SAP]Organization in [2016]Time.
关系抽取:
关系提取采用“命名实体识别(NER)”的命名实体,并识别它们之间的语义关系。这可能意味着它能够发现文本中词语之间的关联性,例如谁与谁结婚,某人在哪个公司工作等。这个问题也可以转换为分类问题,然后为每种关系类型训练机器学习模型。
情感分析:
通过情感分析,我们想要确定例如说话者或作者关于文档,互动或事件的态度(例如情绪)。因此,需要理解文本以预测潜在意图是一种自然语言处理问题。情绪主要分为积极,消极和中性两类。通过使用情感分析,我们希望根据他撰写的关于产品的评论来预测客户对产品的看法和态度。因此,情感分析广泛应用于评论,调查,文档等等
如果你对使用Python中的某些技术感兴趣,可以查看我创建的Python的自然语言工具包(NLTK)的Jupyter Notebook。你还可以查看我的博客文章,了解如何使用Keras构建神经网络,我将训练神经网络进行情感分析。
5.深度学习和NLP
深度学习和自然语言的核心是“词义”,在这里,单词用一个实数向量来表示。因此,通过向量来代表单词单词,我们可以将单词置于高维度的空间中,由向量表示的单词起到语义空间的作用。这仅仅意味着在该高维向量空间中,形近意近的单词倾向于聚集在一起。下图中,可以看到单词含义的直观展示:

在此空间中,如果想要知道某一组聚集成类的单词的含义,可以通过使用主成分分析法(PCA),也可以使用降维法。但这些方法太简单并且会遗漏了周边的大量信息,因而产生误差。在研究的初始阶段,这些方法很好用,(如数据科学中的逻辑或线性回归)但并不是前沿技术。
我们还可以将单词的一部分当作向量,这些向量可以代表单词的含义。想象一下“undesirability”这个词。使用“形态学方法”,它涉及一个词所具有的不同部分,我们认为它由词素(单词部分)构成:“Un + desire + able + ity”。每个语素都有自己的向量。这允许我们构建一个神经网络,它可以构成一个更大的单位的意义,而更大的单位又由所有这些语素组成。
深度学习还可以通过创建句法分析器来理解句子的结构,谷歌正在使用这样的依赖解析技术,在他们的“McParseface”和“SyntaxNet”(两种语言解析器),不过更加宏大,更加复杂。
通过分析句子结构,我们开始理解句子的意义,可以从单词的含义开始,也可以从整个短语和句子开始,无论单词的意义、短语还是句子,都用向量来表示。如果想知道句子之间的关系,我们可以创建神经网络来帮助分析。
深度学习也适用于情感分析。请看这个电影评论:“这部电影不在乎是不是巧妙,也不在乎幽默与否”。传统的机器学习算法会认为这是一个积极的评论,因为“聪明”和“幽默”是积极的词汇,但是神经网络能够识别出它的真正含义。
另外,深度学习算法实现的机器翻译中,它从句子开始翻译,并生成一个向量,然后用另外一种语言生成所需要的信息。
总而言之,NLP与深度学习相结合,就是表示单词、短语的向量,以及它们的含义。
本文由阿里云云栖社区组织翻译。
文章原标题《Introduction Into Semantic Modeling for Natural Language Processing》
作者:Aaron Radzinski
译者:Mags,审校:袁虎。
更多技术干货敬请关注云栖社区知乎机构号:阿里云云栖社区 - 知乎
编辑于 2018-09-06
​赞同 94​​添加评论​分享
​收藏​喜欢​
收起​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

陈见耸
自然语言处理、人工智能、机器学习
60 人赞同了该回答
大家回答的都挺不错了,只好来强答。
一、独立实现一个小型的自然语言处理项目。
要找一个合适的的自然语言处理相关的开源项目。这个项目可以是与自己工作相关的,也可以是自己感兴趣的。项目不要太大,以小型的算法模块为佳,这样便于独立实现。像文本领域的文本分类、分词等项目就是比较合适的项目。 运行程序得到项目所声称的结果。然后看懂程序,这期间一般需要阅读程序实现所参考的文献。最后,自己尝试独立实现该算法,得到与示例程序相同的结果。再进一步的,可以调试参数,了解各参数对效果的影响,看是否能得到性能更好的参数组合。
这一阶段主要是学习快速上手一个项目,从而对自然语言处理的项目有比较感性的认识——大体了解自然语言处理算法的原理、实现流程等。
当我们对自然语言处理项目有了一定的认识之后,接下来就要深入进去。任何自然语言处理应用都包含算法和所要解决的问题两方面,要想深入进去就需要从这两方面进行着手。
二、对问题进行深入认识
对问题的深入认识通常来源于两个方面,一是阅读当前领域的文献,尤其是综述性的文献,理解当前领域所面临的主要问题、已有的解决方案有哪些、有待解决的问题有哪些。这里值得一提的是,博士生论文的相关文献介绍部分通常会对本问题做比较详细的介绍,也是比较好的综述类材料。
除了从文献中获取对问题的认识外,另一种对问题进行深入认识的直观方法就是对算法得出的结果进行bad case分析,总结提炼出一些共性的问题。对bad case进行分析还有一个好处,可以帮助我们了解哪些问题是主要问题,哪些问题是次要问题,从而可以帮助我们建立问题优先级。如果有具体任务的真实数据,一定要在真实数据上进行测试。这是因为,即使是相同的算法,在不同的数据集上,所得到的结果也可能相差很大。
三、对算法进行深入理解
除了具体的问题分析,对算法的理解是学习人工智能必须要过的关。经过这么多年的发展,机器学习、模式识别的算法已经多如牛毛。幸运的是,这方面已经有不少好的书籍可供参考。这里推荐华为李航的蓝宝书《统计学习方法》和周志华的西瓜书《机器学习》,这两本都是国内顶级的机器学习专家撰写的书籍,思路清晰,行文流畅,样例丰富。
如果觉得教科书稍感乏味,那我推荐吴军的《数学之美》,这是一本入门级的科普读物,作者以生动有趣的方式,深入浅出的讲解了很多人工智能领域的算法,相信你一定会有兴趣。
国外的书籍《Pattern Recognition and Machine Learning》主要从概率的角度解释机器学习的各种算法,也是不可多得的入门教材。如果要了解最新的深度学习的相关算法,可以阅读被誉为深度学习三架马车之一Bengio所著的《Deep Learning》。 在学习教材时,对于应用工程师来说,重要的是理解算法的原理,从而掌握什么数据情况下适合什么样的数据,以及参数的意义是什么。
四、深入到领域前沿
自然语言处理领域一直处在快速的发展变化当中,不管是综述类文章还是书籍,都不能反映当前领域的最新进展。如果要进一步的了解领域前沿,那就需要关注国际顶级会议上的最新论文了。下面是各个领域的一些顶级会议。这里值得一提的是,和其他人工智能领域类似,自然语言处理领域最主要的学术交流方式就会议论文,这和其他领域比如数学、化学、物理等传统领域都不太一样,这些领域通常都以期刊论文作为最主要的交流方式。 但是期刊论文审稿周期太长,好的期刊,通常都要两三年的时间才能发表,这完全满足不了日新月异的人工智能领域的发展需求,因此,大家都会倾向于在审稿周期更短的会议上尽快发表自己的论文。 这里列举了国际和国内文本领域的一些会议,以及官网,大家可以自行查看。
国际上的文本领域会议:
ACL:http://acl2017.org/
加拿大温哥华 7.30-8.4
EMNLP:http://emnlp2017.net/
丹麦哥本哈根 9.7-9.11
COLING:没找到2017年的
国内会议:
CCKS http://www.ccks2017.com/index.php/att/
成都 8月26-8月29
SMP http://www.cips-smp.org/smp2017/
北京 9.14-9.17
CCL http://www.cips-cl.org:8080/CCL2017/home.html
南京 10.13-10.15
NLPCC http://tcci.ccf.org.cn/conference/2017/
大连 11.8-11.12
NCMMSC http://www.ncmmsc2017.org/index.html
连云港 11.11 - 11.13
像paperweekly,机器学习研究会,深度学习大讲堂等微信公众号,也经常会探讨一些自然语言处理的最新论文,是不错的中文资料。
五、当然,工欲善其事,必先利其器。我们要做好自然语言处理的项目,还需要熟练掌握至少一门工具。当前,深度学习相关的工具已经比较多了,比如:tensorflow、mxnet、caffe、theano、cntk等。这里向大家推荐tensorflow,自从google推出之后,tensorflow几乎成为最流行的深度学习工具。究其原因,除了google的大力宣传之外,tensorflow秉承了google开源项目的一贯风格,社区力量比较活跃,目前github上有相当多数量的以tensorflow为工具的项目,这对于开发者来说是相当大的资源。
以上就是对于没有自然语言处理项目经验的人来说,如何学习自然语言处理的一些经验,希望对大家能有所帮助。

发布于 2017-05-10
​赞同 60​​5 条评论​分享
​收藏​喜欢​
收起​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

zenRRan
一个喜欢乐器,可能也喜欢做饭的小小NLPer~
166 人赞同了该回答
来答一波接地气的回答 大神绕道 哈哈
因为最近在准备本科毕设的论文部分,所以最近原创的相对比较少,但是为了坚持每天学点新知识,我也逼着自己每天抽出晚上的1小时左右把自己想到的并且自己还没理解的小知识点的网上搜索下好的文章,能一下子读懂的,最好有图之类的文章,再根据自己的一些小理解,将文章编辑下,分享给大家。末尾再附上自己的当天准备的五个托福单词,这五个单词我也不是我先学过的,而是托福单词随机到的,在我编辑的时候我也刚好学下。正是在这种逼自己的情况下,我觉得我在这一个多月的时间里真的涨了不少知识。我也真心希望我的粉丝们跟我一样,每天逼着自己,学点知识,用不了一个月,即使一个星期你也会有很多收获的。当然大神们就继续自己的学习方法哈。嘿嘿。
好了,哈哈,想说的太多了,但是该进入我们今天的主题了。因为有很多人问我怎么入门自然语言处理,深度学习,机器学习等问题。我回答的太多了,也真的帮助了很多人。因为我知道入门这件事在有人指点下,真的很节省时间的,没有什么比我们的时间更重要了,要有的话,只能是咱们的亲人了。所以,今天我就总结下,作为小白过来的我的一些经验,若有不对的地方或者更好的经验,欢迎下面评论区写上,大家共享。
怎么能表示自己自然语言处理入门了呢?
那就是写一个分类器,我大三进入NLP实验室,听到新来的研究生师兄师姐们第一个任务总是写一个分类器。而我期间干了很多杂事以及上课,并没有真正的写过一个分类器。再加上考研的原因,我真正写一个自己基本都懂各种细节的文本分类器是在考完研的那个寒假。这个的功能就是给你一句话,你给这句话分个类即可。刚开始最好用CNN这个神经网络,因为这个简单。而你得需要数据,这个你可以去github上搜索,比如cnn text classification +自己喜欢用的框架(tensorflow,pytorch等),里面有代码,也基本会有数据。github真是个好东西,一定要充分利用。
实现分类器的时候,你能学很多东西。
编程语言:python
这个编程语言一定要学,为什么呢?因为俗话说,人生苦短,我用
python。python实现我们的想法确实快,而且我们是机器学习方向,所以需要很多数据,python有很好的数据处理包,并且大家也都知道很多大公司出了python的深度学习框架,比如tensorflow,pytorch等。但是python确实比C++慢,等你学会了用python实现各种算法的应用时,转成C++也会很快的。python只是推荐,如果你直接上手C++也行,只是推荐。
CNN神经网络
因为你要学会CNN来写分类器,所以你应该先把CNN彻底了解了。在你了解CNN的时候,你会学会很多东西。比如神经网络在NLP中到怎么使用的?为什么这么使用?你会了解什么是神经单元,它的计算公式是什么?句子是怎么提取特征放进CNN的,词如何embedding,什么是窗口大小,窗口是怎么计算的,滑动步长代表什么,什么是宽卷积,窄卷积,常用的窗口大小是什么,什么是pooling,pooling细分为哪些pooling,为什么要pooling,什么是全连接,什么是线性变换,怎么映射到类别上的等。你可能会问我能不能先彻底的学习什么是深度学习?我的推荐是,在了解CNN的时候,遇到什么不懂得再去查什么这样学的最快了。在这个期间你学习神经网络的话,推荐看网易云课堂吴恩达的深度学习微专业课程。总之,在解决问题的时候学东西真的效率很高。只是推荐。
是否要系统的学下数学?
我们需要的数学大致为统计学,线数,微积分。入门的时候,微积分会求复合函数导数即可;线数了解矩阵概念,会点乘,叉乘即可;统计学,你的分类器的损失函数一般会是交叉熵,这个时候你具体了解下什么是熵,信息熵,交叉熵。在NLP入门的时候在深度学习火之前是统计的天下,而现在是深度学习和统计一起的天下。现在你不需要系统学这个,只需要遇到问题的时候,涉及什么具体的学什么。
看理论 看github源码 写自己代码
一行一行分析,期间你会学到怎么清洗数据,中文和英文的不同处理法。建立字典,为什么要将文本数字化,什么是padding,怎么表示未登录的词,选择什么样的优化器,设置怎样的学习率,在搭建网络中,你会学到怎么对准维度,数据具体怎么流动,什么是softmax,什么是激活函数,评估方法都有哪些等。
最后一些话
等你入门了,其他的学的就很快了。NLP,CV等入门思路是一样的。机器学习和数学知识在自己有时间的时候还是慢慢学学最好,毕竟万变不离其宗,懂了这些,即使出了新的算法,也能很快理解。前提是有时间的话,我就是抽空就看看这些知识,并总结写成公众号。如果可以的话,找几个比你厉害的人一起学更好!今天就这么多吧,写到凌晨了,如果有什么问题,公众号右下角加我微信。真心希望能帮到你!一起坚持,加油!
-----------------------------我是分割线--------------------------------------------
时间过去了好久了,这次来分享下自然语言处理的进阶接地气的路线
导读
自然语言处理这个方向我感觉已经泛滥了,很多方向的人都开始转向该专业,当然也包括转向计算机视觉的。之前我写过一篇文章
对很多人有过帮助,我感到很开心。但是现在已经不同往日了,很多人早已经入门了。当然,如果你已经进阶了,就忽略这个文章吧。嘿嘿。很多人通过微信,公众号等问我:现在已经看完深度学习视频了,我该怎么办?或者我早已经写完分类器了,接下来怎么办?等等。
我就不一一解答了,其实我也很不好意思解答的,因为我自己现在也没啥成就,研究生3个多月了,论文还木有idea。。啊。我自己都头疼。但是,我可以通过自己,和身边师兄师姐,以及导师的经验来给大家说说。
放下书,动手实践
我导师是最不推荐看书的,当然我刚开始还是反对的,但是时间长了,觉得说的确实很对,很多资料网上都会有。而且,看书也有个问题,你虽然可以系统的学,但是有些东西你一般不会用到的,这就导致时间长了,你不用,你就忘了。其实你目前的知识已经可以了,你了解了深度学习,早就把CNN,RNN(LSTM等变形)懒熟于心,听都听烦了。其实基础已经可以了。该动手实践了。咳咳,马克思说过,实践是检验真理的唯一途径。是吧。
灵活掌握各种常用模型
那么怎么实践呢?我的建议是从学会玩模型开始。当然你有更好的方法,更好。
简单的CNN你已经会了,你应该知道咱们通常用的是单通道的CNN,那么你会写多通道的吗?(多通道其实NLP中用了也是最多2通道,一个是随机化embedding,一个是预训练embedding)然后多层CNN也可以尝试呀。
word级别的你是经常用了,那么char的呢?写写CharCNN(Char经过CNN 然后和Word的embedding cat到一起,得到新的embedding然后再经过CNN)
LSTM你会了,那么和CNN结合怎么用呢?先CNN在LSTM或者先LSTM再CNN都可以,你试试。
之前用的都是线性的,那么非线性的,比如句法树呢?又该怎么用呢?现在常用的有TreeGRU和TreeLSTM,你都可以试试。
再进阶就是seq2seq模型,这个很常用的,别名也可以说是encoder-decoder模型(这里的attention机制你需要具体了解下)。
如果你想挑战下自己,可以看看去年google刚提出的模型Transformer!地址为
http://nlp.seas.harvard.edu/2018/04/03/attention.html
当然,上述只是说了一部分,你有自己的模型学习路线更好啦。
基础的都掌握之后,感觉你就不会定性到最初的CNN,LSTM模型当中了。觉得模型原来可以这么灵活?就会对自己产生了自信感。
然后就可以看论文,看别人的模型怎么实现。最之前的时候,我看别人论文的模型的时候,都是,额,这是怎么搭建的?如果你会了上述的模型,你再看别人论文的时候,心里起码比之前更有底气,更好的情况是论文的模型图你一看心里就已经用代码搭建完毕这个模型!
上面的模型,网上其实很多的,推荐用github搜索,然后选择自己的编程偏好的代码即可。
也可以看我自己入门时搭建的模型框架
地址:https://github.com/zenRRan/Sentiment-Analysis/tree/master/models
欢迎大家star和fork
这个时候也得附上我师兄写的模型了,可以借鉴!
搭建自己的代码框架
我之前写代码都不怎么考虑可读性,别人的可用性。既然是进阶阶段,就要学会自己搭建自己的框架。看看导师的github的代码风格,看看你敬佩的师兄的代码风格,或者看看国外大佬的代码风格等。多看看,最终形成自己的代码风格。看看模块怎么搭建?代码怎么注释?哪些函数用起来即简单又方便等。
搭建自己github项目时,记得写readme!要把readme写的越详细越好,最好能让别人看到你的readme直接就能灵活运用你的代码。
对了,这里说下为什么要搭建自己的模型框架:因为自己的框架搭建好之后,以后无论写写什么模型,都可以直接套过来用,不用再重新实现一些重复的代码。
其他建议
CRF你需要了解;要实时关注咱们这个方向的国际大牛的动态;慢慢补充自己的概率论,线数的短板(这个目前我刚开始要补,哎,加油加油);每天学点英语吧,为以后写论文打基础(我坚持了很长时间后,现在有点松懈,不行不行,继续坚持)
先写到这里吧。以后再补充啦!嘿嘿
---------------------我是分割线----------2020.7.23----------------------------------------
因为自己实验室的准研一师弟们还未开学但基本都已经入门NLP了,所以想到号里应该还有大量还在NLP门口徘徊、急需嗷嗷待哺的伙伴们,就制定了如下NLP入门计划!
完全义务哒,请放心食用啦!嘿嘿~
目标
2个月内完全入门,能上手项目和着手自己的科学研究。
具体安排
Python短时间完全上手,很简单。深度学习&NLP基础- 了解深度学习神经网络基础数学知识(正向传播、反向传播、梯度下降、激活函数、softmax、损失函数等各种细节)(1周)
- 掌握CNN,并写一个文本分类器,调参到最佳值(推荐:论文Convolutional Neural Networksfor Sentence Classification,使用深度学习框架PyTorch)(2周)
- 掌握RNN、LSTM,并写一个分类器,调参,得到新的结果。(1周)
- 掌握Attention,并添加到LSTM里,再次优化分类器,调参,得到新的结果。(1周)
- 了解NLP基础任务,知道深度学习的广泛用途(1周):
基础任务:分词、命名实体识别、词法分析、依存句法分析、语义角色标注、意见角色标注等
上游任务:情感分析/意见挖掘、命名实体识别、机器翻译、人机对话等 - 了解Transformer、BERT(尽量会使用)(1周)
- 了解GNN(了解GCN、GAT等)(1周)
然后,就可以开始看论文,找自己的喜欢的研究方向吧~
参考学习路径- bilibili上很多视频网站,推荐吴恩达机器学习、深度学习课程;以及林轩田、李宏毅的机器学习、深度学习课程。
- stanford nlp cs224d 课程
- 邱锡鹏:《神经网络与深度学习》https://nndl.github.io/
- 学会做笔记,整理学到的东西
大家留言补充其他学习路径撒!
进群获取资料和免费答疑
【深度学习自然语言处理】公众号后台回复新手入门,获取微信二维码!
记得备注:昵称-学校(公司)-新手入门
添加后,会统一邀请大家进群啦!
这么好的事情,希望大家转发给身边的伙伴呀!
听说双击屏幕会有好事情发生O.O
编辑于 2020-07-23
​赞同 166​​14 条评论​分享
​收藏​喜欢​
收起​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

yuquanle
NLPer/订阅号:AI小白入门
专业
已有 1 人赠与了专业徽章
189 人赞同了该回答

作为一名自然语言初学者,在nlp里摸爬滚打了许久,一些心得,请壮士收下。
谈一下自己探索过的摸爬滚打过的方法,大致可以分为二种。
第一种,在实践中学习,找一个特定的任务,譬如文本分类、情感分析等。然后以做好任务为导向的去挖掘和这一个任务相关的知识点。 由于没有系统的学习,肯定会遇到各种各样的拦路虎问题,当遇到不懂的概念时,利用百度/谷歌查阅相关资料去理解学习这个概念,若是概念难懂,就多看不同的人对这些概念的理解,有的时候有些人能深入浅出的讲解一些很不错的资料,个人觉得这种有目的性的实践学习方式学来的东西更加印象深刻。
这样也在潜移默化中锻炼了个人能力(独立查找资料/文献是一种极其重要的能力),又能达成某些目的。这样过了一段时间之后,好像懂很多东西了,但是好像又有很多方面不了解,其实这就是在某个点有点深度了,但是广度还不够。
如果此时有大把闲置的时间,就可以去刷刷那些不错的系统性课程,刷课的时候会发现很多概念理解起来轻松多了,或者说似曾相识(理解的知识点又得到了复习并再次确认自己的理解了的知识点和这些老师讲的是否一致)。
第二种,就是一上来就是刷课刷书,把理论什么的都梳理一遍,然后根据课程把课后作业都敲一遍并且理解。
这样系统的学习虽然会花上很长的时间,但是也会让你对知识体系有个全面的认识,之后你再进去某个小点(比如文本分类等)的深入探索,会发现很多东西都理解学习过。
其实你已经有了知识的广度,但是对某个点的知识深度还欠缺,此时就按需深挖即可,当然,这个过程肯定也不轻松。
其实这二种学习方法我觉得都挺不错,根据自身具体情况具体分析,交叉使用,效果应该更佳。现在回过头来看,我之前的学习方法更像第一种。
最近想从头开始学一些基础知识,以查漏补缺,所以收集了一大波不错的资料,作为新年大礼包送给初学者们,往下看,你想要的都在后面,记得看完免费的赞来一个哟!!!
关注博主的脚步,手把手带你学AI[img=66,66][/img]" data-caption="" data-size="normal" data-rawwidth="66" data-rawheight="66" class="content_image lazy" width="66" data-actualsrc="https://pic2.zhimg.com/50/v2-2245371aa2e31483e46760394855b683_hd.jpg?source=1940ef5c">
编程语言
初学者推荐python,安装方法可以选择纯python安装也可以选择Anaconda方式安装。IDE推荐pycharm。此外,强烈推荐初学者使用jupyter来学习代码,感觉真的超级赞。
对于新手应该如何学python,个人觉得最重要的是写,排除那种特别优秀的人,相信大部分人都可以归入到我亦无他,唯手熟尔。因此前期的代码量是必不可少的,即使在不熟悉的语法情况下对着敲也不失为一种不错的方法,总而言之,要敲,要实践,从而达到手熟。
有人会问,那我一开始敲什么呢? 初学者建议把python基本语法敲一遍,可以配合jupyter,这样可以很方便的敲完一个方法就能实时运行展示效果。然后敲一些基础的python包的基本用法,譬如最基本的numpy、pandas、matlibplot三剑客。
个人建议一开始没必要对里面的每个方法都去深究,这样做会很费时而且可能正反馈也不大,把简单的基本的用法敲几遍熟悉,在这个过程中,要慢慢锻炼一种能力:碰到问题能够独立通过百度/谷歌解决。以后会发现这种能力尤为重要。
自然语言处理初学者首先要了解熟悉nlp领域的基本术语、任务定义以及一些基本算法,前期可以结合一些不错的工具实践,比如经典的jieba、hanlp、snownlp、stanfordcorenlp、spaCy、pyltp、nltk、textblob、gensim、scikit-learn等,以及最近的pkuseg、flair等等。通过这些熟悉比如任务的输入输出、评价指标以及应用场景等等。
书籍推荐
个人觉得从头到尾的看书对于初学者来说不太友好,但是必备的工具书放在手边经常查阅是必不可少的。比如周志华老师的西瓜书《机器学习》、李航的《统计学习方法》、宗成庆的《统计自然语言处理》以及花书《Deep Learning》等等。另外一些比较有意思的书譬如《数学之美》也可以读读,通俗易懂的语言会让你对这个领域产生兴趣,最后推荐一本培养机器学习思维的书《Machine Learning Yearning》。
就此打住,对于初学者这几本工具书我觉得够了。不想买书的童鞋也没关系,可以直接看pdf电子档,网上资料很多,找不到的童鞋也没关系,请在以下链接自取。(ps:知乎放百度网盘链接时文章一直b不能通过审核,需要的童鞋可以关注公众号:AI小白入门,原文包含所有资料的百度网盘链接)
此外,当你们发现手头的资料不够的时候,相信你已经拥有了自我搜索寻找更好更进阶资料的能力了,所以我这里也不多说了,授人以鱼不如授人以渔。
搜索资料一般最简单的就是百度、谷歌,相同的关键词在这二种搜索引擎上得到的结果可能也大相径庭,所以在不能找到满意的结果时不妨二者都尝试下。另一方面,一些开放了github的项目也可以去github上提问,当然github也是搜代码的好平台。初学者可以慢慢尝试,总结经验,以便培养自己的解决问题的能力。
当你能力再提升到一个阶段时,可能现阶段的东西都不能满足你,此时,可以锻炼直接看官方API了,第一手资源当然是最好的选择,一些前沿的东西可以直接看相关paper。关于如何寻找相关文献我后面会给出自己的一些经验。
视频课程
时间充裕的朋友还是推荐有选择性的看一下不错的课程,这里收集了一大波优秀的免费课程,请收下这个大礼包。
- 网易云课堂有吴恩达的名为深度学习工程师免费微专业。 一共包括四周课程,分别为: 1. 神经网络和深度学习 2. 改善深层神经网络:超参数调试、正则化以及优化 3. 结构化机器学习项目 4. 卷积神经网络 5. 序列模型
- Oxford Course on Deep Learning for Natural Language Processing:
Oxford Course on Deep Learning for Natural Language Processing​machinelearningmastery.com
https://www.bilibili.com/video/av1624332?from=search&seid=4057788908786740054​www.bilibili.com
2.机器学习技法:https://www.bilibili.com/video/av12469267?from=search&seid=11378166456310804026​www.bilibili.com
教程习题解答:https://github.com/Doraemonzzz/Learning-from-data
我相信以上大家肯定都或多或少听过,应该都属于经典教程了,所以有大量时间的初学者可以花时间钻研学习,看不懂的地方多看几篇,再看不懂就网上查阅各种资料包括别人的学习笔记继续研究,相信经历过之后肯定是豁然开朗并且功力大为长进。
推荐黄海广博士的笔记,作为参考:
学术论文
当知识贮备到一定量的时候,自身的能力也提升上来了,此时就可以直接看第一手资源了:官方API和论文。
关于论文,如果是研究生的话基本上都绕不过去,所以问题来了,我们应该看什么样的文章?答案自然是看高质量的文章啦~ 这不是废话么,那高质量的文章应该如何去找呢?
国内有一个关于计算机的排名叫
CCF推荐排名:https://www.ccf.org.cn/xspj/gyml/
里面保罗了计算机各大领域的会议期刊排名,比如计算机体系结构、计算机网络、人工智能、数据挖掘等等。CCF推荐排名把会议和期刊被分成A,B,C三类。但是这个国内人搞的,国外基本不看这个。不过被推到这里的会议/期刊质量都还算不错。
国外把ACL、EMNLP、NAACL、COLING被称为NLP四大顶会,其中唯独ACL在CCF里面是A类,可见在ACL中一篇文章是很难的(ps:这也是作为nlper的我以后的目标之一)。ACL学会在北美和欧洲召开分年会,分别称为NAACL和EACL。ACL学会下设多个特殊兴趣小组,其中比较有名的诸如SIGDAT、SIGNLL等。而EMNLP则是SIGDAT组织的国际会议。比较有名的还有SIGNLL组织的CoNLL。
NLP/CL也有自己的旗舰学术期刊Computational Linguistics和ACL创办的期刊TACL,虽然TACL目前没有被推入CCF,但是TACL真的超级难感觉。
作为交叉学科,也有很多相关领域值得关注。主要包括:信息检索和数据挖掘领域:SIGIR、WWW、KDD、WSDM等和人工智能领域: AAAI、IJCAI等。
对于期刊和会议,建议大家直接看会议文章,因为会议文章都比较实时,而且大多数人会把直接的最新研究发到会议上,中了会议之后再去做进一步完善补充扩展成期刊。所以对于目的为发文章的研究生,首先看会议文章即可,当发现此文值得深入研究的时候,可以去尝试寻找期刊版(当然也不一定有)。
那么应该如何下载文章呢?
对于会议文章直接去主页搜索接收文章列表,很多不会提供下载链接,那就把需要的文章名复制粘贴到百度学术/谷歌学术里面去搜索下载。
深度学习框架
深度学习如此火热,当然在自然语言处理也激起了不小的浪花,比如从2013年的word2vec到现在的BERT,都是很不错的工作,初学者肯定也是要接触深度学习框架的,那面对众多的框架应该如何选择呢?
深度学习框架很多,包括TensorFlow、Keras、Caffe、CNTK、PyTorch、MXnet、DeepLearning4J、Theano、PaddlePaddle、Chainer、Lasagne等等。推荐初学者keras,Keras是一个高层神经网络API,它由纯Python编写而成,并基于Tensorflow、Theano以及CNTK作为后端。
当然,写工程更多的是用Tensorflow,搞学术的人可能更喜好Pytorch。所以这里也收集了一些不错的资料。 Keras
Tensorflow
Pytorch
项目实践
如果组里面有相关项目,好好做,跟着师兄师姐,能学到不少东西。
如果有大厂的实习机会,争取去,工业界能学到更多与以后工作息息相关的东西。
如果没有实习机会,也没有项目做,那可以关注下比赛,找一下相关的比赛,下载数据集,排行榜可以实时看到你写的模型的性能。初学者可以去github找相关的开源模型,先跑起来,再想着如何去改进,以此锻炼自己的工程能力。 之前有人私信问我,这些比赛的信息去哪里找? 一般一些比赛在放出来之前,会做一些推广,在一些公众号或者群里能看到软文。但是这些信息不一定能被我们及时看到,但是比赛一般都会放到平台上,最出名的平台之一当属kaggle,其它的还有天池、CCF、AI Challenger、DF、DC、biendata等等。
据我所知,自然语言处理相关的比赛一般可分为二类,一类是学术型的评测,一类是工业界举办的比赛。
很多企业会举办比赛,吸引很多人来参与,特别是一些大企业,宣传工作会做得很到位,大家稍微注意下,一般都能听到风声。
学术型的评测也很多,比如NAACL的评测SemEval( International Workshop on Semantic Evaluation),这种伴随着会议的评测,一般每年都会开放很多任务,在规定时间内报名参加,得到好的名次还可以写一篇评测论文。出名的比如CIKM、SIGKDD等等,大家可以关注。国内的话像NLPCC、CCKS等也会开放评测。
关乎代码,最好的方法就是不断的练习,对于自然语言处理也不例外,在学习理论的同时,也要积累代码量。关于这一块,初学者可以选定研究的小方向之后,尝试自己写代码/或者参考网上代码去跑一些baseline的demo。
拿文本分类来举例,最简单的是one-hot,然后是tf-idf、lda、lsa,到word2vec、glove、fasttext,再到textrnn、textcnn、han等,最后到现在的elmo、bert,这一套过来,关于文本分类这一个自然语言处理下的小方向的流行模型我相信基本上都会清晰很多。
ps:这里说的虽然简单,但是要这样过一遍,就是参考优秀的代码跑通相信对于大多数人来说也需要花费很多时间,但相信这也是锻炼成为一位AI算法工程师的必经之路。
重磅干货
不要愁找不到免费的优质资料,新年大礼包打包送给您。https://www.bilibili.com/video/av14327359?from=search&seid=3833085266966927378​www.bilibili.com
本书代码库: https://github.com/diveintodeeplearning/d2l-zh
编辑于 2019-02-08
真诚赞赏,手留余香
赞赏
还没有人赞赏,快来当第一个赞赏的人吧!
​赞同 189​​14 条评论​分享
​收藏​喜欢​
收起​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

秋天的松鼠
码农/机器学习/健身/美食
62 人赞同了该回答
上面好多大佬给推荐了很多很好的教程,不强答了。
个人觉得NLP如果不是做学术研究钻算法的,其实很多艰深的著作看过不用的话过段时间就忘,而且容易丧失兴趣。说到最快入门的话,分情况讨论:
1 手头有个项目,需要快速自学完成。举个例子,比如接到任务要做一个sentiment analysis的系统。先去网上,CSDN,博客园,知乎,quora,等等,找一篇该主题的入门引导教程,看看有什么入门级读物,经典论文可以看,先把这些基础资料过一遍,比如对于sentiment analysis,一般很快就会找到一本Bing Liu写的一百多页的小册子,很入门。然后看见基础入门材料的过程中,看到有算法有包可以用都记下来,一个个试。看完这些基本就知道项目怎么做了,如果对现有的包不满意,觉得自己写会更好,就按着你的思路钻算法的本质,充分利用楼上大佬们推荐的经典教材,找到相关的部分看,搞懂了之后自己写。这时候,你对这个领域就算是入门了。
2 手头没有项目,纯想学NLP这个技能,比如找工作想多点些技能树。这种情况下,去找个项目做,比如kaggle,codeproject等,或者github上贡献代码。活儿揽下来后,按1中的步骤走。
3 理论派,兴趣在于算法,纯希望了解NLP的算法在数学上是怎么work的。这种情况,数学好时间足的话直接找本大佬们推荐的教材开始看,不然的话找一个好的入门课程,然而印象中在coursera上好像没怎么发现过,但可以推荐CMU的LTI开的algorithms for NLP,网上应该找得到这个课的公共主页,上面有课件。不过看懂这个课也是需要数学基础的。按着这个课件把主要的topic都cover一遍,想看深一点的就到推荐的经典教材里去找来看。
发布于 2016-07-04
​赞同 62​​3 条评论​分享
​收藏​喜欢​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

木叶
博客:http://muyefeifei.com
605 人赞同了该回答
不请自来,语言学背景,研二。废话不说,直接上货。
书籍篇:
入门书籍挺多的,我也看过不少。
1)《数学之美》(吴军)
这是我看的第一本关于NLP的书。现在第二版出来了,貌似新增了两章内容,还没看过。第一版写的挺好,科普性质。看完对于nlp的许多技术原理都有了一点初步认识。现在没事还会翻翻的。
2)《自然语言处理简明教程》(冯志伟)
冯志伟老师这本书,偏向于语言学,书略厚。关于语言学的东西很多。都是很容易理解的东西。建议没有学过理工科们翻一翻,毕竟nlp这东西未来趋势可能会融合不少语言学的东西。
3)《自然语言处理综论》(Daniel Jurafsky)
这本书也是冯志伟老师翻译的,翻译的挺棒,看了差不多一半。综论性质的,选感兴趣的章节翻翻就行。作者是Daniel Jurafsky,在coursera上面有他的课程,后面视频篇里集中谈。
4)《自然语言处理的形式模型》(冯志伟)
这本书还是冯志伟老师写的。很佩服冯志伟老师,文理兼修,而且都很厉害。内容许多是从他以前的著作里面摘取的。算是一本各种语言模型和统计模型的大集合吧。放在桌面,没事翻翻也能是极好的。
5)《统计自然语言处理(第2版)》(宗成庆)
这本书我觉得写的不错。虽然我是语言学背景,但读起来也没有太吃力。它也是综论性质的,可以跳着看。
6)《统计学习方法》(李航)
自然语言处理需要些机器学习的知识。我数学基础还是太薄弱,有的内容还是有些吃力和困惑的。
7)《机器学习实战》哈林顿 (Peter Harrington)
《Python自然语言处理》
《集体智慧编程》
这些书都是python相关的。中间那本就是将NLTK的。网上都有电子版,需要的时候翻一番看一看就行。
视频篇:
@吴俣
上面提到的,斯坦福的nlp课程Video Listing,哥伦比亚大学的https://class.coursera.org/nlangp-001
,两个都是英文的,无中文字幕,现在还可以下载视频和课件。
另外超星学术视频:
1)自然语言理解_宗成庆
我觉得讲的还是不错的,第一次听的时候有些晕乎。该课程网上有ppt讲义。讲义后来被作者写成了书,就是上面提到的《统计自然语言处理》。拿着书就是教材,还有课程ppt和视频可以看,这种感觉还是很好的。
2)自然语言处理_关毅
感觉讲的一般,听了几节,跳跃太多,有时候让人摸不着头脑。多听听还是很有益处的吧。
3)计算语言学概论_侯敏
这个就是语言学内容为主了,作者也是语言学背景下在nlp比较活跃的。讲的很浅。老师讲课很啰嗦,说话太慢,我都是加速看的。
4)计算语言学_冯志伟
冯志伟老师这个课,一如他的著作,语言学和统计都会涉及到一些。冯志伟老师说话有些地方听不大清,要是有字幕就好了。
5)语法分析_陆俭明
这是纯语言学的课程。陆剑明也是当代语言学的大师。我觉得既然是自然语言处理,语言学的东西,还是多少要了解的。
其他篇:
1)博客的话,我爱自然语言处理专门记录nlp的,很不错,再有就是csdn上一些比较琐碎的了。
2)北京大学中文系 应用语言学专业这个刚开始的时候也看了看,又不少干货。
3)《中文信息学报》说这个,不会被大神喷吧。英语不佳,英文文献实在看的少。这个学报,也是挑着看看就行。
好像就是这些内容了。如果有,日后再补。虽然自己写了这么多,但不少书和视频都没有完整的看完。现在水平仍很菜,仍在进阶的路上。希望各路大神多多指点,该拍砖就拍吧。
编辑于 2014-12-19
​赞同 605​​26 条评论​分享
​收藏​喜欢​
收起​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

ZhangYi
一次只专注一件事
359 人赞同了该回答
这是一篇关于如何零基础自学NLP的长文~
本篇内容均属于个人观点,建议采纳对自己有用的经验,如有疏漏,欢迎指正,共同进步!⭐具体内容- 文本处理的常见操作
- AWESOME NLP
- 优秀的公开课/博客/书籍
- 文本相似度计算/词云图教程
- 你该知道哪些算法(传统/深度学习)
- 如何搭建一个智能问答框架
- 我是按照什么顺序学习的
文本处理的常见操作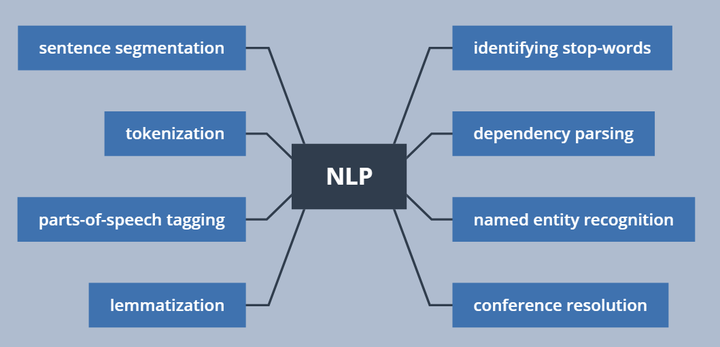
回顾一下人类是如何理解一段文字的,中英文的处理方式不同,以英文为例。一段话会被拆成一个个句子,一个句子又会被拆成一个个单词,根据单词在句子中的不同位置、单词的单复数、单词的时态等来理解。所以对文字进行分析的操作就很简单明了了。
sentence segmentation(断句)
一般根据标点符号即可进行断句操作。以下面的文本为例,可以分成四个句子。London is the capital and most populous city of England and the United Kingdom. Standing on the River Thames in the south east of the island of Great Britain, London has been a major settlement for two millennia. It was founded by the Romans, who named it Londinium. London's ancient core, the City of London, largely retains its 1.12-square-mile (2.9 km2) medieval boundaries.
tokenization(分词)
人类可以很快知道“我爱钞票。”里“我”是一个词,“爱”是另外一个,“钞票”是另外另外一个词。但是机器不知道,所以要做分词。相较于中文,英文比较容易辨识词的属性。英文的句子由一个个单词组成,单词之间以空格隔开,因此用空格作为分词的标记。“London is the capital and most populous city of England and the United Kingdom.”
上面这句话的分词结果如下,包含标点符号:“London”, “is”, “ the”, “capital”, “and”, “most”, “populous”, “city”, “of”, “England”, “and”, “the”, “United”, “Kingdom”, “.”
parts-of-speech tagging(词性标注)
词性标注是用来区分一个单词是动词/名词/形容词/副词等。(一度想起曾经被语法支配的恐惧 )这个词性标注的工作可以根据一个词性分类模型得出。
得出这句话中有名词、动词、限定词、连词、副词、形容词等。
lemmatization(词形还原)
虽说英语是最简单的语义,但是不同词性的单词的变行还是很多的,比如单复数、be动词变形、动词是现在进行时还是过去时等,都还原成最初的样子。
identifying stop-words(识别停用词)
像 “and”, “the”, “a”, “of”, “for” 这种哪里都高频出现会造成统计噪音的词,被称为stop words。下面灰色的“the”, “and”, “most”均为停用词,一般会被直接过滤掉。正如wiki里说明的,现在虽然停用词列表很多,但一定要根据实际情况进行配置。比如英语的the,通常情况是停用词,但很多乐队名字里有the这个词,The Doors, The Who,甚至有个乐队直接就叫The The!这个时候就不能看做是停用词了。
dependency parsing(解析依赖关系)
解析句子中每个词之间的依赖关系,最终建立起一个关系依赖树。这个数的root是关键动词,从这个关键动词开始,把整个句子中的词都联系起来。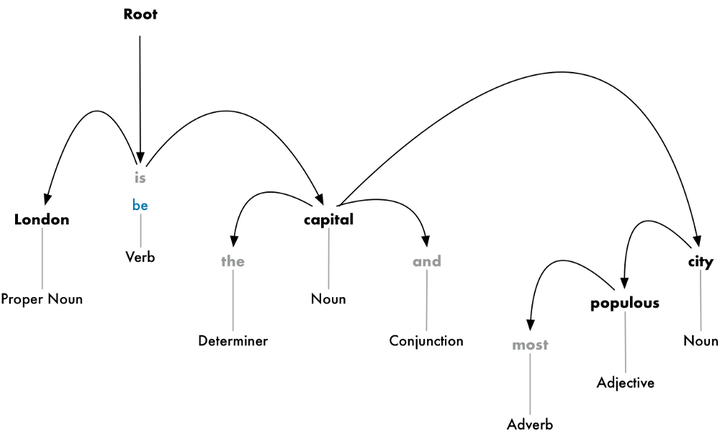
从这个关系树来看,主语是London,它和capital被be联系起来。然后计算机就知道,London is a capital。如此类推,计算机就被训练的掌握越来越多的信息。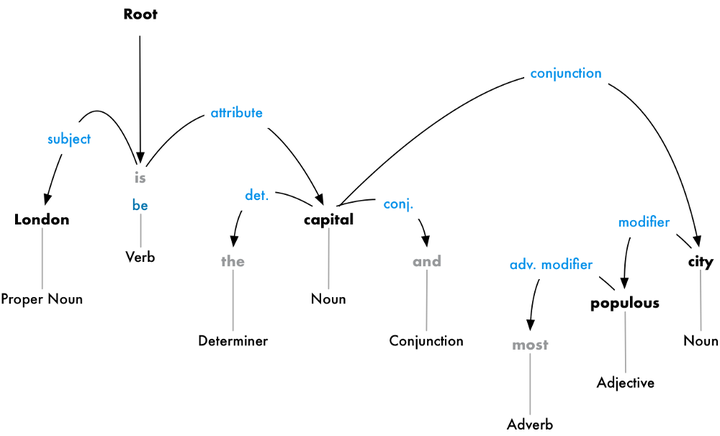
named entity recognition(命名实体识别)
来给名词打标签。比如我们可以把第一句话当中的地理名称识别出来。
conference resolution(共指消解)
指代词,比如他/她/它/这个/那个/前者/后者等。再比如缩写简称,北京大学通常称为北大,中华人民共和国通常就叫中国。这种现象,被称为共指现象。
注:部分笔记参考Adam Geitgey在medium的文章 Natural Language Processing is Fun!
⭐感兴趣的可以在 https://explosion.ai/demos/
里的第一个demo输入自己的文字进行进行尝试: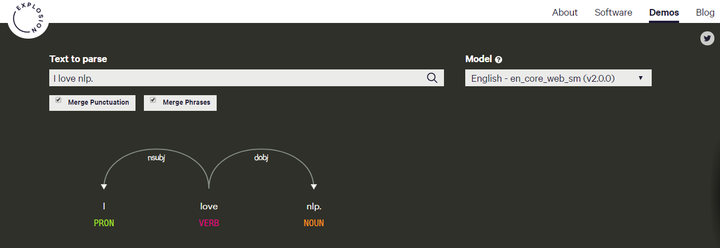
------------------------------------
上面介绍了对文本做处理的常见操作,接下来介绍在做文本匹配模型时的常见流程。
下图适合扭脖子观看: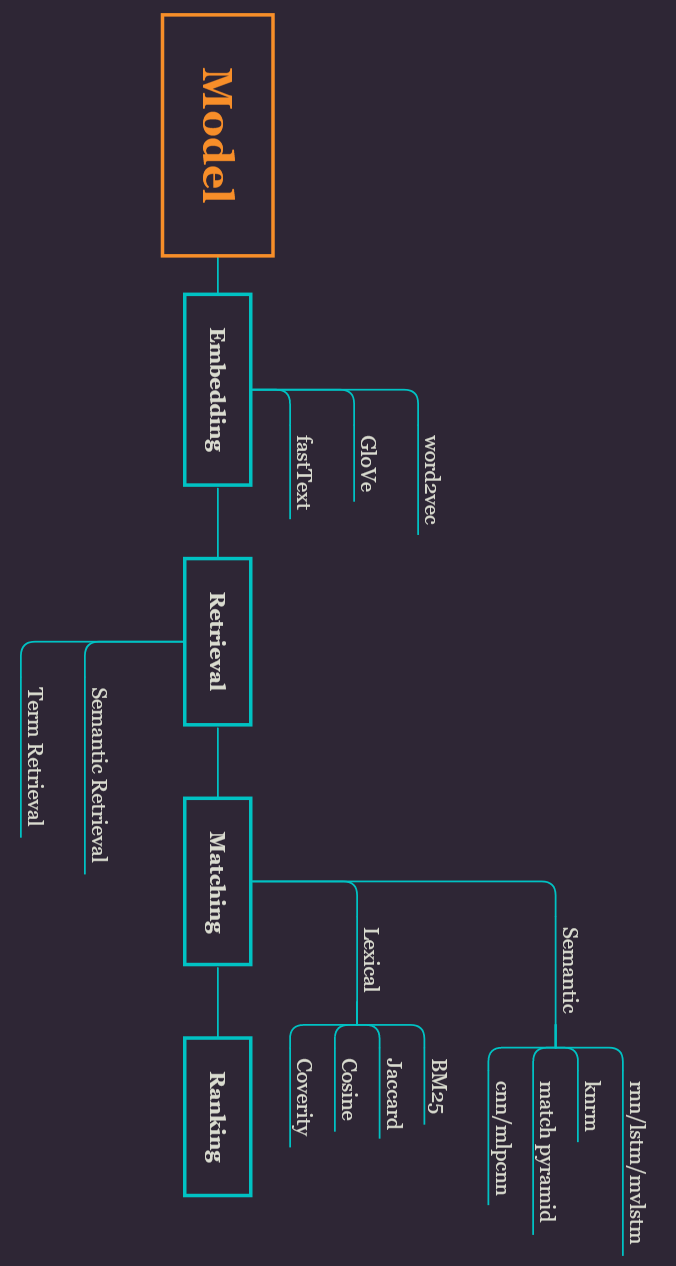
文本匹配是智能问答常用的一个功能。智能的应用就是语义匹配。根据意思来匹配,看两句话(或者多句话)说的是不是一个意思。比如“我想入门nlp。”和“如何学nlp技术?”可以认为是同一个意思,那么这两句话就匹配成功。传统的方法只是字字匹配(term matching),不会将“入门”和“学习”这两个匹配起来。再加一句“nlp的深度模型有哪些?”,明显和前两句不是一个意思,那么就匹配失败。语义匹配经常用在搜索引擎或像知乎问答上,你提问“如何学nlp技术?”,而“我想入门nlp”这个已经有人回答过了,存在知识库里,机器需要做的就是把你的问题与已有答案的问题匹配起来,把对应的答案传送给你。
Dictionary(字典)
像新华字典一样的存在,机器也需要有一个字典来理解文字。一个单词对应一个索引,这个索引index往往是一个序列ID一个整数。
Corpora(语料库)
字典是如何来的,自然是因为有很多很多的文字材料。语料可以是所有莎士比亚写的文章,或者所有维基百科的文章,或者一个特定的人发的推文。
Embedding(词/句/文本 嵌入)
通常是深度学习第一步,将文本转换成数字形式,这样才能丢进去训练。最常见的是 word embedding 词嵌入,将一个单词对应于一个ID,就像每个人都有一个身份证号码一样。
不要被中文的“嵌入”意思带偏。embedding是一个数学术语,代表的是一个映射关系。比如汉英字典里的中文“钞票”映射到英文就是单词“money”。这项技术把词汇表中的单词或短语映射成由实数构成的向量。在计算机中,一个单词映射到的往往就是它的索引数字。毕竟目前计算机也只能理解数字。目前最popular的embedding操作:BOW/word2vec/GloVe/fastText
Retrieval(召回)
把意思相同的信息从语料库/知识库中统统找出来。找出来的方式分为语义召回和词项召回。
比如我想在知乎上问“如何自学nlp?”,然后知乎在它的知识库里找到类似问题“零基础自学nlp”,“如何入门nlp”,“自学nlp难不难?”,“自然语言处理怎么入门?”这四个问题。最后一个问题应该是语义召回出来的,因为基本没一个字跟原问题一样,却是与原问题相似的意思。Matching(匹配)
判断两句话说的是不是一个意思。比如在知乎提问后,系统需要搜索出相关问题。但是召回出来相关问题可能有很多个,这就需要对每个问题的相似度进行打分了。比如“如何自学nlp?”召回出的4个问题的相似度分别是- “零基础自学nlp”:0.88
- “如何入门nlp”:0.91
- “自学nlp难不难?”:0.11
- “自然语言处理怎么入门?”:0.92
相似度匹配也分为语义匹配和词项匹配。Ranking(排序)
根据匹配相似度的分数进行相似问题的排序。排序结果如下:- “自然语言处理怎么入门?”:0.92
- “如何入门nlp”:0.91
- “零基础自学nlp”:0.88
- “自学nlp难不难?”:0.11
那么就把第一个问题的答案输出。也就回答了“如何自学nlp?”这个问题。
AWESOME NLP
这是一个你第一次打开会忍不住感叹出“Awwwwesome~!”的神器
sindresorhus/awesome
awesome-nlp只是awesome的一个子子...子集
keon/awesome-nlp
虽说是个子集,但awesome-nlp 包含优秀的nlp教程/库/技术/开源数据/模型等,必看!Contents- Research Summaries and Trends
- Tutorials
- Libraries(Node.js/Python/Java/Scala/R/...)
- Services
- Annotation Tools
- Datasets
- Implementations of various models
- NLP in Korean
- NLP in Arabic
- NLP in Chinese
- NLP in German
- NLP in Spanish
- NLP in Indic Languages
- NLP in Thai
- NLP in Vietnamese
- Other Languages
- Credits
NLP要用到python哪些包
1.spaCy https://explosion.ai/blog/
Python; emerging open-source library with fantastic usage examples, API documentation, and demo applications
这个库的链接博客值得看看,可以在上面的demo application上写自己的句子感受下语言是如何处理的,也可以尝试其他的demo和example,网站还是做的很用心的。
2.gensim radimrehurek.com/gensim/
Python library to conduct unsupervised semantic modelling from plain text
这个库可用来制作字典,做词嵌入word embedding练习,将文字转换为数字,生成向量。
3.jieba fxsjy/jieba
适用于中文的分词工具。支持繁体分词。支持自定义词典。支持三种分词模式:- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
4.Natural Language Toolkit (nltk)
Python; practical intro to programming for NLP, mainly used for teaching
公开课/博客/书籍
Stanford CS224n:
Natural Language Processing with Deep Learning
http://web.stanford.edu/class/cs224n/syllabus.html
Stanford CS224d:
Deep Learning for Natural Language Processing
http://cs224d.stanford.edu/syllabus.html
视频都可以在油管YouTube上搜到。
这门课在2016年之前叫做CS224d: Deep Learning for Natural Language Processing,之后改名为CS224n: Natural Language Processing with Deep Learning。上面的网址包含课程的讲义slides,suggested readings和课堂作业assignment。就像免费在斯坦福上学似的
如果是翻墙有困难的同学,也可以在b站搜索“CS224n”或“CS224d”,也有对应的课堂视频。尽量早点看,不要马住不看!
- Dan Jurafsky & Chris Manning
Natural Language Processing [入门视频系列]
优秀的博客- Deep Learning for NLP resources
andrewt3000/DL4NLP
有很丰富的资源,包括斯坦福、牛津大学等的NLP课程,深度学习在NLP领域的应用文章,比如情感分析、机器翻译、智能对话等。- natural language processing blog
https://nlpers.blogspot.com
- Language Log (Mark Liberman)
http://languagelog.ldc.upenn.edu/nll/
很有意思的一个小博客,每篇文章很短,很有趣,咬文嚼字的看待各国文字的小趣事。
https://ai.googleblog.com
The latest news from Google AI.
之前介绍python包spaCy的时候提到过。是spaCy作者经营的博客,还有其它小功能在一个个开发中。
我爱自然语言处理,中文博客。有对应的公众号和微博。
优秀的书籍- Speech and Language Processing (Daniel Jurafsky and James H. Martin)[classic NLP textbook that covers all the basics]
Speech and Language Processing- Foundations of Statistical Natural Language Processing (Chris Manning and Hinrich Schütze) [more advanced, statistical NLP methods]
Foundations of Statistical Natural Language Processing- Introduction to Information Retrieval (Chris Manning, Prabhakar Raghavan and Hinrich Schütze)[excellent reference on ranking/search]
Introduction to Information Retrieval- Neural Network Methods in Natural Language Processing (Yoav Goldberg)[deep intro to NN approaches to NLP, primer here]
文本相似度教程
文本相似度可以用来干嘛呢?
以延禧攻略为例,如果我的语料库是整个小说的话,当我输入“璎珞”时,可以科学的观察与璎珞关系最紧密的是弘历还是傅恒还是我们的白月光富察皇后。
下图为一个粗糙的版本结果,语料是从百度上复制粘贴的前20集左右的剧情文字,大家可以随意更改语料文字,最后得分结果如下:- 皇后:0.975189
- 皇上:0.964250
- 傅恒:0.964144
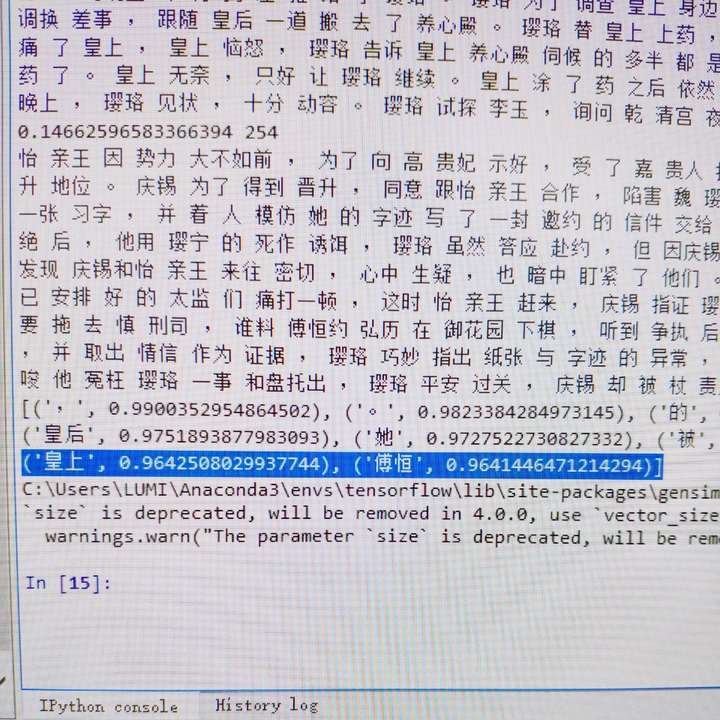 
看完与“璎珞”强相关的词后,也可以尝试看看“傅恒”,“皇上”的相关词。(还是心疼傅恒 )- 可以查看与“璎珞”最相关的前n个词语是什么
- 可以查看“璎珞”与“傅恒”的相似度有多少
同样,也可以把后面的剧情加进去,看看会发生什么变化
词云图 制作教程
词云图(wordcloud),是这两年比较火的文本可视化分析的一种。感觉这个很适合运营啊产品啊甚至行政做分析展示啥的~
词云图的制作其实非常简单,主要用到三个python库- jieba:用于中文分词
- wordcloud:用于词云图制作
- matplotlib:用于画图展示
简单到什么地步呢,就是10行代码搞定!
以爱丽丝梦游仙境的英文小说为例:from wordcloud import WordCloudf = open('data/alice.txt').read()wordcloud = WordCloud(background_color="white",width=1000, height=860, margin=2).generate(f) import matplotlib.pyplot as pltax = plt.imshow(wordcloud)fig = ax.figurefig.set_size_inches(25,20) plt.axis("off")plt.show()
其它的还可以根据你选定的图片进行词云形状的定制,词云颜色的定制等:  
下面是根据延禧攻略部分文字绘制的富察皇后的词云图
中文与英文还是有点不一样的,比如停用词表就需要自己弄一套。  
这里用到的文本分析的技术只停留在分词阶段,还是比较简单的。可视化分析永远是最吸引人的。快去试一下吧~
⭐具体教程在我的博客里有写。博客地址:codewithzhangyi.com
你该知道哪些算法
传统算法- 编辑距离:指两个字符串之间,由一个转成另一个所需的最少编辑操作次数
- 集合度量特征:基于BOW(bag of words),利用集合相似性度量方法,如Jaccard
- 统计特征:如句子长度、词个数、标点数量、标点类型、词性顺序等
- 词向量:将两个文本表示成同一向量空间中的向量,计算欧式距离、余弦相似度等
- 利用TF/IDF/LDA表示进行度量:如BM25文本相似度
其中基于特征的方法,效果很依赖特征的设计。基于传统检索模型的方法存在一个固有缺陷,就是检索模型智能处理Query与Document有重合词的情况,无法处理词语的语义相关性。
深度算法- Siamese Network
- DSSM(Deep Semantic Structured Model)
- CDSSM(Convolutional Deep Semantic Structured Model)
- ARC-I: Convolutional Neural Network Architectures for Matching Natural Language Sentences
- RNN(Recurrent Neural Networks)
- RNN变种:LSTM、Match-LSTM、Seq-to-Seq、Attention
- DeepMatch
- ARC-II
- MatchPyramid
- Match-SRNN
github上的nlp深度学习模型
⭐Awaresome Neural Models for Semantic Match
⭐Matchzoo
我是按什么顺序学nlp的
编辑于 2018-10-21
​赞同 359​​12 条评论​分享
​收藏​喜欢​
收起​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

腾讯云技术社区
​
人工智能话题下的优秀答主
56 人赞同了该回答
推荐这门《牛津大学xDeepMind 自然语言处理》视频课程给大家。
这门课程由牛津大学和谷歌DeepMind(AlphaGo的开发机构)联合开设,是牛津大学计算机系2017年春季学期最新课程。由Phil Blunsom主讲,同时邀请到多位来自DeepMind和NVIDIA的业界讲师来做客座讲座。
视频课程的主要内容包括:
1. 词向量与词汇语义学
2. 语言建模RNN
3. 文本分类
4. 英伟达:NLP硬件和软件
5. 条件语言模型
6. 注意力模型
7. 语音识别
8. 文本转语音
9. 智能问答(待更新)
10. 记忆与语言学(待更新)
以上视频课程均有中文字幕哦,更多相关课程欢迎到腾讯云学院学习。
搜索关注公众号「云加社区」,第一时间获取技术干货,关注后回复1024 送你一份技术课程大礼包!
发布于 2018-08-24
​赞同 56​​1 条评论​分享
​收藏​喜欢​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

把大象装冰箱
code in the hand, road in the way.
25 人赞同了该回答
通过个人入职一年以来的经历来说,感觉首先要对自然语言处理有一个比较清晰的理解。当然我从工业应用的觉度来说,理论的也并没有特别的深入。
一、自然语言处理是什么?
自然语言处理说白了,就是让机器去帮助我们完成一些语言层面的事情,典型的比如:情感分析、文本摘要、自动问答等等。我们日常场景中比较常见到的类似Siri、微软小冰之类的,这些的基础都是自然语言处理,另外还有一些语音处理,这就暂且不表了。总之,你看到的机器与人利用语言交互,用机器模拟人脑阅读,对话,评论等等这些的基础都是自然语言处理的范畴之内。
二、自然语言处理怎么学?
自然语言处理的实际入门步骤来说,假如单单从应用来说,我觉得还是直接先从简单的应用搞起更好一点,上来就是理论的话可能对一些人还是比较枯燥,我认为一个好的过程是:实践-理论-实践,先由实践搞起,加深兴趣,然后理论研究,深化理解,最后继续实践,知行合一。闲言少叙,下面说下自己的入门步骤:
1、分词
针对中文而言(当然假如你处理英文,可直接跳过这一步),首先就是分词的问题,因为中文相对于英文,并不是空格分隔的,另外进行自然语言处理的相关实践,也不大可能直接一长段文本进行操作,所以分词还是首当其中的。分词的原理暂且不说(比如CRF、霍夫曼等等,有兴趣可自己去了解),这里主要推荐一下常用到(Java)的几个分词工具:
(1)、HanLP 是一个中文自然语言处理的基础包,它囊括了包含分词在内的几乎所有的自然语言处理涉及的基础操作,同时工具包来说,分为data版和ptotable版,对于一般的分词而言,protable完全就可以满足要求。另外还有一些其他的操作,例如词性识别,也是实际应用中比较多的。当然其他的类似关键词提取,情感识别做个参考也就好了,实际还是要自己优化;
(2)、LTP 是哈工大的一个分词组件,相较于HanLP而言,其包含的依存句法分析以及语义依存分析的方法,对于我们基于文本进行更高级一点的操作(比如提取句子的主语、谓语;行动关系等,另外基于此进行分词优化实践也有一定的提升),可以说是比较方便的;但是与此同时,LTP提供分词的方式是利用http接口的方式,这就让它在实际的应用中有那么一点落后,虽然它也提供了自搭服务的方式,但也逃不出请求接口。最后的最后,貌似现在已经和讯飞合作了,开放接口都需要申请,而且还不一定能用。。允悲。
(3)、jieba 说起分词,就不得不提jieba,包括最基础的python版本,然后还有衍生出来的java版、C#版等等,实际使用起来也是比较方便,当然对于java版而言,它没有词性的功能,这也是我在实际应用中使用表少的一个原因吧。
另外,分词工具还有ansj、StanfordNLP中工具等等,用的不多也就不瞎说了。
2、关键词提取
对于中文文本而言,分词完毕,接下来我们要做的事情,大致逃不出那么几件:关键词提取、句子相似性、文本摘要等,这其中一个比较典型的应用就是关键词提取。相应的实践方式主要有以下几种:
(1)、TF-IDF 是关键词提取一个可以说是首先想到的解决方案,它说自己第二,没人敢说第一。当然它的理论也是比较好理解的,归结起来一句话:在一篇文本中那些不常出现(此处指的文本集)的词在当前文本中大量出现,那它就是关键词;TF、IDF也相应的就是两个概念,想看理论,查查便知;具体到应用层级来说,对于大量文本,语料比较丰富的场景下,这种方式提取关键词来说,确实也是比较方便和准确的,但在语料不足的情况下,可能也就just soso了。但是思想是最重要的,这也是我们入门的基础。
(2)、TextRank 是基于Google的PageRank的一个应用于文本的一个关键词提取算法,基于词语窗口的思想,利用相互投票的方式,提取文本关键词。TextRank有一个最大的好处就是不依赖额外文本,针对单篇文本,处理得当也就可以提取出看的过去的关键词,简单实用。关于其优化方式,比如改变词语网络窗口的大小,分词的预过滤,词性权重投票等等,都是一个不错的方向,效果也还算显著。其对应的实现都有开源的版本,GitHub上动动手就有了。
(3)、LDA 从严谨的角度而言,它并不是一个提取关键词的方式,但是对于我们预先有一定分类的文本而言,利用LDA提取文本的中心词,或者说针对类别的关键词,某些情况下效果也是不错的。具体到实现上,Java开源的有JGIbbLDA、当然python的scikit-learn,以及Spark Mllib中都包含了对应的LDA版本,可以一试。
具体到实际的使用场景,对于有大量语料,首推TF-IDF;对于单篇文本,当然还是TextRank;对于类别文本,LDA也不失为一种选择。总之,看你实际应用需求。
3、词向量
从关键词提取直接跳转到词向量,感觉是一个比较大的跳跃,但实际而言,词向量是我们后续进行机器学习或者深度学习的处理,因为机器处理的始终还是二进制,你不可能改变计算机底层的实现(当然说的是现在,没准后来有人就真成了呢,我们当那是一个美好的愿景吧)。词向量说白了,就是用向量的形式表示词,这就牵涉到一个问题了,我们怎么把一个中文词语转化成一个向量呢。这里主要有以下几种方式:
(1)、词袋模型,顾名思义就是把所有的词都放进一个袋子里,然后指定每个词的位置。所以这样生成的向量,就是长度等同于单词总数,尽在词对应的位置置1,其他位置均为0。这样你也应该能想到,实际应用而言,不太现实。
(2)、HashTF,对应词袋模型的困境,人们首先想到的就是怎么缩小向量的维度,同时表示相同的单词呢,HashTF的基本思想也就是为了解决这个问题,利用Hash的思想,将大量的单词映射到一个小维度向量中,来解读维度爆炸的问题,当然有利有弊,仍然不能很好的解决词语映射的问题。
(3)、Word2Vec是工业上比较常用的一个词向量模型工具,也是实际应用中采用的。其思想包括CBOW和Skip-Gram,基本思想都是词语和词语周围单词间的一个共现关系,它在一定程度上考虑了语境和语义的影响,是一个可以实际使用的工具。
概括来说,在我们后期利用机器学习或者深度学习处理问题的时候,词向量是我们必不可少的一步,word2vec也是我们可以考虑的一个比较不错的选择。
4、文本分类
文本分类是一个比较大的概念,具体到应用,其中包括了情感识别、敏感识别等,具体到实现方式,包括二类分类、多类别分类、多标签分类等。就是为了把一组文本按照指定要求利用机器进行区分。具体到实现算法而言,不胜枚举。。Spark Mllib中包含了大量的分类算法,可以进行实践,这也是入门的一种比较快速的方式,先会后懂然后深入。
5、自动问答
自动问答是一个比较热的概念,也是一个应用比较广泛的自然语言处理案例,当前业界最高水平R-Net已经可以达到80%多的准确率,已经是一个比较了不起的成就了,但是实际操作起来,也还是有一定难度,我也在不断摸索,暂时不瞎说了。
三、自然语言处理的深入
谈到自然语言处理的深入,这个可以做的就比较多了,上面列举的各个方面都与比较大的优化空间。但总体而言,最大的几个问题在于分词、词向量的转化以及文本特征的提取,这也是一定程序上困扰我们继续提高的几大阻碍。拿分词来说,无论是基于词典和算法的分词还是目前基于深度学习的分词方式,都只能说一定程度上进行分词实现,想要达到人脑的分词效果,实际上还是前路漫漫;词向量的转化在一定程序上也依赖于大量的语料,而我们也不可能在训练模型时囊括所有的词语,所有的语境,所有的文本,这些也都是不现实的,只能说时优化算法或者选择一种更好的方式;文本特征的提取也是一个我们在后期进行学习过程中一个绕不过去的坎。总而言之,自然语言处理说简单也简单,说难也难,就看你想要达到什么样的高度。
共勉!!
(文中说的不妥的地方,恳请交流,少拍砖,脑袋比较脆。。)
发布于 2018-05-06
​赞同 25​​3 条评论​分享
​收藏​喜欢​
收起​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

咸口锅包肉
深度学习、自然语言处理爱好者
37 人赞同了该回答
这么大牛介绍了如何从学术、技术方面入门,我以自己做过的文档分类来说一下如何入门。
请看文章 文档分类实战: 传统方法与深度学习问题描述
文档分类是指给定文档p(可能含有标题t),将文档分类为n个类别中的一个或多个,本文以人机写作为例子,针对有监督学习简单介绍传统机器学习方法和深度学习方法。 文档分类的常见应用:- 新闻的分类,也就是给新闻打标签,一般标签有几千个,然后要选取k个标签,多分类问题,可见2017知乎看山杯比赛,该比赛是对知乎的问题打标签;
- 人机写作判断,判断文章是人写的还是机器写的,二分类问题,可见CCF2017的360人机大战题目;
- 情感识别,例如判断豆瓣影评中的情感是正向、负向、中立,这个问题很常见而且应用场景很广泛;
传统机器学习模型
使用传统机器学习方法解决文档分类问题一般分为:文档预处理、特征提取、分类器选取、Adaboost多次训练的过程。文档预处理- 分词:中文任务分词必不可少,一般使用jieba分词,工业界的翘楚。
- 词性标注:在分词后判断词性(动词、名词、形容词、副词...),在使用jieba分词的时候设置参数就能获取。
- WORD—EMBEDDING:通过词与上下文、上下文与词的关系,有效地将词映射为低维稠密的向量,可以很好的表示词,一般是把训练和测试的语料都用来做word-embedding。可以把word-embedding作为传统机器学习算法的特征,同时也是深度学习方法必不可少的步骤(深度学习中单字和词的embedding都需要)。 本文使用Word2Vector实现Word Embedding,参数设置情况如下
- size=256 <Word Embedding的维度,如果是词的话一般设置为256,字的话设置为100就差不多,毕竟汉字数量为9w左右常用字7000左右>
- window=5, <滑动窗口的大小,词一般设置为5左右,表示当前词加上前后词数量为5,如果为字的话可以设置大一点>
- min_count=5, <最小词频,超过该词频的才纳入统计,字的话词频可以设置高一点>
- workers=15, <线程数量,加速处理>
- 分词、Word Embedding训练的代码如下,推荐使用pickle进行中间数据存储:
import pickleimport codecsimport jiebaimport multiprocessingimport codecsimport pandas as pdfrom gensim.models.word2vec import Word2Vectrain_file = "train.csv"test_file = "test.csv"train_file = codecs.open(train_file, 'r', 'utf-8')train_lines = train_file.readlines()test_file = codecs.open(test_file, 'r', 'utf-8')test_lines = test_file.readlines()label = []train_title = []train_content = []train_title_cut = []train_content_cut = []test_id = []test_title = []test_content = []test_title_cut = []test_content_cut = []print("Segment train title/content...")for i in range(len(train_lines)): if i % 10000 == 0: print(i) if len(train_lines.split('\t')) != 4: continue article_id, title, content, l = train_lines.split('\t') if 'NEGATIVE' in l: label.append(0) else: label.append(1) train_title.append(title) train_content.append(content) train_title_cut.append(' '.join(jieba.cut(title.strip('\n'), cut_all=False))) train_content_cut.append(' '.join(jieba.cut(content.strip('\n'), cut_all=False)))print("Segment train completed.")print("Segment test title/content...")for i in range(len(test_lines)): if i % 10000 == 0: print(i) if len(test_lines.split('\t')) != 3: continue article_id, title, content = test_lines.split('\t') test_id.append(article_id) test_title.append(title) test_content.append(content) test_title_cut.append(' '.join(jieba.cut(title.strip('\n'), cut_all=False))) test_content_cut.append(' '.join(jieba.cut(content.strip('\n'), cut_all=False)))print("Segment test completed.")pickle.dump(label, open('train_label.p', 'wb'))pickle.dump(train_title, open('train_title.p', 'wb'))pickle.dump(train_content, open('train_content.p', 'wb'))pickle.dump(train_title_cut, open('train_title_cut.p', 'wb'))pickle.dump(train_content_cut, open('train_content_cut.p', 'wb'))pickle.dump(test_id, open('test_id.p', 'wb'))pickle.dump(test_title, open('test_title.p', 'wb'))pickle.dump(test_content, open('test_content.p', 'wb'))pickle.dump(test_title_cut, open('test_title_cut.p', 'wb'))pickle.dump(test_content_cut, open('test_content_cut.p', 'wb'))corpus = train_title_cut + train_content_cut + test_title_cut + test_content_cutclass CorpusData: def __init__(self, corpus): self.corpus = corpus def __iter__(self): for doc in corpus: origin_words = doc.split(' ') yield origin_wordsprint("Train word to vector...")corpus_data = CorpusData(corpus)model = Word2Vec(corpus_data, size=256, window=5, min_count=5, workers=15)model.save('w2v_model_s256_w5_m5.save')print("Train w2v completed.")
特征提取
可以说提取的特征决定了整个任务分数的上限,强的或者说敏感的特征对文档分类有及其大的影响,而弱特征的组合有时候也能发挥意向不到的效果,提取过程一般是选取文档的常规特征、针对具体任务设计的特征、对特征的强度计算和筛选。常规特征- TF-IDF:词频-逆文档频率,用以评估词对于一个文档集或一个语料库中的其中一个文档的重要程度,计算出来是一个DxN维的矩阵,其中D为文档的数量,N为词的个数,通常会加入N-gram,也就是计算文档中N个相连词的的TF-IDF。一般用sklearn的库函数计算,具体用法详见sklearn.feature_extraction.text.TfidfVectorizer。在人机写作判断的问题来看,TF-IDF是很强的一个特征。
- LDA(文档的话题):可以假设文档集有T个话题,一篇文档可能属于一个或多个话题,通过LDA模型可以计算出文档属于某个话题的概率,这样可以计算出一个DxT的矩阵。LDA特征在文档打标签等任务上表现很好。
- LSI(文档的潜在语义):通过分解文档-词频矩阵来计算文档的潜在语义,和LDA有一点相似,都是文档的潜在特征。
- 词性的TD—IDF:以词的词性表示词,再次计算其tf-idf,由于词性种类很有限,矩阵比较小。
针对具体任务设计特征
本文是以人机写作判断为例子,为此设计了以下特征,其中每种特征都选取最大值、最小值、平均值、中位数、方差:- 句子长度:文档短句之后,统计句子长度;
- 标点数:文档断句之后,每个句子中的标点个数
- jaccard相似度:分词后的每个句子与分词后的标题的jaccard距离;
- 重复句子:文档中是否有重复句子
- 英文、数字个数:断句后句子中的英文、数字个数
特征的强度计算和筛选
我们要尽可能选取任务敏感的特征,也就是特征足够强可以影响分类的结果,一般用树模型判断特征的重要程度,xgboost的get_fscore就可以实现这一功能。计算特征强度之后,选取较强的特征,摒弃弱特征。可以尝试组合不同的特征来构造新的特征,然后测试新特征的强弱,反复如此获取更多的强特征。分类器选取
特征提取相当于构造了一个DxF的矩阵,其中D为文档数量,F为特征数量,一篇文档用N维空间上的一个点表示,成为一个数学问题:如何将点分类。机器学习中的一个重要问题就是分类,相对回归问题来说分类问题更加简化、模糊、不确定,往往因为不能设计定量的回归问题而设计成分类问题,例如以前天气预报给的结果是60%的概率降雨,现在可以给出70%的概率降雨100ml的结果,就是随着计算能力的提高的计算技术的发展讲分类问题转换为回归问题。前人给我留下了诸如朴素贝叶斯、逻辑回归、SVM、决策树、神经网络等分类算法,sklearn等机器学习库将其封装为简单容易上手的API,供我们选择。- 朴素贝叶斯:以前很多人拿到数据就会马上用朴素贝叶斯验证一下数据集,但是往往由于各个特征不是独立同分布的所以朴素贝叶斯的效果一般不好,但是也可以尝试一下,如果效果不错作为最后模型融合的一个模型。针对人机写作判断的任务来说效果太差了,就没有记录。
- 逻辑回归:用来解决回归问题的方法,分类问题可以看做回归问题的特例,也能尝试用此方法。但是结果和朴素贝叶斯差不多的样子。
- SVM:在神经网络火起来之前,可以说SVM撑起了一半分类问题的解决方案,SVM的想法很质朴:找出两类点之间的最大间隔(也包括软间隔,即间隔中有样本点)把样本点分类。但是在人机写作判断的问题上,SVM的表现也不好。
- 树模型:树结构很适合文档分类,我主要使用LightGBM模型对文档进行分类,其中调参的经验是树的深度不要太深、让树尽可能矮宽,这样分类比较充分,一般深度为4~6就行。树模型的调参是一件很痛苦的事情,推荐基于贝叶斯优化的调参方法。有熟悉XGBoost的同学也可以尝试,但是总体来说LGB比XGB速度要快好几倍更适合验证特征以及调参。人机写作任务中,第一批数据是10w训练+5w测试数据,LGB在这个数据集上表现很优秀,单模型就接近0.9了,但是由于后期60w训练+40w测试数据,LGB的性能明显下降,而且怎么调参优化都不起作用。
Adaboost多次训练
这是我和队友针对人机写作判断问题,根据Adaboost算法设计的一个小Trick。如果每次分类结果中,把大量的负样本分为正样本,或者大量负样本分为正样本,就根据正样本和负样本的错误率调整正负样本的权重,例如正负样本的错误率分别为P(正)、P(负),当前权重分别为W(正)、W(负),则根据以下方式调整:W(正) = P(正)+ [1 - abs(P(正) + P(负)) / 2]W(负) = P(负)+ [1 - abs(P(正) + P(负)) / 2]
根据这种动态调整权重的方法,可以充分发挥树模型在分类问题上的优势。小结
新数据发放之后,树模型的能力明显降低,在训练集都达不到0.7的F1值,我在费力捣鼓树模型时候,队友已经开始尝试深度学习的模型,明显优于传统机器学习模型,分数在0.84以上。而且传统机器学习方法中的特征提取环节太过费时费力,而且经常很不讨好。建议刚接触文档分类或者其他机器学习任务,可以尝试传统的机器学习方法(主要是统计学习方法),可以体验一下这几个过程,但是如果想去得好成绩最好还是尝试深度学习。深度学习模型
深度学习模型的重点是模型的构建和调参,相对来说任务量能小不少。RNN、LSTM等模型由于拥有记忆能力,因而在文本处理上表现优异,但是缺点很明显就是计算量很大,在没有GPU加速情况下,不适合处理大批的数据,CNN在FaceBook的翻译项目上大放异彩也表明CNN在文本处理领域上的重要性,而且相对RNN来说,速度明显提升。本文尝试了多层CNN、并行CNN、RNN与CNN的结合、基于Hierarchical Attention的RNN、迁移学习、多任务学习、联合模型学习。在单模型和联合模型学习上,我们复现、借鉴了2017知乎看山杯比赛第一名的方案,在此表示感谢。深度学习部分代码都是使用Keras框架实现的,Keras搭建模型非常方便适合快速验证自己的想法和模型。文本预处理
分词、Word Embedding已经介绍过,一般文本内容输入到神经网络作为Input,要先进行Tokenizer,然后对空白部分做padding,并且获得Word Embedding的emnedding_matrix其中Tokenizer、padding都是使用Keras自带的API,因为我刚开始使用深度学习处理文本时候这个过程不是很明白,就分享一下代码,具体过程如下:from keras.preprocessing.text import Tokenizerfrom gensim.models.word2vec import Word2Vecmax_nb_words = 100000 #常用词设置为10wtokenizer = Tokenizer(num_words=max_nb_words, filters='')tokenizer.fit_on_texts(train_para_cut) #使用已经切分的训练语料进行fitword_index = tokenizer.word_indexvocab_size = len(word_index)model = Word2Vec.load(w2v_file) #Load之前训练好的Word Embedding模型word_vectors = model.wvembeddings_index = dict()for word, vocab_obj in model.wv.vocab.items(): if int(vocab_obj.index) < max_nb_words: embeddings_index[word] = word_vectors[word]del model, word_vectorsprint("word2vec size: {}".format(len(embeddings_index)))num_words = min(max_nb_words, vocab_size)not_found = 0embedding_matrix = np.zeros((num_words+1, w2v_dim)) # 与训练好的,神经网络Embedding层需要用到for word, i in word_index.items(): if i > num_words: continue embedding_vector = embeddings_index.get(word) if embedding_vector is not None: embedding_matrix = embedding_vector else: not_found += 1print("not found word in w2v: {}".format(not_found))print("input layer size: {}".format(num_words))print("GET Embedding Matrix Completed")train_x = tokenizer.texts_to_sequences(train_content_cut)train_x = pad_sequences(train_x, maxlen=max_len, padding="post", truncating="post")test_x = tokenizer.texts_to_sequences(test_content_cut)test_x = pad_sequences(test_x, maxlen=max_len, padding="post", truncating="post")
必要的数据统计
一篇文档及其标签作为神经网络的一个输入,经Tokenizer之后,需要设置定长的输入,必须统计文档长度、句子数、句子长度、标题长度,推荐使用pandas进行统计,方便简洁。就人机写作判断任务的数据统计情况如下:Label on train:NEGATIVE 359631POSITIVE 240369Content length on train OSITVE:count 240369.000000mean 1030.239369std 606.937210min 2.00000025% 554.00000050% 866.00000075% 1350.000000max 3001.000000NEGATIVE:count 359631.000000mean 1048.659999std 607.034089min 186.00000025% 574.00000050% 882.00000075% 1369.000000max 3385.000000Content length on test:count 400000.000000mean 1042.695075std 608.866342min 136.00000025% 567.00000050% 877.00000075% 1362.000000max 4042.000000Sentence number on traincount 600000.000000mean 64.429440std 43.248348min 2.00000025% 33.00000050% 53.00000075% 85.000000max 447.000000 OSITVE:count 240369.000000mean 1030.239369std 606.937210min 2.00000025% 554.00000050% 866.00000075% 1350.000000max 3001.000000NEGATIVE:count 359631.000000mean 1048.659999std 607.034089min 186.00000025% 574.00000050% 882.00000075% 1369.000000max 3385.000000Content length on test:count 400000.000000mean 1042.695075std 608.866342min 136.00000025% 567.00000050% 877.00000075% 1362.000000max 4042.000000Sentence number on traincount 600000.000000mean 64.429440std 43.248348min 2.00000025% 33.00000050% 53.00000075% 85.000000max 447.000000
设想差不多2个字1个词,分完词后句子词数最大不超过2000,神经网络的Input length可以设置为2000,文档句子数设为100,句子长度设为50,最够覆盖绝大部分文档。正文与标题
文档分为正文和标题两部分,一般两部分分开处理,可以共享Embedding层也可以不共享,人机写作分类问题中我们没有共享Embedding。正文多层CNN,未使用标题
CNN需要设置不同大小的卷积核,并且多层卷积才能较好的捕获文本的特征,具体网络结构如下:
正文 CNN Inception,未使用标题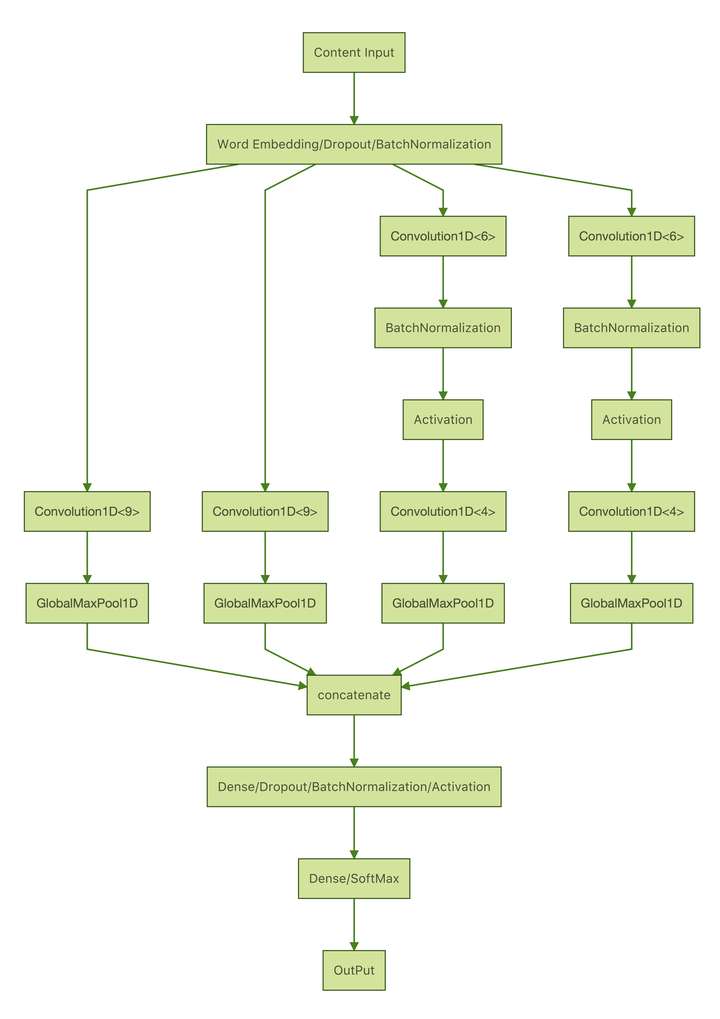
RCNN处理正文,多层CNN处理标题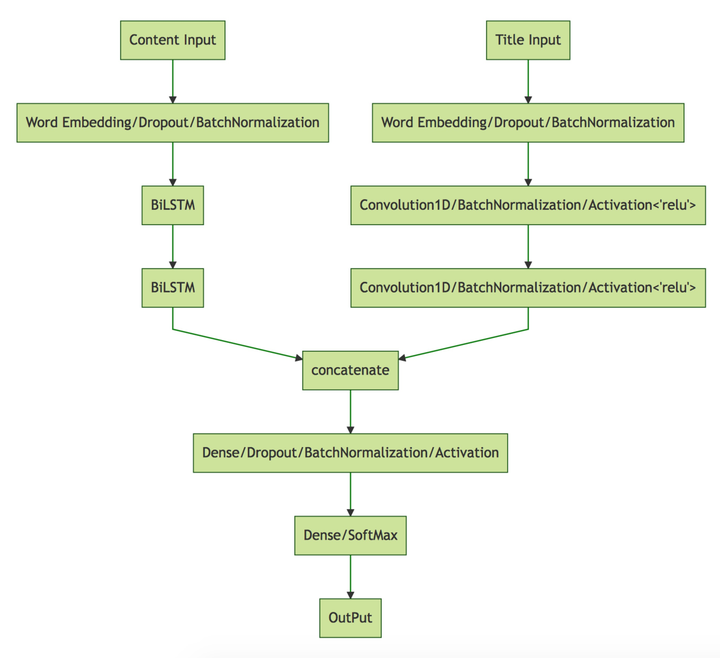
基于Hierarchical Attention的RNN处理正文
模型是根据论文《Hierarchical Attention Networks for Document Classification》实现的,论文中的模型如下
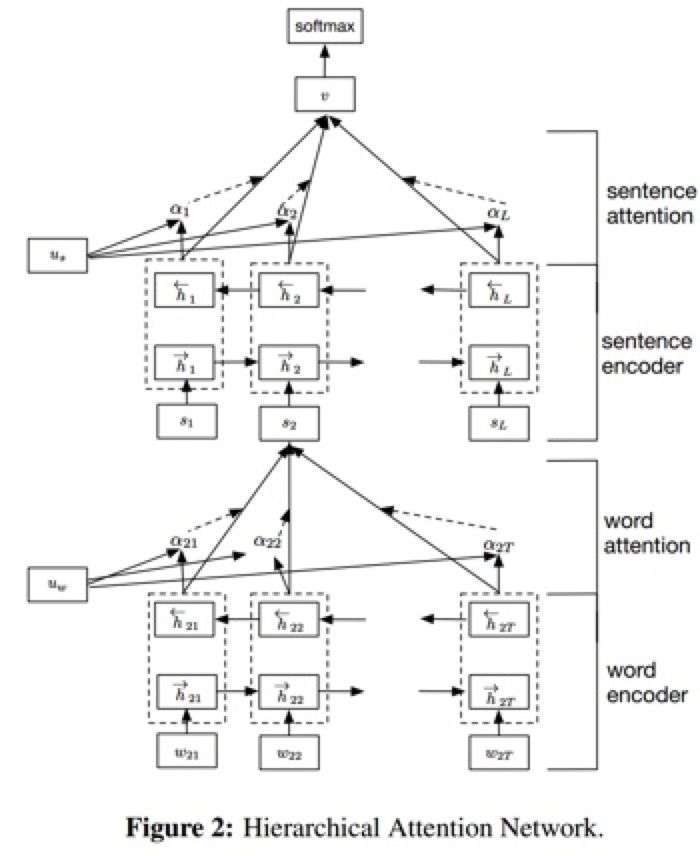
具体实现过程中的网络结构如下: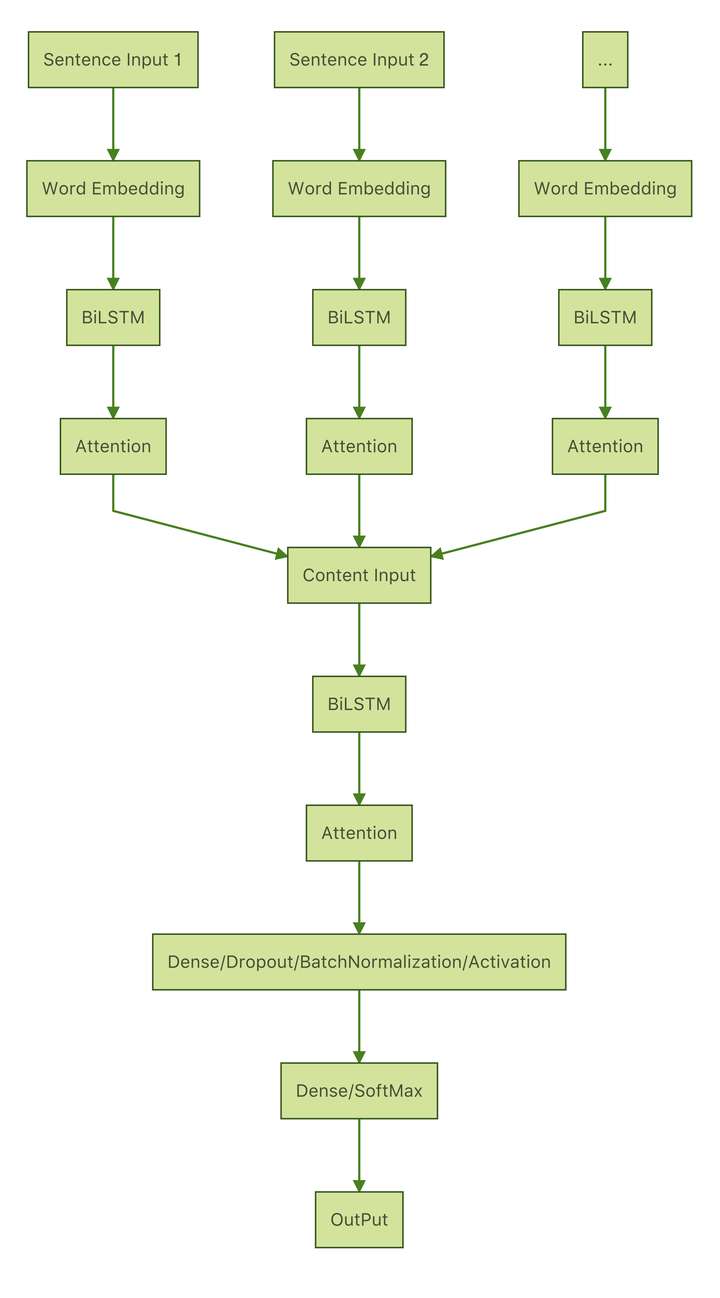
迁移学习
设计模型M,M在数据集A上训练到最佳效果保存模型的权重,然后再使用训练好的M在数据集B上训练,这个过程可以看做简单的迁移学习。因为人机写作判断任务中,先后有两个数据集,早期数据可以看做A,后期也就是最终的数据看做B,而模型在A上的表现比B上要好很多,这样就可以使用迁移学习来使模型在B上表现也好。 我们是使用RCNN处理正文,多层CNN处理标题这个模型来实现迁移学习的,具体过程如下: 多任务学习 多任务学习
相同模型同时在数据集A和B上训练,可以称为多任务学习,我们也是使用RCNN处理正文,多层CNN处理标题这个模型来实现多任务学习的,具体过程如下:
联合模型学习
选取表现最好的2个单模型,在数据集上预训练到最优,然后联合在一起训练,可以共享Embedding层,也可以不共享,由于我们表现最好的单模型是RCNN处理正文,多层CNN处理标题的Model A和基于Hierarchical Attention的RNN的Model B,Embedding的形式不同所以不能共享,具体形式如下所示,也可以联合多个单模型一起训练,但缺点就是训练时间过长: 小结 小结
深度学习在文档分类问题上比传统机器学习方法有太大的优势,仔细分析就知道文本的特征很难提取,而且这些特征不能很好的表示文档的语义、语法,丢失了很大一部分的有用信息,而深度学习就是将特征提取这个环节交给深度网络去自动完成,通过更高的计算成本换取更全面更优良的文本特征。模型Stacking
一般是针对评测或者比赛,融合多个模型的结果,不同的模型会导致其预测结果的多样性,Stacking可以有效的融合其多养性达到提高分数的目的。关于Stacking的介绍,可以看这篇文章。 传统Stacking方法一般使用树模型,例如LightGBM、XGBoost等,我们使用神经网络的方式实现,Model就是两个全连接层。总结
传统机器学习方法可以作为任务的Baseline,而且通过特征的设计和提取能够感受数据,不能把数据也就是文档看做黑盒子,对数据了解足够设计模型肯定事半功倍。至于深度学习的方法,我们只是借鉴、改进经典论文提出的模型,也使用了前人比赛的Trick,如果想深入了解还是需要阅读更多的论文,ACL是计算语言学年会汇集了全球顶尖NLP领域学者的思想,可以关注这个会议阅读其收录的论文。引用- Kim Y. Convolutional Neural Networks for Sentence Classification[J]. Eprint Arxiv, 2014.
- Yang Z, Yang D, Dyer C, et al. Hierarchical Attention Networks for Document Classification[C]// Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2017:1480-1489.
- https://zhuanlan.zhihu.com/p/28923961
- https://zhuanlan.zhihu.com/p/25928551
末尾再贴一下原文 文档分类实战: 传统方法与深度学习
编辑于 2017-12-13
​赞同 37​​1 条评论​分享
​收藏​喜欢​
收起​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

人邮异步社区
官方微信:异步社区,人民邮电出版社旗下IT专业图书旗舰社区
4 人赞同了该回答
自然语言处理是计算机科学和人工智能(artificial intelligence,AI)的一个研究领域,它关注自然语言(如英语或汉语普通话)的处理。这种处理通常包括将自然语言转换成计算机能够用于理解这个世界的数据(数字)。同时,这种对世界的理解有时被用于生成能够体现这种理解的自然语言文本(即自然语言生成)。
如果你是Python和自然语言处理的新手,那么异步君推荐您阅读《自然语言处理实战》的第一部分。- 第1章 NLP概述
- 第2章 构建自己的词汇表——分词
- 第3章 词中的数学
- 第4章 词频背后的语义
第一部分会介绍一些来自真实世界的应用,从而开启大家的自然语言处理(Natural Language Processing,NLP)“冒险之旅”。
在第1章中,我们将很快开始思考一个问题:如何在自己的生活中使用机器来处理文字?希望大家能感受到机器的魔力——它具备从自然语言文档的词语中收集信息的能力。词语是所有语言的基础,无论是编程语言中的关键字还是孩提时代学到的自然语言词语都是如此。
在第2章中,我们将会提供一些可以教会机器从文档中提取词语的工具。这类工具比想象的要多得多,我们将展示其中所有的技巧。大家将学会如何将自然语言中的词语自动聚合成具有相似含义的词语集合,而不需要手工制作同义词表。
在第3章中,我们将对这些词语进行计数,并将它们组织成表示文档含义的向量。无论文档是140字的推文还是500页的小说,我们都可以使用这些向量来表示整篇文档的含义。
在第4章中,我们会学到一些久经考验的数学技巧,它们可以将前面的向量压缩为更有用的主题向量。
到第一部分结束时,读者将会掌握很多有趣的NLP应用(从语义搜索到聊天机器人)所需的工具。
现在异步君带您看下第一部分都有哪些您所要学习的知识?1、NLP概述
主要内容- 自然语言处理(NLP)的概念
- NLP的难点以及近年来才开始流行的原因
- 词序和语法重要或可以忽略的时机
- 如何利用多个NLP工具构建聊天机器人
- 如何利用正则表达式初步构建一个微型聊天机器人
我们即将开启一段激动人心的自然语言处理(NLP)冒险之旅!首先,本章将介绍NLP的概念及其应用场景,从而启发大家的NLP思维,不论你是在工作还是在家,都能够帮助大家思考生活中的NLP使用之道。
然后,我们将深入探索细节,研究如何使用Python这样的编程语言来处理一小段英文文本,从而帮助大家逐步构建自己的NLP工具箱。在本章中,读者将会编写自己的第一个可以读写英语语句的程序,该Python代码片段将是学习“组装”英语对话引擎(聊天机器人)所需所有技巧的第一段代码。
NLP流水线中的示例层图解[img=1067,758][/img]" data-caption="" data-size="normal" data-rawwidth="1067" data-rawheight="758" data-default-watermark-src="https://pic2.zhimg.com/50/v2-acc0d00c2551ab5fe76f874bf66c663e_hd.jpg?source=1940ef5c" class="origin_image zh-lightbox-thumb lazy" width="1067" data-original="https://pic1.zhimg.com/v2-cf56480005f8ec0de8ea71ba62f2eab9_r.jpg?source=1940ef5c" data-actualsrc="https://pic1.zhimg.com/50/v2-cf56480005f8ec0de8ea71ba62f2eab9_hd.jpg?source=1940ef5c">
2、构建自己的词汇表——分词
主要内容- 将文本切分成词或n-gram(词条)
- 处理非标准的标点符号和表情符号(如社交媒体帖子上的表情符号)
- 利用词干还原和词形归并方法压缩词汇表
- 构建语句的向量表示
- 基于手工标注的词条得分构建情感分析工具
本章将帮助大家将文档或任何字符串拆分为离散的有意义的词条。这里说的词条仅限于词、标点符号和数值,但是这里使用的技术可以很容易推广到字符序列包含的任何其他有意义的单元,如ASCII表情符号、Unicode表情符号和数学符号等。
从文档中检索词条需要一些字符串处理方法,这些方法不仅仅限于第1章使用的str.split()。处理时需要把标点符号(如语句前后的引号)与词分开,还需要将“we’ll”这样的缩写词还原成原始词。一旦从文档中确定好要加入词汇表中的词条之后,需要使用正则表达式工具来将意义相似的词合并在一起,这个过程称为词干还原(stemming)。然后,大家就可以将文档表示成词袋向量,我们可以尝试一下看看这些向量是否能够提高第1章末尾提到的问候语识别器的能力。
考虑一下一个词或词条对大家到底意味着什么。它到底表示单个概念?还是一些模糊概念的混杂体?大家是否能够确信自己总能认识每个词?自然语言的词是否像编程语言中的关键字一样具有精确的定义和一套语法使用规则?大家能否编写出能够识别词的软件?对大家来说,“ice cream”到底是一个词还是两个词?它在大家的头脑当中难道不是有两个词ice和cream,并且这两个词与复合词“ice cream”完全独立吗?对于缩写“don’t”又该如何处理?这个字符串到底应该拆分成单个意义单元还是两个意义单元?
另外,词可以再分成更细粒度的意义单元。词本身可以分为更小的有意义部分。诸如“re”“pre”和“ing”之类的音节、前缀和后缀都有其内在含义。词的各组成部分还可以进一步分成更细粒度的意义单元。字母或语义图符(grapheme)也承载着情感和意义[1]。
我们将在后面的章节中讨论基于字符的向量空间模型。但现在我们先试着解决词是什么以及如何将文本切分成词这两个问题......3、词中的数学
主要内容- 对词和词项频率计数来分析文档意义
- 利用齐普夫定律预测词的出现概率
- 词的向量表示及其使用
- 利用逆文档频率从语料库中寻找相关文档
- 利用余弦相似度和Okapi BM25公式计算文档间的相似度
我们已经收集了一些词(词条),对这些词进行了计数,并将它们归并成词干或者词元,接下来就可以做一些有趣的事情了。分析词对一些简单的任务有用,例如得到词用法的一些统计信息,或者进行关键词检索。但是我们想知道哪些词对于某篇具体文档和整个语料库更重要。于是,我们可以利用这个“重要度”值,基于文档内的关键词重要度在语料库中寻找相关文档。
这样做的话,会使我们的垃圾邮件过滤器更不可能受制于电子邮件中单个粗鲁或者几个略微垃圾的词。也因为有较大范围的词都带有不同正向程度的得分或标签,因此我们可以度量一条推文的正向或者友好程度。如果知道一些词在某文档内相对于剩余文档的频率,就可以利用这个信息来进一步修正文档的正向程度。在本章中,我们将会学习一个更精妙的非二值词度量方法,它能度量词及其用法在文档中的重要度。几十年来,这种做法是商业搜索引擎和垃圾邮件过滤器从自然语言中生成特征的主流做法。
下一步我们要探索将第2章中的词转换成连续值,而非只表示词出现数目的离散整数,也不只是表示特定词出现与否的二值位向量。将词表示为连续空间之后,就可以使用更令人激动的数学方法来对这些表示进行运算。我们的目标是寻找词的数值表示,这些表示在某种程度上刻画了词所代表的信息内容或重要度。我们要等到在第4章中才能看到如何将这些信息内容转换成能够表示词的意义的数值。
本章将会考察以下3种表示能力逐步增强的对词及其在文档中的重要度进行表示的方法:- 词袋——词出现频率或词频向量;
- n-gram袋——词对(2-gram)、三元组(3-gram)等的计数;
- TF-IDF向量——更好地表示词的重要度的得分。
重要说明
TF-IDF表示词项频率(term frequency)乘以逆文档频率(inverse document frequency)。在上一章中我们曾经学到过,词项频率是指每个词在某篇文档中的出现次数。而逆文档频率指的是文档集合中的文档总数除以某个词出现的文档总数。
上述3种技术中的每一种都可以独立应用或者作为NLP流水线的一部分使用。由于它们都基于频率,因此都是统计模型。在本书的后面部分,我们会看到很多更深入观察词之间关系、模式和非线性关系的方法。
但是,这些浅层的NLP机器已经很强大,对于很多实际应用已经很有用,例如垃圾邮件过滤和情感分析。4、词频背后的语义
主要内容- 分析语义(意义)以构建主题向量
- 利用主题向量之间的相似度来进行语义搜索
- 大规模语料库上可扩展的语义分析及语义搜索
- 在NLP流水线中将语义成分(主题)用作特征
- 高维向量空间的处理
到目前为止,大家已经学会了不少自然语言处理的技巧。但现在可能是我们第一次能够做一点儿神奇工作的时机。这也是我们第一次谈到机器能够理解词的意义。
第3章中的TF-IDF向量(词项频率-逆文档频率向量)帮助我们估算了词在文本块中的重要度。我们使用了TF-IDF向量和矩阵来表明每个词对于文档集合中一小段文本总体含义的重要度。
这些TF-IDF“重要度”评分不仅适用于词,还适用于多个词构成的短序列(n-gram)。如果知道要查找的确分词或n-gram,这些n-gram的重要度评分对于搜索文本非常有用。
过去的NLP实验人员发现了一种揭示词组合的意义的算法,该算法通过计算向量来表示上述词组合的意义。它被称为潜在语义分析(latent semantic analysis,LSA)。当使用该工具时,我们不仅可以把词的意义表示为向量,还可以用向量来表示整篇文档的意义。
在本章中,我们将学习这些语义或主题向量[1]。我们将使用TF-IDF向量的加权频率得分来计算所谓的主题得分,而这些得分构成了主题向量的各个维度。我们将使用归一化词项频率之间的关联来将词归并到同一主题中,每个归并结果定义了新主题向量的一个维度。
这些主题向量会帮助我们做很多十分有趣的事情。它们使基于文档的意义来搜索文档成为可能,这称为语义搜索。在大多数情况下,语义搜索返回的搜索结果比用关键词搜索(TF-IDF搜索)要好得多。有时候,即使用户想不出正确的词来进行查询,语义搜索返回的也正是他们所需要的文档。
同时,我们可以使用这些语义向量来识别那些最能代表语句、文档或语料库(文档集合)的主题的词和n-gram。有了这个词向量和词之间的相对重要度,我们就可以向用户提供文档中最有意义的词,即那些能够概括文档意义的一组关键词。
现在,我们可以比较任意两个语句或文档,并给出它们在意义上的接近程度。提示
术语topic、semantic和meaning具有相似的含义,在讨论NLP时往往可以互换使用。在本章中,我们将学习如何构建一个NLP流水线,它可以自己找出这类同义词。该流水线甚至可以找到短语“figure it out”和词“compute”在意义上的相似性。当然,机器只能“计算”意义,而不能“理解”意义。
大家很快就会看到,构成主题向量每一维的词的线性组合是非常强大的意义表示方法。
看到这里是否感觉这本书的学习路线很适合你?
为什么我会推荐您来阅读这本书入门自然语言处理?《自然语言处理实战 利用Python理解、分析和生成文本(异步图书出品)》([美]霍布森·莱恩,科尔·霍华德,汉纳斯·马克斯·哈普克)【摘要 书评 试读】- 京东图书​item.jd.com
- Python和NLP新手
按部就班阅读,构建从基础理论到实际应用的完整知识体系。 - 具有中等水平Python编程技能并对机器学习有基本了解的读者
以本书为参考,了解NLP理论并动手实战。 - 已经能够设计和构建系统的专业人士
参考本书的众多实战示例,深入理解先进的NLP算法的功能。
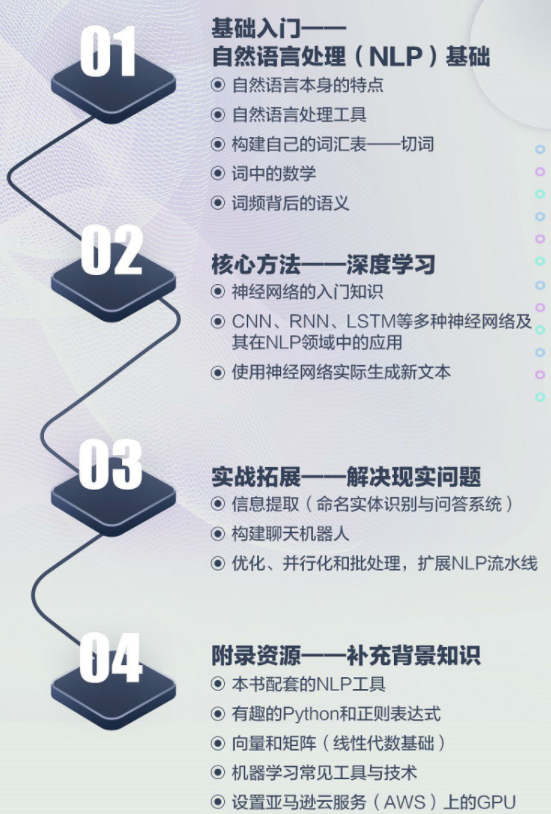
第一部分入门路线阅读完给大家分享一部分第五章干货。第5章 神经网络初步(感知机与反向传播)
本章主要内容- 神经网络的历史
- 堆叠感知机
- 反向传播算法
- 初识神经网络
- 用Keras实现一个基本的神经网络
近年来,围绕神经网络前景的新闻频频出现,起初它们主要针对神经网络对于输入数据进行分类和识别的能力进行报道,最近几年来有关特定神经网络结构生成原创性内容的报道也不断出现。大大小小的公司都在使用神经网络,并将其应用于各种领域,从图像描述生成、自动驾驶车载导航,到卫星图像中的太阳能电池板检测,以及监控视频中的人脸识别。幸运的是,神经网络也被应用于NLP领域。虽然深度神经网络引发了大量的关注,但机器人统治世界可能比所有标题党所说的还要遥远。然而,神经网络确实非常强大,大家可以轻易地使用它来完成NLP聊天机器人流水线里的输入文本分类、文档摘要甚至小说作品生成任务。
本章旨在作为神经网络初学者的入门知识。在本章中,我们不局限于NLP领域的内容,而是对神经网络底层做一个基本的了解,为接下来的章节做准备。如果大家已经熟悉神经网络的基本知识,则可以跳到下一章,在那里我们将深入了解各种用于文本处理的神经网络。虽然反向传播(backpropagation)算法的数学基础知识超出了本书的范围,但熟练掌握其基本的工作原理将帮助我们理解语言及其背后隐藏的模式。提示
Manning出版社还出版了另外两本关于深度学习的重要著作: - Deep Learning with Python[1],François Chollet,由Keras作者撰写的关于深度学习的深入理解的书;
- Grokking Deep Learning,Andrew Trask,关于各种深度学习模型和实践的概述性的书。
5.1 神经网络的组成
随着近十年来计算能力和存储能力的爆炸式增长,一项旧技术又迎来了新的发展。在20世纪50年代,弗兰克·罗森布莱特(Frank Rosenblatt)首次提出了感知机算法[2],用于数据中的模式识别。
感知机的基本思路是简单地模仿活性神经元细胞的运行原理。当电信号通过树突(dendrite)进入细胞核(nucleus)时(如图5-1所示),会逐渐积聚电荷。达到一定电位后,细胞就会被激活,然后通过轴突(axon)发出电信号。然而,树突之间具有一定的差异性。由于细胞对通过某些特定树突的信号更敏感,因此在这些通路中激活轴突所需要的信号更少。
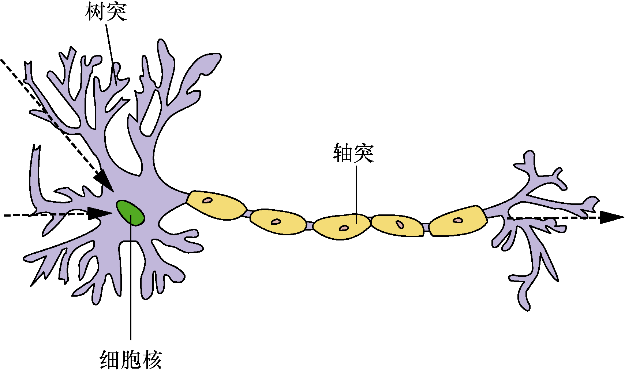
图5-1 神经元细胞
控制神经元运行的生物学知识毫无疑问超出了本书的范围,但是这里面有一个值得注意的关键概念,那就是决定细胞何时激活时细胞如何对输入信号进行加权。神经元会在其生命周期内的决策过程中动态调整这些权重。接下来我们将会模拟这个过程。5.1.1 感知机
罗森布莱特最初的项目是教会机器识别图像。最初的感知机是光接收器和电位器的集合体,而不是现代意义上的计算机。抛开具体的实现不谈,罗森布莱特的想法是取一幅图像的特征,并为每项特征赋予相应的权重,用于度量其重要性。输入图像的每项特征都是图像的一小部分。
通过将图像暴露给光接收器栅格,每个光接收器都会接收图像的一小部分。特定的光接收器所能接收的图像亮度将决定它发送给相关“树突”的信号强度。
每个树突都有一个电位器形式的权值。当输入信号足够强时,它就会把信号传递给“原子核”的主体“细胞”。一旦所有电位器发出的信号达到一定程度的阈值,感知机会激活轴突,表示当前展示的图像是正向匹配。如果对于给定的图像没有激活,那就是一个负向匹配。类似于识别一个图像是不是热狗或者是不是鸢尾花。5.1.2 数字感知机
到目前为止,大家可能已经有很多关于生物学、电流和光接收器方面的疑问。我们暂停一下,把神经元里最重要的概念抽离出来。
从本质上说,这个过程就是从数据集中选取一个样本(example),并将其展示给算法,然后让算法判断“是”或“不是”,这就是目前我们所做的事情。我们所需完成的第一步是确定样本的特征。选择适合的特征是机器学习中一个极具挑战性的部分。在“一般性”的机器学习问题中,如预测房价,特征可能是房屋面积(平方英尺)、最终售价和所在地区的邮政编码。或者,也许大家想用鸢尾花数据集[3]来预测某种花的种类,那样的话,特征就变成花瓣长度、花瓣宽度、萼片长度和萼片宽度。
在罗森布莱特的实验中,特征是每个像素(图像的子区域)的强度值,每个照片接收器接收一个像素。然后为每个特征分配权重。这里不用担心如何得到这些权重,只要把它们理解为能够输入神经元所需的信号强度值的百分比即可。如果大家熟悉线性回归,可能已经知道这些权重是如何得到的[4]。提示
一般而言,把单个特征表示为xi,其中i是整数。所有特征的集合表示为X,表示一个向量: 
类似地,每个特征的权重表示为wi,其中i对应于与该权重关联的特征x的下标,所有权重可统一表示为一个向量W:

有了这些特征,只需将每个特征(xi)乘以对应的权重(wi),然后将这些乘积求和:
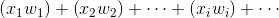
这里有一个缺少的部分是是否激活神经元的阈值。一旦加权和超过某个阈值,感知机就输出1,否则输出0。
我们可以使用一个简单的阶跃函数(在图5-2中标记为“激活函数”)来表示这个阈值。
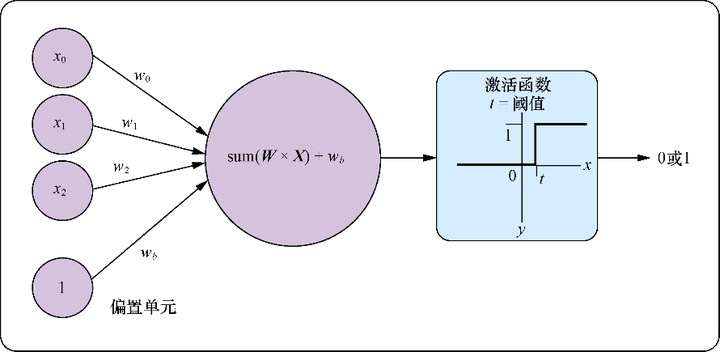
图5-2 基本的感知机5.1.3 认识偏置
图5-2的例子中提到了偏置。这到底是什么?实际上,偏置是神经元中常用的输入项。和其他输入元素一样,神经元会给偏置一个权重,该权重与其他权重用同样的方式来训练。在关于神经网络的各种文献中,偏置有两种表示形式。一种表示形式是将其表示为输入向量,例如对于n维向量的输入,在向量的开头或结尾处增加一个元素,构成一个n + 1维的向量。1的位置与网络无关,只要在所有样本中保持一致即可。另一种表示形式是,首先假定存在一个偏置项,将其独立于输入之外,其对应一个独立的权重,将该权重乘以1,然后与样本输入值及其相关权重的点积进行加和。这两者实际上是一样的,只不过分别是两种常见的表示形式而已。
设置偏置权重的原因是神经元需要对全0的输入具有弹性。网络需要学习在输入全为0的情况下输出仍然为0,但它可能做不到这一点。如果没有偏置项,神经元对初始或学习的任意权重都会输出0 × 权重 = 0。而有了偏置项之后,就不会有这个问题了。如果神经元需要学习输出0,在这种情况下,神经元可以学会减小与偏置相关的权重,使点积保持在阈值以下即可。
图5-3用可视化方法对生物的大脑神经元的信号与深度学习人工神经元的信号进行了类比,如果想要做更深入的了解,可以思考一下你是如何使用生物神经元来阅读本书并学习有关自然语言处理的深度学习知识的[5]。
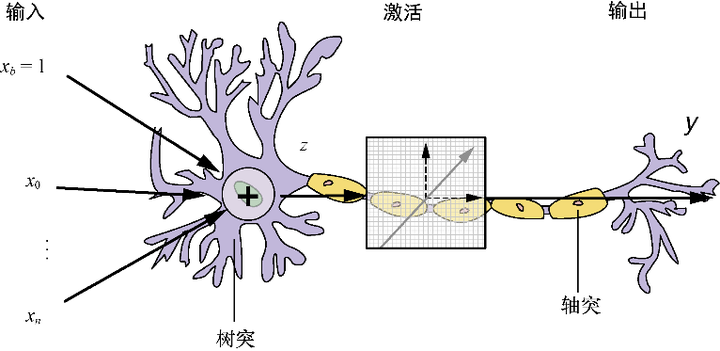
图5-3 感知机与生物神经元
用数学术语来说,感知机的输出表示为f (x),如下:
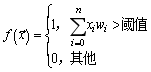
公式5-1 阈值激活函数提示
输入向量(X)与权重向量(W)两两相乘后的加和就是这两个向量的点积。这是线性代数在神经网络中最基础的应用,对神经网络的发展影响巨大。另外,通过现代计算机GPU对线性代数操作的性能优化来完成感知机的矩阵乘法运算,使得实现的神经网络变得极为高效。
此时的感知机并未学到任何东西,不过大家已经获得了非常重要的结果,我们已经向模型输入数据并且得到输出。当然这个输出可能是错误的,因为还没有告诉感知机如何获得权重,而这正是最有趣的地方所在。提示
所有神经网络的基本单位都是神经元,基本感知机是广义神经元的一个特例,从现在开始,我们将感知机称为一个神经元。 1.Python版神经元
在Python中,计算神经元的输出是很简单的。大家可以用numpy的dot函数将两个向量相乘:>>> import numpy as np>>> example_input = [1, .2, .1, .05, .2]>>> example_weights = [.2, .12, .4, .6, .90]>>> input_vector = np.array(example_input)>>> weights = np.array(example_weights)>>> bias_weight = .2>>> activation_level = np.dot(input_vector, weights) +\... (bias_weight * 1) ⇽--- 这里bias_weight * 1只是为了强调bias_weight和其他权重一样:权重与输入值相乘,区别只是bias_weight的输入特征值总是1>>> activation_level0.674
接下来,假设我们选择一个简单的阈值激活函数,并选择0.5作为阈值,结果如下:>>> threshold = 0.5>>> if activation_level >= threshold:... perceptron_output = 1... else:... perceptron_output = 0>>> perceptron_output)1
对于给定的输入样本example_input和权重,这个感知机将会输出1。如果有许多example_input向量,输出将会是一个标签集合,大家可以检查每次感知机的预测是否正确。2.课堂时间
大家已经构建了一个基于数据进行预测的方法,它为机器学习创造了条件。到目前为止,权重都作为任意值而被我们忽略了。实际上,它们是整个架构的关键,现在我们需要一种算法,基于给定样本的预测结果来调整权重值的大小。
感知机将权重的调整看成是给定输入下预测系统正确性的一个函数,从而学习这些权重。但是这一切从何开始呢?未经训练的神经元的权重一开始是随机的!通常是从正态分布中选取趋近于零的随机值。在前面的例子中,大家可以看到从零开始的权重(包括偏置权重)为何会导致输出全部为零。但是通过设置微小的变化,无须提供给神经元太多的能力,神经元便能以此为依据判断结果何时为对何时为错。
然后就可以开始学习过程了。通过向系统输入许多不同的样本,并根据神经元的输出是否是我们想要的结果来对权重进行微小的调整。当有足够的样本(且在正确的条件下),误差应该逐渐趋于零,系统就经过了学习。
其中最关键的一个诀窍是,每个权重都是根据它对结果误差的贡献程度来进行调整。权重越大(对结果影响越大),那么该权重对给定输入的感知机输出的正确性/错误性就负有越大的责任。
假设之前的输入example_input对应的结果是0:>>> expected_output = 0>>> new_weights = []>>> for i, x in enumerate(example_input):... new_weights.append(weights + (expected_output -\... perceptron_output) * x) ⇽--- 例如,在上述的第一次计算中,new_weight = 0.2 + (0 - 1) × 1 = −0.8 >>> weights = np.array(new_weights)>>> example_weights ⇽--- 初始权重[0.2, 0.12, 0.4, 0.6, 0.9]>>> weights ⇽--- 新的权重[-0.8 -0.08 0.3 0.55 0.7]
这个处理方法将同一份训练集反复输入网络中,在适当的情况下,即使是对于之前没见过的数据,感知机也能做出正确的预测。3.有趣的逻辑学习问题
上面使用了一些随机数字做例子。我们把这个方法应用到一个具体问题上,来看看如何通过仅向计算机展示一些标记样本来教它学会一个概念。
接下来,我们将让计算机理解逻辑或(OR)。如果一个表达式的一边或另一边为真(或两边都为真),则逻辑或语句的结果为真。这个逻辑非常简单。对于以下这个问题,我们可以手动构造所有可能的样本(在现实中很少出现这种情况),每个样本由两个信号组成,其中每个信号都为真(1)或假(0),如代码清单5-1所示。
代码清单5-1 逻辑或问题>>> sample_data = [[0, 0], # False, False... [0, 1], # False, True... [1, 0], # True, False... [1, 1]] # True, True>>> expected_results = [0, # (False OR False) gives False... 1, # (False OR True ) gives True... 1, # (True OR False) gives True... 1] # (True OR True ) gives True>>> activation_threshold = 0.5
我们需要一些工具,numpy可以用来做向量(数组)乘法,random用来初始化权重:>>> from random import random>>> import numpy as np>>> weights = np.random.random(2)/1000 # Small random float 0 < w < .001>>> weights[5.62332144e-04 7.69468028e-05]
这里还需要一个偏置:>>> bias_weight = np.random.random() / 1000>>> bias_weight0.0009984699077277136
然后将其传递到流水线中,计算得到4个样本的预测结果,如代码清单5-2所示。
代码清单5-2 感知机随机预测>>> for idx, sample in enumerate(sample_data):... input_vector = np.array(sample)... activation_level = np.dot(input_vector, weights) +\... (bias_weight * 1)... if activation_level > activation_threshold:... perceptron_output = 1... else:... perceptron_output = 0... print('Predicted {}'.format(perceptron_output))... print('Expected: {}'.format(expected_results[idx]))... print()Predicted 0Expected: 0Predicted 0Expected: 1Predicted 0Expected: 1Predicted 0Expected: 1
随机的权重值对这个神经元没有多大帮助,我们得到1个正确、3个错误的预测结果。接下来我们让网络继续学习,并在每次迭代中不只是打印1或0,而是同时更新权重值,如代码清单5-3所示。
代码清单5-3 感知机学习>>> for iteration_num in range(5):... correct_answers = 0... for idx, sample in enumerate(sample_data):... input_vector = np.array(sample)... weights = np.array(weights)... activation_level = np.dot(input_vector, weights) +\... (bias_weight * 1)... if activation_level > activation_threshold:... perceptron_output = 1... else:... perceptron_output = 0... if perceptron_output == expected_results[idx]:... correct_answers += 1... new_weights = []... for i, x in enumerate(sample): ⇽--- 这就是使用魔法的地方。当然还有一些更高效的方法来实现,不过我们还是通过循环来强调每个权重是由其输入(xi)更新的。如果输入数据很小或为零,则无论误差大小,该输入对该权重的影响都将会很小。相反,如果输入数据很大,则影响会很大... new_weights.append(weights + (expected_results[idx] -\... perceptron_output) * x)... bias_weight = bias_weight + ((expected_results[idx] -\... perceptron_output) * 1) ⇽--- 偏置权重也会随着输入一起更新... weights = np.array(new_weights)... print('{} correct answers out of 4, for iteration {}'\... .format(correct_answers, iteration_num))3 correct answers out of 4, for iteration 02 correct answers out of 4, for iteration 13 correct answers out of 4, for iteration 24 correct answers out of 4, for iteration 34 correct answers out of 4, for iteration 4
哈哈!这个感知机真是个好学生。通过内部循环更新权重,感知机从数据集中学习了经验。在第一次迭代后,它比随机猜测(正确率为1/4)多得到了两个正确结果(正确率为3/4)。
在第二次迭代中,它过度修正了权重(更改了太多),然后通过调整权重来回溯结果。当第四次迭代完成后,它已经完美地学习了这些关系。随后的迭代将不再更新网络,因为每个样本的误差为0,所以不会再对权重做调整。
这就是所谓的收敛。当一个模型的误差函数达到了最小值,或者稳定在一个值上,该模型就被称为收敛。有时候可能没有这么幸运。有时神经网络在寻找最优权值时不断波动以满足一批数据的相互关系,但无法收敛。在5.8节中,大家将看到目标函数(objective function)或损失函数(loss function)如何影响神经网络对最优权重的选择。
意犹未尽读这本书开始你的学习之旅吧!
自然语言处理实战 利用Python理解、分析和生成文本《自然语言处理实战 利用Python理解、分析和生成文本(异步图书出品)》([美]霍布森·莱恩,科尔·霍华德,汉纳斯·马克斯·哈普克)【摘要 书评 试读】- 京东图书​item.jd.com
发布于 2020-12-29
​赞同 4​​添加评论​分享
​收藏​喜欢​
收起​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

何史提
​
物理学等 3 个话题下的优秀答主
11 人赞同了该回答
看Coursera相关的课程,或参考:Manning and Shcutze, Foundations of Statistical Natural Language Processing
但更重要的还是实战经验!
发布于 2014-07-08
​赞同 11​​4 条评论​分享
​收藏​喜欢​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

片刻
专注于优秀项目维护的开源组织 apachecn.org
18 人赞同了该回答
高大上的大佬太多,我就给一份小白入门该学习的干货资料:
不废话,入门教程需看资料: nlp 入门须知的材料
编辑于 2019-10-09
​赞同 18​​添加评论​分享
​收藏​喜欢​
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

炼己者
计算机视觉学习分享!
16 人赞同了该回答

本身是学数据分析的,后来实习机缘巧合地去了自然语言处理方向。就在这里说一下我是如何入门自然语言处理的吧!
做这个方向,首先你得有编程基础,我觉得用python来做自然语言处理真的是很方便。学习python,你可以参考这篇文章
如何系统地自学 Python?​www.zhihu.com
学完python以后,你就可以找个项目来做了,项目我推荐做文本分类,就去做kaggle的情感分类吧!我实习的时候第一个项目就是做的文本分类,当时我只有python基础,会调用pandas,numpy以及sklearn库,懂一些机器学习算法原理。
现在假设你有python基础,那么该怎么操作呢? 1.入门阶段 1.入门阶段直接做文本分类这个项目,具体的思路很简单。把原始文本变成向量,然后调用sklearn库里的分类算法,就可以实现文本分类了!
如何把文本转换为文本向量呢?看这篇文章即可,手把手地教你把中文文本变成向量(附代码)
炼己者:中文文本预处理完整流程(附代码)​zhuanlan.zhihu.com
尽量地去理解代码,代码的实现思路,以后遇到类似问题能不能转换成相应的数据格式,继续用这些代码操作。
2.发展阶段完整的实现文本分类这个项目之后不要骄傲,以为自己很厉害了,可以纵横NLP界了。接下来你要开始有体系地去学习
我还是推荐视频为主,书籍为辅,毕竟我们是小白,直接看书会很容易放弃的。需要有好的e老师带我们飞!
第一个视频教程,宗成庆教授的视频教程,建议书和视频一起来。
书籍也是宗成庆教授的著作
第二个视频教程是炼数成金的教程,里面的课程目录是这样的
两个视频教程你可以网上搜索,也可以关注公众号:ZhangyhPico
回复关键字 自然语言处理入门 ,便可以领取资源
经典书籍我推荐《python自然语言处理》以及《数学之美》这两本书
《python自然语言处理》这本书很适合我们小白来读,作者感觉就是以我们小白的角度来写的。里面主要是处理英文数据的,你可以试着用书里的方法来操作中文数据,这样你会更好的落实和理解书中的代码。
《数学之美》这本书我感觉就是在说自然语言处理方向的技术原理,可以拿来做科普。比如你想做什么算法了,可以先拿这本书读一读,对你要用到的算法有个初步了解 
3.成长阶段
到了这个阶段你的理论知识基本完备,至少不那么迷茫了。接下来你可以开始做项目,读论文了。当然没事儿的时候还要多多翻阅这两本经典之作,基本做机器学习方向就不能忽略这两本书了。李航的《统计学习方法》,周志华的西瓜书《机器学习》。  1)项目 1)项目
做项目的话你肯定要有数据,中文的数据不好找,这里有一份关于中文数据的汇总,可以参考一下。
中文文本语料库整理(不定时更新2015-10-24).md​www.jianshu.com
项目有很多,比如命名实体识别,实体关系抽取,知识图谱等等。
命名实体识别系列你可以参考这里的博客操作
炼己者:中文命名实体识别​zhuanlan.zhihu.com
知识图谱这个项目很大,要做的东西很多。你可以先把理论知识备好,再去操作
理论知识依旧建议看视频,视频教程是小象学院的。可以关注公众号:ZhangyhPico
,回复关键字知识图谱,即可领取视频教程2)论文
自然语言处理方向的论文资料可以看这篇博客,里面会教你怎么找论文初学者如何查阅自然语言处理(NLP)领域学术资料 ​www.jianshu.com
到了这里,入门是肯定入门了,后续发展就看你自己了。没事儿读读论文,做做比赛,悠哉游哉!!!
|
|


 IP卡
IP卡 狗仔卡
狗仔卡 发表于 2021-1-19 14:01:16
发表于 2021-1-19 14:01:16
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡